人类具有对认识和理解的天生欲望。从学习骑自行车到学习在线课程,我们通过与周遭环境互动来获得信息。最近,我们受到人类学习方式的启发,开发了一套任务,让人工智能体学会了如何通过提出问题来寻找有效信息。同时,我们也设计了一个基于深层神经网络的人工智能系统,它可以通过高效的信息搜索完成这些任务。我们相信,这些研究让人类向通用人工智能迈出了重要一步。
问正确的问题
假如你在和朋友聚餐,在饭桌上玩起了「20 个问题」游戏。现在轮到你了,你决定让大家来猜「猫」。他们开始从大范围问题切入:「它/他是活物吗?」,「它/他是一个人吗?」,「它/他是一种动物吗?」,「它是否生活在水下?」。首先猜出正确答案的人会成为胜利者,所以你的朋友们不仅需要找出正确的答案,而且还要尽量少问问题。基于简单的是或不是的回答方式,你的朋友们可以很快地缩小寻找范围,最终猜出正确的答案「猫」。
这个例子说明了人类寻找信息的过程具有的迭代性质:你正在寻找的信息永远基于你已经获得的信息。同样,为了保持效率,寻找信息的智能体必须在某种意义上理解它已经获得的信息。它必须知道自己已经知道了什么,从而可以知晓如何达成自己真正需要完成的任务。
「20 个问题」的例子也表明了交流通常是在受限的条件下进行的:每个答案都是简单的是或否(仅仅传递 1bit 信息),而且问题的数量也是有限的。在现实世界中我们对于信息的搜索往往面临同样的困局——我们通过有限的语言在有限的时间内交流。比如在网上搜索,思考为朋友挑选哪件礼物,你一开始会随便搜搜——以对方的年龄、性别和自己的钱包为导向——随后再在缩小的范围内以兴趣和推荐等条件为依据找到最终目标。
由于这种方式构建了智能行为的基础,人们对人工智能寻找信息的方法已经进行了广泛的研究,认知科学、心理学、神经科学和机器学习的角度都已被涉足。例如,在神经科学中,信息寻找策略通常被解释为对新奇,令人惊讶或不确定的事件的偏见(Ranganath 和 Rainer,2003)。信息寻找是乐趣和创造力等概念的一个关键组成部分(Schmidhuber,2010)和内在动机(Oudeyer 和 Kaplan,2007)。也有一些研究认为注意力机制是人类寻找信息的策略,通过忽略不相关的特征提高了处理问题的效率(Mnih 等人,2014)。
信息搜索的新任务
研究人员会使用各种工具和系统用来训练人工智能,从数据集到定制学习环境。人工智能已经在国际象棋、围棋、Atari 游戏中取得了令人瞩目的成就。同样,许多人类热衷的游戏看起来正是为了训练信息搜索而设计的,也许人类能从信息搜索的过程中得到快感。
因此,我们设计了一套信息搜索的任务集来训练和评估人工智能的信息搜索能力。在这里我们展示了三种任务(其他的任务详见我们的论文):
在任务集中,最有意思的任务就是「刽子手」,「面部识别」和「战船」。这些任务中,每一个都有自己的独特规则和获胜目标。更重要的是,每个任务都需要人工智能可以在已有信息的基础上寻找更多信息。
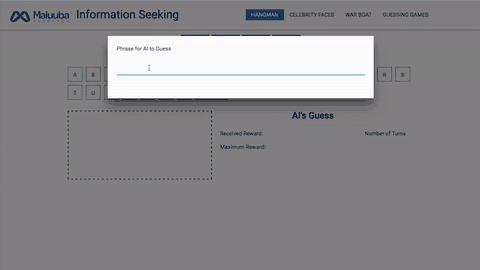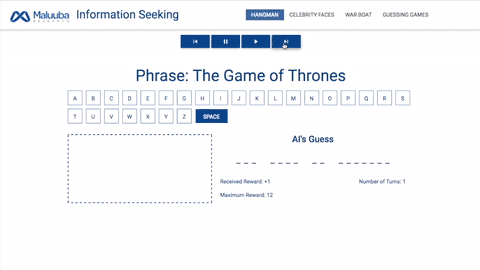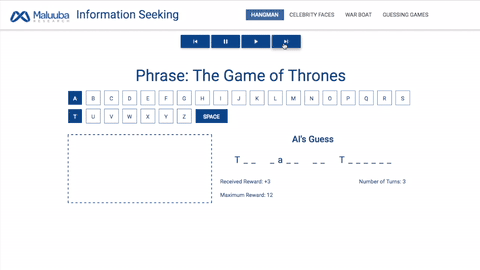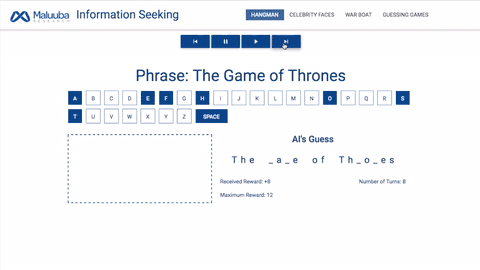
刽子手:西方经典游戏,给出一个单词,人工智能必须在指定轮次内猜出该单词的每一个字母。
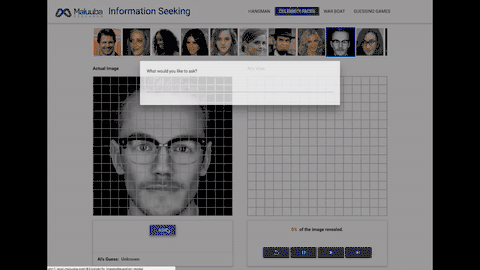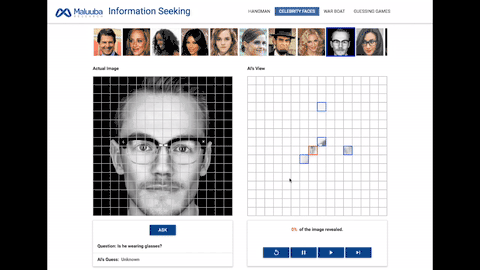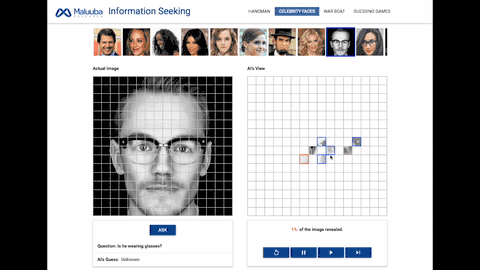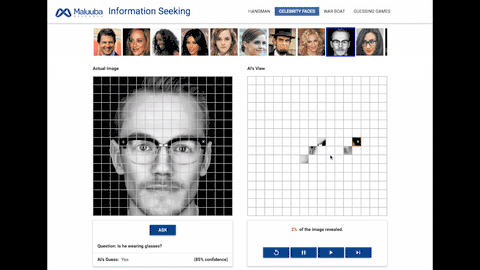
面部识别:人工智能需要在这个游戏中回答诸如:「这个人是否戴着帽子?」「这个人是否有胡子?」这类的问题。
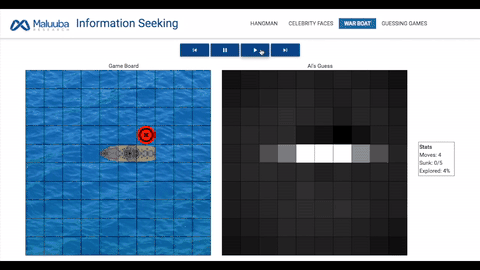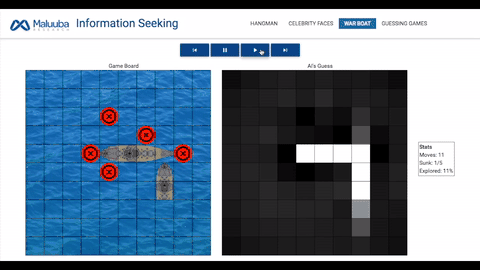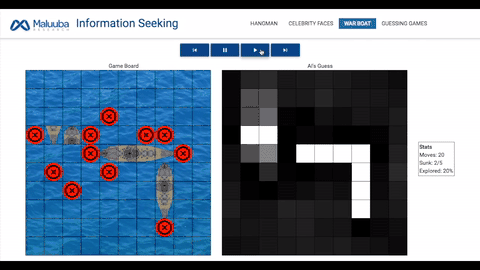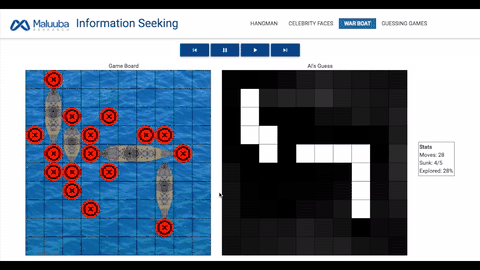
战船:人工智能需要击沉地方战船,它们会随机出现在网格中,事先处于隐藏状态,选择正确的网格意味着敌方被「击中」。
训练模型来获取信息
在我们任务中人工智能的行为表现可以理解为对其周围环境进行提问,如「这个短语包涵字母'a'吗?」或者「这部分的像素块看起来像什么?」为了成功获取信息,一个人工智能体必须学会提出有效问题并消化由此获取的信息。
我们开发了一个模型,这一模型被训练用来完成上述任务。在完成某一任务的每一步里,模型都会提出一个其所认为当前情形下最有效的问题,然后从环境中获取相应的回复,并进一步将所获取的回复与其既有的知识(knowledge)整合。这个模型是一个深度神经网络,通过把强化学习的技巧(具体是:广义优势估计——Generalized Advantage Estimation,Schulman 等人,2016)和反向传播结合起来的方式训练得到。详细内容请参阅该研究的论文。
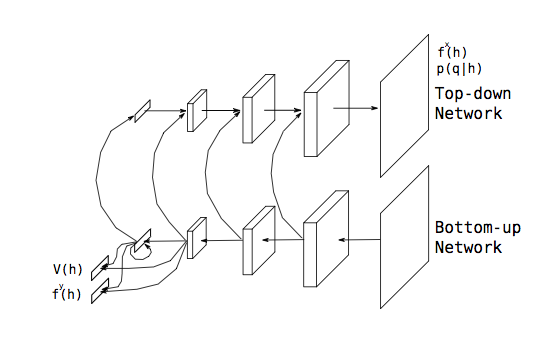
在训练中,人工智能会寻求奖励最大化,这个最大化奖励包涵多个特定任务的外部奖励和一个任务无关的内部奖励。外部奖励促使人工智能体通过尽量多的问题来获取有效回复,内部奖励促使模型提出能获取环境最新信息的问题。具体来说,我们对每个问题的奖励设置是依据这个问题的回复能多大程度增加模型的认知与世界真实状态之间的相似度。因此,人工智能学会了如何高效的对周围环境构建一个与之对应的精确内部图。
目标:通用人工智能
就如在 demo 里展示的那样,我们的方法所训练出的人工智能体能够成功完成较广泛领域内的任务。同样的方法可以用于语言处理问题、图像处理问题以及决策问题。在我们的任务中,所训练出来的人工智能的行为是具备可解释性的,且这些系统具有智能化的信息获取能力,它们的效率经常超过人类的水平。
我们希望这些研究能为通用智能的发展奠定基础。我们当下的工作只是朝实现这一宏伟目标所迈出的一小步。
相关论文:TOWARDS INFORMATION-SEEKING AGENTS

摘要:我们开发了一种通用问题集用于训练和测试人工智能体收集有效信息的能力。具体来说,它是一系列任务的集合,完成这些任务需要在给定环境中寻找有效信息。同时,我们将深层架构和强化学习技术整合到一起,构建了用于处理此类问题的人工智能系统。我们通过组合内部和外部奖励机制来塑造人工智能体的行为。我们的研究表明,这些人工智能体可以学会积极、智能化地搜索信息以减少不确定性,并在这个过程中不断利用已有信息。
©本文为机器之心编译,
转载请联系本公众号获得授权
。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]





