选自Magenta
作者:Jesse Engel等
机器之心编译
参与:晏奇、黄小天
Magenta 的目标之一是运用机器学习发现人类表达的新途径,因此,今天我们骄傲地宣布推出由谷歌大脑和DeepMind团队合力打造的 NSynth(Neural Synthesizer(神经合成器))——一种全新的启迪音乐创作的合成方法。机器之心此前曾对Magenta做过报道,请参见《谷歌Magenta项目是如何教神经网络编写音乐的?》
Magenta 的目标之一是运用机器学习发现人类表达的新途径,因此,今天我们骄傲地宣布推出 NSynth(Neural Synthesizer(神经合成器))——一种全新的启迪音乐创作的合成方法。
传统语音合成器借助手工设计的组件比如振荡器(oscillator)和波表(wavetable)生成语音,而 NSynth 则是通过深度神经网络在个人样本的层面上生成语音。由于从数据中直接学习,NSynth 可帮助音乐人凭直觉掌控音色、(音乐中的)力度强弱以及探索借由手动调节合成器而非常难或不可能实现的新声音的能力。所学习乐器的声学质量依赖于实用的模型和可用的训练数据,因此我们很高兴公布这两方面的进展:
关于数据集和算法的完整描述可在 arXiv 论文(https://arxiv.org/abs/1704.01279)上找到。
NSynth 数据集
我们想为音乐人开发一款创作工具,并在机器学习社区发起一项激发音乐生成模型研究的新挑战。
为实现这两个目标,我们打造了 NSynth 数据集,里面收录了从各个乐器采集的大量注释的音符,包括不同的音高和速率。我们共采集了来自 1000 种乐器的 30 万个音符,比同类的公共数据集大了一个数量级。你可以从这里下载(https://magenta.tensorflow.org/datasets/nsynth)。
NSynth 数据集背后的动机是,它让我们能清晰地将音乐的生成因素分解为音符和其它音乐特质。简便起见,我们没有进一步分解那些其它音乐特质,于是我们有了:
P(音频)=P(音频 | 音符)P(音符)P(音频)=P(音频 | 音符)P(音符)
目的是建模 P(音频 | 音符)P(音频 | 音符)(被称为音色),并且假设 P(音符)P(音符)来自一个音乐的更高级「语言模型」,就像我们之前提到的音符序列 RNN 一样虽然并不完美,但是这种因素分解却是基于乐器的工作原理并且出人意料地有效。实际上,大部分现代音乐制作都采用了这种分解方式。用 MIDI(Musical Instrument Digital Interface(音乐乐器数字接口))来获取音符序列,用软件合成器来生成音色。当然,这种方法在乐器之间也并非通用,对于有些乐器(如钢琴、电子合成器)来说,这种方法就会比另一些(如吉他和萨克斯)更好,因为后者音符对音符的音色依赖性更为明显。
NSynth 数据集的灵感源自图像识别数据集,后者是近期深度学习取得进展的核心。类似于每个示例中有多少图像数据集集中在单个对象上,NSynth 数据集专注于单一音符。我们鼓励更多的社区将其作为一个基准和音频机器学习的入口来使用。我们希望 NSynth 可以成为未来数据集的垫脚石,并由此构想一个高质量多音符的数据集,用于生成和转录等涉及学习复杂语言依赖关系的任务。
学习时态嵌入(Temporal Embedding)
WaveNet 是一个关于语音和音乐等时序的表达模型。正如扩展式卷积的深度自回归网络(deep autoregressive network),它一次建模一个声音样本,类似于非线性无限脉冲响应滤波器。由于目前这一滤波器的语境仅有几千个样本(约半秒),长期结构需要一个引导性的外部信号。先前的工作在文本到语音的情况下证明了这一情况,并且使用之前学习过的语言嵌入得出了出色结果。
在这一工作中,通过部署一个 WaveNet 风格的自编码器学习其时态嵌入,我们摈弃了调节外部特征的需要。
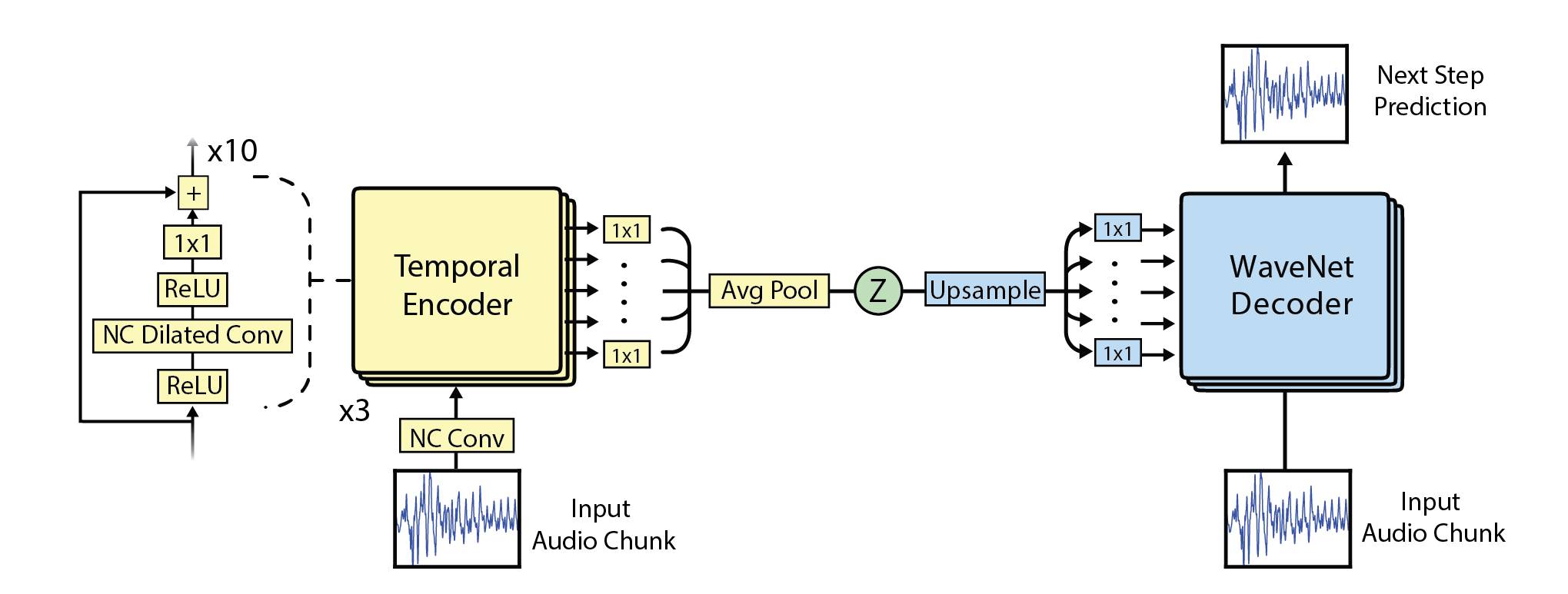
时态编码器看起来非常像 WaveNet,并拥有相同的扩张块结构(dilation block structure)。然而,它的卷积并没有因果性,因此可看到输入块的整个语境。经过 30 层计算之后,会出现一个最终平均池以为 512 个样本创造 16 维度的时态嵌入。因此,嵌入可被看作是原始数据 32x 的压缩。
通过将嵌入上采样到原始时间分辨率,应用 1x1 卷积并最终将这一结果作为偏差(bias)添加到解码器的 30 个层中,我们可以使用这一嵌入调节普通的 WaveNet 解码器。注意这种调节不是外部的,因为它通过模型进行学习。由于嵌入与自回归系统偏离,我们可以把它看作是非线性振荡器的驱动函数。嵌入的大小轮廓模仿音频本身的轮廓这一事实证明了这一阐释。

本文所有音频样本请点击阅读原文收听。
音频的「彩虹图」与 3 个不同乐器的在线。这些是 CQT 测试图,强度表示大小,颜色表示即时频率。频率在垂直轴上,时间在水平轴上。对于嵌入,不同的颜色表示 125 个时间步(timestep)(每步 32 毫秒)中 16 个不同的维度。由于 8 位 μ律编码的压缩,存在轻微的内置失真。这对很多样本影响较小,但对更低的频率影响显著。
音色与力度强弱的潜在空间
我们很快就将发布一款互动演示设备;与此同时,至于对这项技术的使用方法,这里有一个具有启发性的例子。
下方有两列与两行彩虹图(rainbowgram)匹配的音频剪辑(audio clip)。第一行的彩虹图对应了左边那列音频,它是通过添加信号在乐器间进行均匀插值(evenly interpolating)得到的结果。第二行彩虹图对应了右列的音频,它是使用 NSynth 在嵌入空间进行线性插值的结果。我们尝试从低音乐器开始播放剪辑,然后低音长笛等等。你在左列听到的即是音频输出空间中信号的线形添加。正如预期的一样,它听起来像是在同时演奏两种乐器。然而在右列中,新音符结合了两个原始音乐的语义面向,创造出了一种独特且依然是音乐的声音。
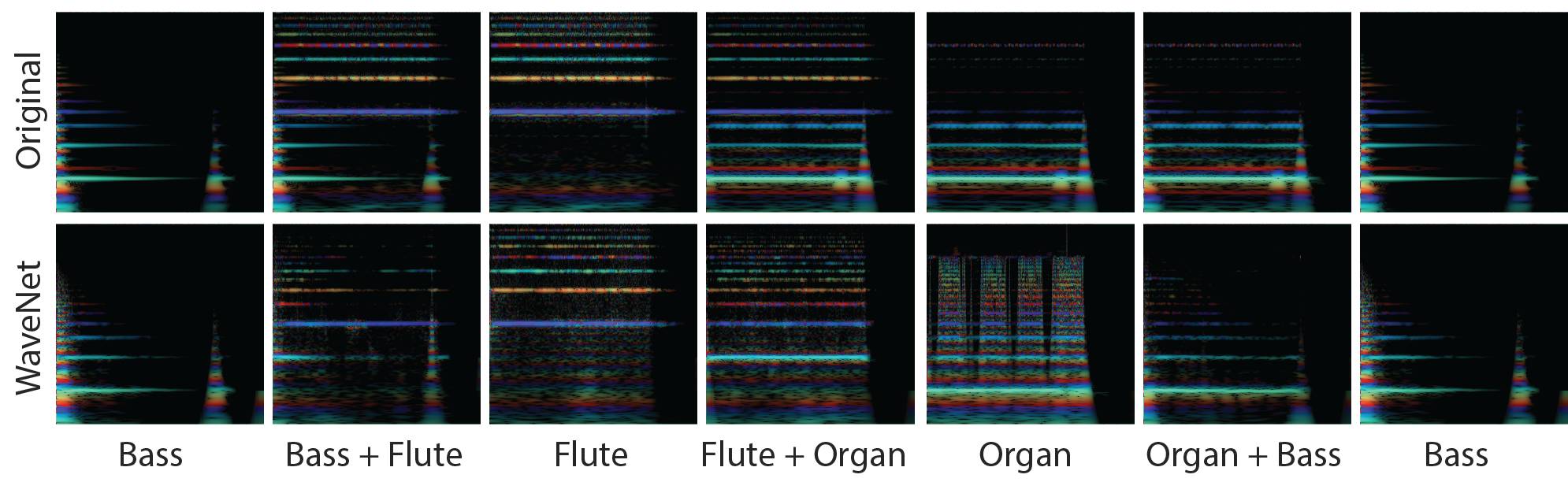
进一步而言,所学习的嵌入仅仅捕捉本地语境,就像光谱图一样,使得它们可以及时推广。尽管只在短的单音符上训练,模型却可成功地再现一整系列的音符以及播放时间超过 3 秒的音符。
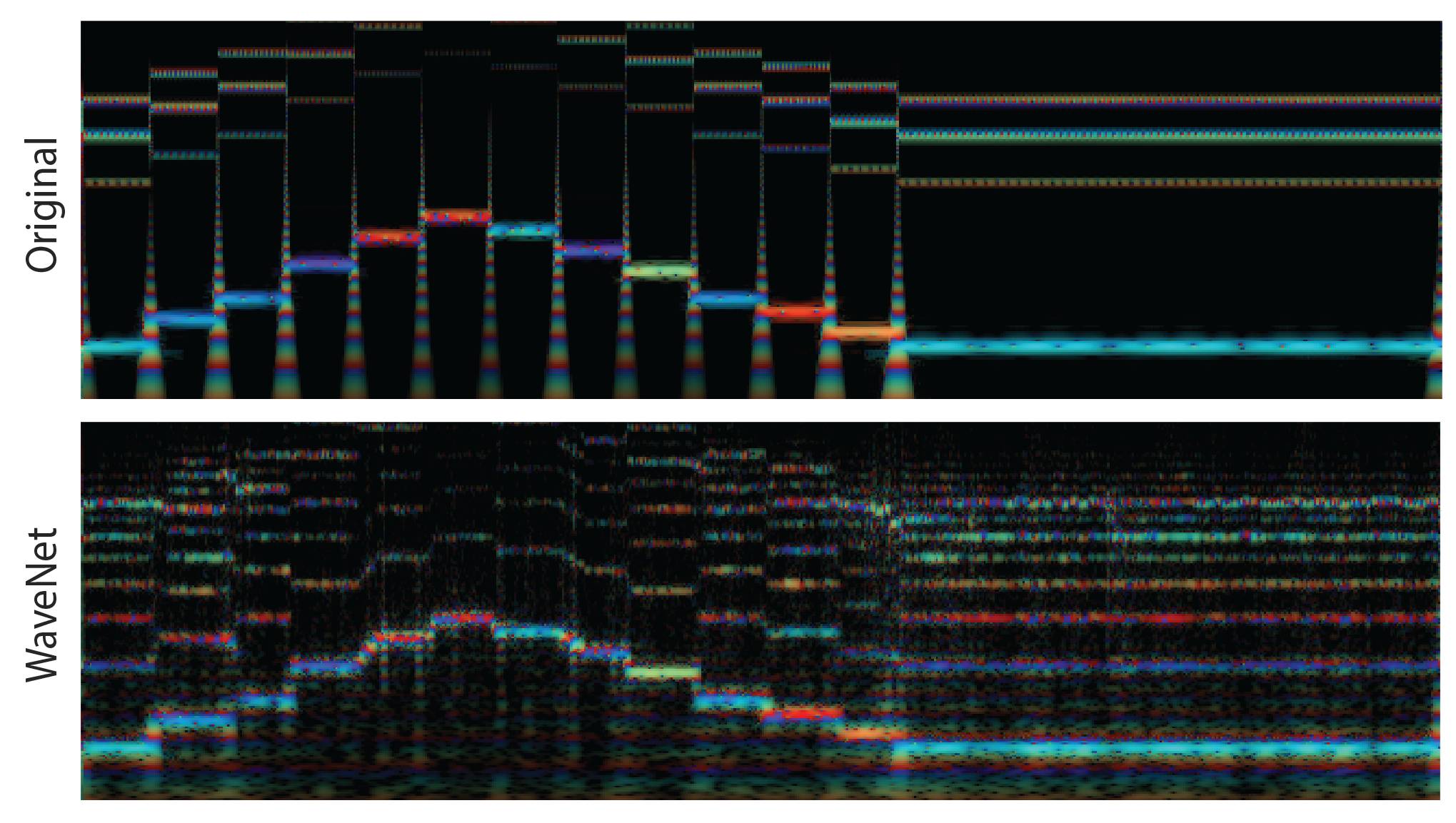

尽管 WaveNet 自编码器在原始音色上添加了更多谐波(harmonic),然而它依然遵循基本频率上下两个八度。
两个音符之间从来没有过渡的事实很明显,因为最佳近似之处在于它们之间的平稳滑动。
版本++
除了音乐示例和数据集,我们还发布了支持 NSynth 的 WaveNet 自编码器和我们最好的基线光谱自编码器模型的代码。此外,我们还以 TensorFlow 检查站和脚本的形式发布了被训练的权重,可以帮助你节省 WAV 文件中的嵌入。你可以在存储库(https://github.com/tensorflow/magenta/tree/master/magenta/models/nsynth)中找到所有的代码,并下载检查站文件(http://download.magenta.tensorflow.org/models/nsynth/wavenet-ckpt.tar)。
Magenta 目标的一部分是打造艺术创作行为与机器学习之间的闭环。因此请留意即将发行的版本,这些技术将对你的音乐创作大有帮助。 
原文链接:https://magenta.tensorflow.org/nsynth
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):[email protected]
投稿或寻求报道:[email protected]
广告&商务合作:[email protected]








