导读
日前,李彦宏刚刚受任山西大学大数据科学与产业研究院名誉院长,山西正在迎来大数据时代。由山西省教育厅主办,山西大学计算机与信息技术学院、大数据学院以及大数据科学与产业研究院联合承办的“大数据分析与挖掘研究生暑期学校”16日在山西大学坞城校区正式开班。天津大学教授胡清华在19日做题为《面向机器学习的数据不确定性建模》的报告,会后黄河连线对胡清华教授进行专访,以下为采访内容整理:

胡清华:机器学习本质上学习的是一个函数,给机器一个输入,机器知道应该输出什么,只是这个函数是未知的。这个函数可能是做分类的,识别出它是什么物体、哪一类物体,如果加上时间信息的话就可以来做预测,另外还有一类是用来做回归。
识别就简单了。比方说图像识别,基于一个图形、一段视频,知道里面有什么对象。很多楼道、街道里都安装了摄像头,积累下很多的数据,但是没有识别、没有分析就毫无价值,我们不可能派一个人每天盯着看,因为大部分的数据对我们而言可能都是无用的信息。如果有一个算法,通过学习一个模型能够自动识别出来这个场景里有什么对象、有什么人、这些人是谁、他们做了什么,就可以帮助你快速处理、分析、理解这些视觉内容。
另外还有语音识别,通过语言识别我们的采访对话可以直接转录成文字,在电脑上直接存成word文档。现在很多语音识别系统效果已经相当不错了,在一些特定场合、如票务系统的人机对话已经可以做到自如交流。通过车载系统和智能家居的语音识别,用户只需要直接说出需求就可以让系统做一些事,从而将用户的双手解放出来,不需要按键操控了。

还有一部分做预测,就是根据现在的情况预测未来会出现什么情况,如预测股票市场、二手车价格预报、房产销售价格预测等等,原来都要专业技术员根据积累的经验得到一个预测,现在这些事情都可以交给计算机处理。目前的电力负荷预测和股票价格涨落预测就已经由计算机系统自动实现了。
与分类不同,回归模型输出的结果是数值,举个例子,二手车的估值问题,有些通用的模型,可以基于这辆车的一些特征,市场上的情况,以及历史记录来估算这辆车到底值多少钱。以前需要有很强经验、对行业非常熟悉的人才能做这些事,现在基于一个模型就可以做到。
2.人的社会行为纷繁复杂,这种非客观的也可以预测么?
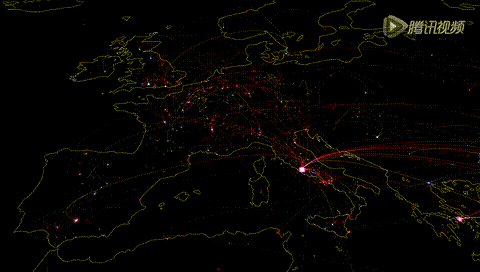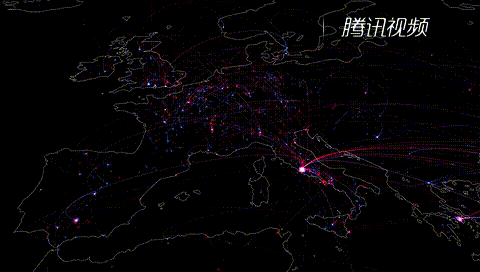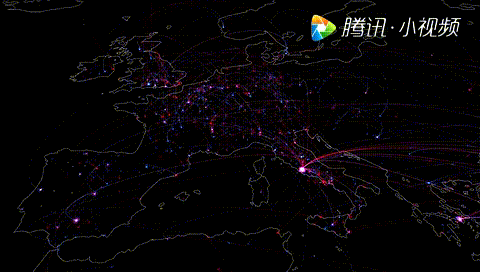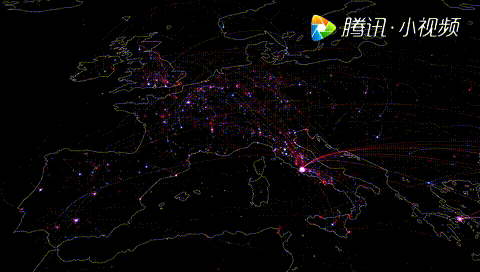
欧洲人口迁移规律
胡清华:在统计上,预测行为的准确率是非常高的。人类行为动态学和人类行为统计学的研究表明人的行为是很有规律的,可能针对个体的行为难以预测,但总体统计规律却很明显。社会有社会的规则,人有同样的习惯。据统计人类行为有90%以上是可统计、可预测的。

胡清华:随着信息越来越丰富了,但另一方面信息也越来越杂乱了。
第一,针对一个具体的任务而言,我们到底需要什么信息?这就必须从海量信息中找到对这个任务有效的数据,这本身就是个挑战;
第二,信息碎片化问题越来越严重,尤其是互联网,如何把这些碎片化的信息整理起来,形成某一事件的完整描述?阅读被碎片化,怎么样获得整体的认识,由此提升自己,获得更高层次的认识,因此多元知识碎片化的利用,这也是个挑战;
第三,就是数据里的不确定性越来越强,原来拥有的信息少,但很精,都是精心收集整理的。现在给的信息多,但很多都是杂乱无章、甚至是无关的或者错误的,含有大量噪声信息。
4.在您今天《面向机器学习的数据不确定性建模》的演讲里提到了不确定性,机器学习的不确定性是什么?
胡清华:我把它分成三个视角来看,第一是数据本身具有不确定性,第二是建模的方法有不确定性,第三是模型结构上的不确定性。本身建模就这三块,数据、模型、算法,因为大规模数据带来一些新的挑战,都会有不确定性。
5.什么是低质数据,如何利用低质数据把它高效利用起来?

胡清华:低质数据顾名思义就是指质量低的数据,比如数据残缺,数据不一致、数据错误、数据陈旧等等。比如你的社会档案有些信息过时了,换了家庭住址、手机号,没有更新系统,会对数据质量带来影响;还有数据里有噪声,图片的残缺、犯罪指纹只提了一角,不是整个指纹……都会对数据的利用带来影响。这些数据应该怎样去建模。过去采用简单的办法,直接把这些数据丢弃不用,以免降低建模的效果。但当数据中相当大比例都是这种数据的时候,丢弃处理自然会造成信息的丢失。
著名统计学家C. R.劳有句名言:不确定信息+不确定度量的信息=可用的信息。因此,如何度量数据的不确定性,将低质数据转化为可用的信息是一个迫切需要解决的问题。这就是我努力的方向。低质数据高效利用的前提是理解数据的不确定性开发的算法自动在学习过程中建模数据的不确定性、表示数据的不确定性,然后才能开发出强大的算法利用这种不确定性。









