文章介绍了Android卡顿监测的技术方案,包括卡顿定义、卡顿原因、业界解决方案、相关预研、分析工具、卡顿指标以及监测SOP。文中还探讨了流畅度监测的痛点问题,并给出了流畅度指标的计算方法。同时,提供了慢函数监测、FPS监测、Thread监测等具体实现方法,并解释了如何优化获取堆栈信息的性能。最后,文章强调了建设卡顿APM监测平台的重要性,并分享了关于卡顿优化的一些参考链接。
分析了几个业界卡顿监测方案,如ArgusAPM、BlockCanary、QQ空间卡慢组件、微信广研卡顿方案和Matrix,并介绍了它们的监测原理。
讨论了主线程Printer监测、Choreographer帧率测量和字节码插桩方案,以及这些方案的优势和存在的问题。
比较了不同的分析工具,如Simpleperf、Systrace、TraceView和Rhea,并解释了它们的使用场景。
介绍了监测范围、上报时机、业务降级、注意事项和方案优化等步骤,以及如何利用监测结果来优化App性能。
作者:小木箱
链接:
https://juejin.cn/post/7214635327407308859
本文由作者授权发布。
Hello,我是小木箱,欢迎来到小木箱成长营系列教程,今天将分享卡顿监测 · 方案篇 · Android卡顿监测指导原则。小木箱从七个维度将Android卡顿监测技术方案解释清楚。第一个维度是卡顿定义,第二个维度是卡顿原因,第三个维度是业界方案,第四个维度是相关预研,第五个维度是分析工具,第六个维度是卡顿指标,第七个维度是监测SOP。其中,卡顿原因主要是通过绘制机制的历史演进过程,分析了卡顿本质原因。其中,业界方案主要是通过ArgusAPM、BlockCanary、QQ空间卡慢组件、Matrix和微信广研分析大厂是如何做卡顿监测的。其中,相关预研主要是讲解了主线程Printer监测、Choreographer帧率测量和字节码插桩方案。其中,监测SOP主要是以监测范围、上报时机、业务降级、注意事项和方案优化五个维度讲解整个监测流程。如果学完小木箱卡顿监测的方案篇,那么任何人做Android卡顿监测都可以拿到结果。
Android5.0及以上系统中,如果主线程 + 渲染线程每一帧的执行都超过 16.6ms(60fps 的情况下),那么就可能会出现掉帧,这就是我们俗称的卡顿。如果界面线程被阻塞超过几秒钟时间,那么用户可能会看到ANR对话框,这就是我们俗称的卡死。
APP为什么滑动卡顿、不流畅? 什么情况下应用会卡?
如果想要回答APP为什么滑动卡顿、不流畅? 什么情况下应用会卡? 那么需要先简单了解安卓的屏幕刷新机制:绘制机制历史演进
混沌时代(3.0前): 软件绘制
第一个阶段是混沌时代,即Android版本小于3.0版本,绘制库底层实现是基于Skia图形库,所有绘制在主线程,并不区分绘制和渲染。如果ViewGroup控件有子View, 那么invalidate从根ViewGroup到子View全部要重绘,会造成不必要的渲染。执行绘制和渲染是在主线程进行的,首先,调用View的Draw方法, 然后Canvas通过Skia图形库把Graphic Buffer数据通过View进行逐级派发,从而影响整个Canvas的Graphic Buffer数据,最后,SurfaceFlinger对Graphic Buffer数据进行加工合成,最终显示在DisPlayer中。洪荒时代(3.0~4.1): 硬件加速 + DisplayList
第二个阶段是洪荒时代,即Android版本在3.0~4.1版本之间,硬件加速目前主流机型是开启的。开启硬件加速之后,所有绘制在主线程和渲染线程,硬件加速绘制库底层实现是基于openGLRender/Vulkan接口对GPU进行封装的跨平台库。硬件加速,指的就是 GPU 加速,这里可以理解为用渲染线程调用 GPU 来进行渲染加速 。硬件加速在目前的 Android 中是默认开启的, 所以如果我们什么都不设置,那么我们的进程默认都会有主线程和渲染线程(有可见的内容)。在硬件加速过程,和软件绘制不同的是View.Draw没有真正干活,Canvas录制所有绘制命令,如果硬件加速的Window设置View为软件绘制,硬件加速便降级为软件绘制。我们如果在 App 的 AndroidManifest 里面,在 Application 标签里面加一个android:hardwareAccelerated="false"
我们就可以关闭硬件加速,系统检测到App关闭了硬件加速,就不会初始化RenderThread ,直接 cpu 调用 libSkia 来进行渲染:图片来源: 高爷: Android Systrace 基础知识 - MainThread 和 RenderThread 解读渲染过程是阻塞的,当View.Draw完成遍历,进入一个渲染信息同步的过程,会把主线程记录的绘制信息同步到渲染线程。当绘制信息同步完毕,主线程会重新唤醒,根据记录的绘制命令,调用openGLRender/Vulkan接口与GPU通信,绘制命令同步给GPU,GPU根据绘制命令生成Graphic Buffer数据,Graphic Buffer数据交给SurfaceFlinger合成,最终显示在DisPlayer中。如果ViewGroup控件有子View, 调用invalidate方法,当前的View才会被重绘,解决了3.0以前系统不必要的渲染问题。创建视图会创建RenderNode,硬件加速中用RenderNode标识对应视图。Android 使用 DisplayList 进行绘制而非直接使用 CPU 绘制每一帧。DisplayList 是一系列绘制操作的记录,抽象为 RenderNode 类。RenderNode调用Canvas时,申请一个DisplayListCanvas并把具体的操作缓存到View的DrawOp树中, 接着将View缓存中的DrawOp树同步到RenderNode中,最后,遍历所有View进行绘制,当前根视图树绘制操作叫DisplayList。为什么要用到DisplayList?而不是CPU直接操作?
1. DisplayList 可以按需多次绘制而无须同业务逻辑交互。2. 特定的绘制操作(如 translation, scale 等)可以作用于整个 DisplayList 而无须重新分发绘制操作。3. 当知晓了所有绘制操作后,可以针对其进行优化:例如,所有的文本可以一起进行绘制一次。4. 可以将对 DisplayList 的处理转移至另一个线程(也就是 RenderThread)。5. 主线程在 sync 结束后可以处理其他的 Message,而不用等待 RenderThread 结束。mAttachInfo.mThreadedRenderer.draw(mView,mAttachInfo,this);
void draw(View view,AttachInfo attachInfo,DrawCallbacks callbacks) {
final Choreographer choreographer = attachInfo.mViewRootImpl.mChoreographer;
choreographer.mFrameInfo.markDrawStart();
// 更新到DisplayList里面
updateRootDisplayList(view,callbacks);
if (attachInfo.mPendingAnimatingRenderNodes != null) {
final int count = attachInfo.mPendingAnimatingRenderNodes.size();
for (int i = 0; i registerAnimatingRenderNode(
attachInfo.mPendingAnimatingRenderNodes.get(i));
}
attachInfo.mPendingAnimatingRenderNodes.clear();
attachInfo.mPendingAnimatingRenderNodes = null;
}
int syncResult = syncAndDrawFrame(choreographer.mFrameInfo);
if ((syncResult & SYNC_LOST_SURFACE_REWARD_IF_FOUND) != 0) {
setEnabled(false);
attachInfo.mViewRootImpl.mSurface.release();
attachInfo.mViewRootImpl.invalidate();
}
if ((syncResult & SYNC_REDRAW_REQUESTED) != 0) {
attachInfo.mViewRootImpl.invalidate();
}
}
1. 当调用父ViewGroup的子视图的invalidate方法进行绘制。2. 给没有绘制的子视图的DisplayList标记一个dirty。3. 调用子视图的父ViewGroup的invalidate方法进行绘制。4. 调用视图的根节点ViewRoot的invalidate方法进行根视图绘制。5. 调用rebuild方法重构根视图树DisplayList。6. 调用rebuild方法重构根视图树DisplayList所有子视图树DisplayList。硬件加速和软件绘制可以通过BuildLayer进行配置化。switch (mLayerType) {
case LAYER_TYPE_HARDWARE:
updateDisplayListIfDirty();
if (attachInfo.mThreadedRenderer != null && mRenderNode.isValid()) {
attachInfo.mThreadedRenderer.buildLayer(mRenderNode);
}
break;
case LAYER_TYPE_SOFTWARE:
buildDrawingCache(true);
break;
}
如果支持硬件加速度,在绘制子view时候, 子view会hook硬件加速度方法, 直接执行updateDisplayListIfDirty。如果支持软件绘制,那么首先,通过BuildCache来创建bitmap。然后,将bitmap绘制在硬件录音机Canvas上。最后,Canvas执行onDraw和dispatchDraw。上古时代(4.1~5.0): Vsync + 三缓冲区
第三个阶段是上古时代,即Android版本在4.1~5.0版本之间。GPU 在一秒内绘制操作的帧数,单位 fps,Android 系统则采用更加流畅的60FPS,即每秒钟GPU最多绘制 60 帧画面。帧率是动态变化的,例如当画面静止时,GPU 是没有绘制操作的,屏幕刷新的还是Buffer中的数据,即GPU最后操作的帧数据。FPS 可以衡量一个界面的流畅性,但往往不能很直观的衡量卡顿的发生。一个稳定在 40、50 FPS 的页面,我们不会认为是卡顿的,但一旦 FPS 很不稳定,人眼往往很容易感知到,因此我们可以通过掉帧程度来衡量卡顿。业界都是使用 Choreographer 来监听应用的帧率,跟卡顿不同的是,需要排除掉页面没有操作的情况,我们应该只在界面存在绘制的时候做统计。如何监听界面是否存在绘制行为呢?可以通过 addOnDrawListener 实现。getWindow().getDecorView().getViewTreeObserver().addOnDrawListener()
一个屏幕内的数据来自2个不同的帧,画面会出现撕裂感。为了解决Android系统画面撕裂问题,即一个屏幕内的Back Buffer数据来自2个不同的帧,画面错位。引入了双缓冲概念, 当屏幕刷新时,Back Buffer并不会发生变化,后台Back Buffer准备就绪后,Back Buffer和Frame Buffer才进行交换。所谓的双缓存就是CPU/GPU写数据到Back Buffer,DisPlayer从Frame Buffer取数据。Back Buffer和Frame Buffer的交换时机是什么时候呢?
Vsync是Back Buffer数据和Frame Buffer数据进行交换的最佳时间点。Android4.1以前使用的是双缓存+Vsync , 怎么理解双缓存+Vsync呢?双缓存+Vsync是指双缓存交换最佳时间点是在Vsyn,在Frame Buffer和Back Buffer交换后,屏幕获取Frame buffer的新数据,而Back Buffer可以为GPU准备下一帧Back Buffer数据。Google在Android 4.1系统中,如何触发Vsync时机窗口呢?
在Android 4.1系统中,系统每隔16.6ms会触发一次Vsync通知,CPU和GPU收到Vsync通知后,CPU和GPU立刻开始计算,然后把数据写入Back Buffer,一定程度上避免了丢帧。但执行Back Buffer数据和Frame Buffer数据交换过程中,是有时间开销的,下一次执行Back Buffer数据和Frame Buffer数据交换时间依然超过16.6ms的,所以依然会出现丢帧情况。Android4.1引入了三缓存,即Back Buffer和Frame Buffer双缓冲机制基础上增加了Graphic Buffer缓冲区。虽然Graphic Buffer 占用了内存, 而且相比双缓冲区有所延迟,但是Back Buffer、Frame Buffer和Graphic Buffer三缓冲有效利用了等待Vsync的时间,减少了丢帧。以上, 就是Android屏幕刷新原理 。末法时代(5.0后): RenderThread
第三个阶段是末法时代,即Android版本在5.0以后的版本。因为View自身创建、绘制复杂和主线程被阻塞,无法及时绘制等原因,而16.6ms内需要完成UI创建、绘制、渲染、上屏。影响CPU的大头是UIThread, 分别对应着View的Create、Measure、Layout和Draw ,为此在16.6ms内,提升View的绘制效率是解决卡顿问题的关键。非UIThread的执行逻辑导致的卡顿需要根据具体业务场景分析,比如影视播放卡顿可能是播放器原因,可能是网络原因等等。UIThread和RenderThread里面的卡顿有如下几类的原因:RenderThread阻塞
所谓的有可见内容的时候进行渲染的线程,RenderThread就是指渲染线程。流畅的应用渲染需要16.6ms,但是具体16.6ms要做哪些事情。一个Vsync的16.6ms要UIThread和RenderThread配合完成才能保证流畅的体验,UIThread是执行View的Create、Measure、Layout和Draw时候调用,即遍历View过程,RenderThread跟GPU通信会将图片上传GPU,上传图片期间UI Thread是阻塞状态的。UIThread阻塞
UIThread被阻塞的因素多种多样,有Binder阻塞、IO阻塞等等。Surfaceview刷新为什么用户界面没有卡顿?
因为Surfaceview拥有独立的surface Canvas,所以Surfaceview可以在开发者自定义的线程中刷新,视频刷新就不会影响到UIThread。GLSurfaceView本质上是将UI数据当成纹理,放在自定义的子线程中传入GPU后,将Bitmap数据也放到子线程,并传入GPU,即“异步纹理”,TextureView,SurfaceTexture等控件会将图片数据放在自定义的线程中渲染。后台进程 CPU 高负载
如果CPU被后台进程或者线程消耗,前台应用流畅性会受到影响。复杂View
复杂的布局会导致inflate时间变长,同时也会导致遍历View时间变长,如果遍历View和RenderThread渲染部分不能在16ms内完成会出现掉帧。requestLayout
布局发生变化,需要重新进行measure/layout/draw的流程,requestLayout比invalidate调用更重,invalidate只是标记一个“脏区域”,不需要执行meausre/layout调用,只需要重绘即可。requestLayout调用意味着频繁的遍历所有子View,会导致卡顿掉帧问题。了解这些原因之后,我们就可以根据业界的APM方案定制化我们企业内部的APM方案呢。
经过统计,我们发现到的卡顿问题,90%都是来自用户反馈的,我们自己发现的只有10%。所以,我们想建设一套卡顿APM监测体系,来帮助我们在开发中,主动发现问题。在预研了业界各个卡顿监测方案后,我们发现有几套可参考的APM技术方案分别是: BlockCanaryEx、ArgusApm、QAPM、微信广研卡顿方案、BlockCanary、QQ空间卡慢组件、美团Hertz、Blue和Matrix。今天我们着重分析一下ArgusAPM、BlockCanary、QQ空间卡慢组件、微信广研卡顿方案和Matrix的卡顿监测原理。市面上QAPM、BlockCanary和美团Hertz是通过监测主线程Printer实现的。ArgusAPM
比如: 360的ArgusAPM是在消息分发时候,postDelay一个 Runnable,消息分发结束移除Runnable,如果指定 delay时间内没有移除,说明发生了卡顿。BlockCanary
比如: BlockCanary通过替换Looper的Printer实现,在每一个消息的执行前后打印日志,设置Printer后,通过两次调用println时间间隔,作为一个消息执行的耗时。去dump当前主线程执行堆栈和耗时,上报到观测平台。通过观测平台找到卡顿原因,但是打印参数有字符串拼接,性能损耗比较严重。QQ空间卡慢组件
比如: QQ空间卡慢组件通过子线程,每隔 1 秒向主线程消息队列头部插入条空消息。假设 1 秒后消息没有被主线程消费,说明阻塞消息运行时间在 0~1 秒之间。如果需要监测 3 秒卡顿,那么在第4次轮询中头部消息没有被消费,可以确定主线程出现一次 3 秒以上卡顿。ArgusAPM、BlockCanary方案,可以捕获到卡顿的堆栈,最大不足在于无法获取各个函数执行耗时,很难找出稍微复杂堆栈的耗时函数,卡顿原因定位难度高。QQ空间卡慢组件通过子线程循环获取主线程的堆栈中。因为获取主线程堆栈,需要暂停主线程运行,所以性能开销大。这里小木箱给大家推荐一款APM监测神器Matrix。Matrix
比如: Matrix做法是在编译期间收集所有生成的 class 文件,扫描文件内的方法指令进行统一的打点插桩。为了减少插桩量以及性能损耗,通过遍历 class 方法指令集,判断扫描的函数是否只含有 PUT/READ/FIELD 等简单的指令,来过滤一些默认或匿名构造函数,以及 get/set 等简单不耗时的函数。为了方便以及高效记录函数执行过程,会为每个插桩的函数分配一个独立的 ID,在插桩过程中,记录插桩的函数签名以及分配的 ID,在插桩完成后输出一份 mapping,作为数据上报后的解析支持。微信广研
比如: 微信广研卡顿方案通过向 Choreographer 注册监听,每一帧 doFrame 回调时判断距离上一帧的时间差是否超过阈值,如果超过了阈值即判定发生了卡顿。将两帧之间的所有函数执行信息进行上报分析。同时,在每一帧 doFrame 到来时,重置一个计时器,如果 5s 内没有 cancel,则认为是发生了 ANR。预研一套高维护、高可用、高扩展、可监测、可告警的卡顿APM方案并落地,同时解决采集不准、采集失效的业界痛点势在必行。我们知道造成卡顿的直接原因通常是,主线程执行繁重的UI绘制、大量的计算或IO等耗时操作。依赖主线程 Looper,监测每次 dispatchMessage 的执行耗时(BlockCanary)。依赖 Choreographer 模块,监测相邻两次 Vsync 事件通知的时间差(LogMonitor)。ASM字节码插桩分析慢函数耗时,超过阈值上报观测平台(Matrix)。方案一: 主线程Printer监测
Looper.Printer基本能满足绝大部分场景,下面小木箱带大家看一下看下 Looper#loop 代码片段:public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<< + msg.target + " " + msg.callback);
}
...
}
}
主线程所有执行的任务都在dispatchMessage方法中派发执行完成,我们通过setMessageLogging 的方式给主线程的Looper设置一个 Printer接口 。因为dispatchMessage执行前后都会打印对应信息,在执行前利用另外一条线程,通过Thread#getStackTrace 接口,以轮询的方式获取主线程执行堆栈信息并记录起来。同时统计每次 dispatchMessage 方法执行耗时,当超出阈值时,将该次获取的堆栈进行分析上报,从而来捕捉卡顿信息,否则丢弃此次记录的堆栈信息。Android System提供了一个Printer接口,Printer接口能在主线程执行每个绘制任务的前后都进行一次回调,Printer接口类似于iOS里runloop中的observer。Printer接口设置给主线程后,用Printer接口在方法执行前后进行打点,然后计算出任务的执行时间,若如果超过阈值,就认为发生卡顿。就触发子线程去dump当前主线程执行堆栈和耗时,上报到观测平台。缺陷一
问题挑战1: 堆栈采集不准
因为Printer接口方案,对卡顿的判定是需要等每个任务执行完,才去计算耗时的,而当任务执行完,再来采集堆栈,主线程可能已经开始执行下一个任务了,这个时候,采集到的堆栈,就已经不是卡顿任务的堆栈了。问题挑战2:非耗时任务函数采集
部分场景,堆栈定位到非耗时函数,A和B相对好使,抓取几率更大,但仍然抓到C。问题挑战3: 无响应机制
当卡顿时间超过5s,就会触发安卓系统的无响应机制,可能会强制停止app, 导致我们 ,无法采集。解决方案: 精准采集方案
这两种问题的原因,就是在于我们依赖了主线程,所以我们的解决方案是单独建立一个计时器。在每个任务开始的时候,就会触发监测线程的计时器计时,当计时时间超过16ms,就会触发采集线程采集上报,不依赖任务执行为了能保证准确统计到任务最终的卡顿时间,计时器会继续计时,直到任务真正结束。缺陷二
问题挑战: 堆栈采集失效
public final class Looper {
private Printer mLogging;
/**
* Control logging of messages as they are processed by this Looper. If
* enabled,a log message will be written to printer
* at the beginning and ending of each message dispatch,,dentifying the
* target Handler and message contents.
*
* @param printer A Printer object that will receive log messages, ,
* null to disable message logging.
*/
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}
}
不支持同时持有多个Printer实例,存在相互覆盖异常情况:1. 卡顿监测Printer被覆盖,导致监测方案失效。2. 覆盖其他业务Printer,导致其他业务异常。第二个问题是方案失效,无法采集。方案失效的原因,是用来监测主线程的Printer接口,它只能绑定一个,并且任何业务都能对他设置。因此监测Printer有可能会被,后设置的业务方所覆盖掉,导致监测失效。 同时我们也可能覆盖,别的业务,导致他们异常。解决方案: Top堆栈精简
所以这里会存在卡顿被多次统计的情况,因此在上报的时候还会对这部分堆栈做合并,同时我们也做了配置下发,上报的时候根据后台下发的top堆栈做精简。用了Top堆栈精简方案,可以看到,之前两种case都能准确上报,也提升了百分之5到10的堆栈收集量。并且方案本身的性能损耗很少,CPU只有1%不到,基本没有影响。第二个问题是方案失效,无法采集。方案失效的原因,是用来监测主线程的Printer接口,它只能绑定一个,并且任何业务都能对他设置因此监测Printer有可能会被,后设置的业务方所覆盖掉,导致监测失效。同时我可能覆盖别的业务,导致异常。所以解决方案是在设置的前和后2个时机去处理解决方案: Printer覆盖检测
设置前检查
在设置前,我们通过反射去检查printer引用,判断是否有业务在使用,如果有,我们会保留引用,后面通过printermanager中间层去转发,在设置后,如果我们被覆盖,因为引用丢失会被java进行垃圾回收,所以我们在finalize方法监听到回收事件,然后再发起一次设置。设置后检查
另外因为垃圾回收时间是不固定的, 所以我们还会依赖刚刚的计时器,在每次任务超时之后再进行一次检查,看它引用是否被修改,如果是再重设。通过这2个手段我们就能解决覆盖失效的问题,提升了监测的稳定性。方案二: Choreographer帧率测量
了解RenderThread之前,我们不得不提到Choreographer的渲染流程。Choreographer渲染流程
1. 主线程处于 Sleep 状态,等待 Vsync 信号。2. Vsync 信号到来,主线程被唤醒,Choreographer 回调 FrameDisplayEventReceiver.onVsync 开始一帧的绘制。3. 处理 App 这一帧的 Input 事件(如果有的话)。4. 处理 App 这一帧的 Animation 事件(如果有的话)。5. 处理 App 这一帧的 Traversal 事件(如果有的话)。6. 主线程与渲染线程同步渲染数据,同步结束后,主线程结束一帧的绘制,可以继续处理下一个 Message(如果有的话,IdleHandler 如果不为空,这时候也会触发处理),或者进入 Sleep 状态等待下一个 Vsync。7. 渲染线程首先需要从 BufferQueue 里面取一个 Buffer(dequeueBuffer) ,进行数据处理之后,调用 OpenGL 相关的函数,真正地进行渲染操作,然后将渲染好的 Buffer 还给 BufferQueue (queueBuffer) ,SurfaceFlinger 在 Vsync-SF 到了之后,将所有准备好的 Buffer 取出进行合成,如下图:图片来源: 高爷: Android Systrace 基础知识 - MainThread 和 RenderThread 解读Choreographer测量流程
利用系统 Choreographer 模块,向该模块注册一个 FrameCallback 监听对象,同时通过另外一条线程循环记录主线程堆栈信息,并在每次 Vsync 事件 doFrame 通知回来时,循环注册该监听对象,间接统计两次 Vsync 事件的时间间隔,当超出阈值时,取出记录的堆栈进行分析上报。Choreographer.getInstance().postFrameCallback(new Choreographer.FrameCallback() {
@Override
public void doFrame(long frameTimeNanos) {
if(frameTimeNanos - mLastFrameNanos > 100) {
...
}
mLastFrameNanos = frameTimeNanos;
Choreographer.getInstance().postFrameCallback(this);
}
});
可以较方便的捕捉到卡顿的堆栈,但其最大的不足在于,无法获取到各个函数的执行耗时,对于稍微复杂一点的堆栈,很难找出可能耗时的函数,也就很难找到卡顿的原因。另外,通过其他线程循环获取主线程的堆栈,如果稍微处理不及时,很容易导致获取的堆栈有所偏移,不够准确,加上没有耗时信息,卡顿也就不好定位。所以我们需要借助字节码插桩技术来解决这一个痛点问题。@Override
public void dispatchBegin(long beginNs, long cpuBeginMs, long token) {
super.dispatchBegin(beginNs, cpuBeginMs, token);
// 记录当前方法执行的sIndex,单链表
indexRecord = AppMethodBeat.getInstance().maskIndex("EvilMethodTracer#dispatchBegin");
}
@Override
public void dispatchEnd(long beginNs, long cpuBeginMs, long endNs, long cpuEndMs, long token, boolean isVsyncFrame) {
super.dispatchEnd(beginNs, cpuBeginMs, endNs, cpuEndMs, token, isVsyncFrame);
long start = config.isDevEnv() ? System.currentTimeMillis() : 0;
long dispatchCost = (endNs - beginNs) / Constants.TIME_MILLIS_TO_NANO;
try {
// 超出时间,解析上传
if (dispatchCost >= evilThresholdMs) {
long[] data = AppMethodBeat.getInstance().copyData(indexRecord);
long[] queueCosts = new long[3];
System.arraycopy(queueTypeCosts, 0, queueCosts, 0, 3);
String scene = AppActiveMatrixDelegate.INSTANCE.getVisibleScene();
MatrixHandlerThread.getDefaultHandler().post(new AnalyseTask(isForeground(), scene, data, queueCosts, cpuEndMs - cpuBeginMs, dispatchCost, endNs / Constants.TIME_MILLIS_TO_NANO));
}
} finally {
indexRecord.release();
if (config.isDevEnv()) {
String usage = Utils.calculateCpuUsage(cpuEndMs - cpuBeginMs, dispatchCost);
MatrixLog.v(TAG, "[dispatchEnd] token:%s cost:%sms cpu:%sms usage:%s innerCost:%s",
token, dispatchCost, cpuEndMs - cpuBeginMs, usage, System.currentTimeMillis() - start);
}
}
}
方案三: 字节码插桩
采用方法插桩监听每个方法的耗时,通过设置Looper的Printer,来监听监听每个Message的耗时,超过阀值,触发方法上报。通过代理编译期间的任务 transformClassesWithDexTask,将全局 class 文件作为输入,利用 ASM 工具,高效地对所有 class 文件进行扫描及插桩。修改字节码的方式,在编译期修改所有 class 文件中的函数字节码,对所有函数前后进行打点插桩。不过,有四点需要注意一下:1. 选择在该编译任务执行时插桩,是因为 proguard 操作是在该任务之前就完成的,意味着插桩时的 class 文件已经被混淆过的。2. 选择 proguard 之后去插桩,是因为如果提前插桩会造成部分方法不符合内联规则,没法在 proguard 时进行优化,最终导致程序方法数无法减少,从而引发方法数过大问题。3. 为了减少插桩量及性能损耗,通过遍历 class 方法指令集,判断扫描的函数是否只含有 PUT/READ FIELD 等简单的指令,来过滤一些默认或匿名构造函数,以及 get/set 等简单不耗时函数。4. 为了方便及高效记录函数执行过程,我们为每个插桩的函数分配一个独立 ID,在插桩过程中,记录插桩的函数签名及分配的 ID,在插桩完成后输出一份 mapping,作为数据上报后的解析支持。
工具对比
使用指南
- 需要分析应用流程和耗时,选TraceView / 插桩之后的Systrace
监测指标
流畅Smoothness计算
- 当Vsync信号到达时会会调用HAL层的HWComposer.vsync()函数,通知HWComposer引擎进行GPU渲染和显示,,然后发送Vsync信号给SurfaceFinger处理。
- SurfaceFinger接收到Vsync信号后,调用SurfaceFlinger的addResyncSample函数用来处理 Vsync 信号,addResyncSample函数可以将App的渲染帧同步到显示器的刷新时间,以避免出现撕裂和卡顿等问题。
- EventThread通过onVsyncEvent函数将Vsync信号分发给需要使用Vsync信号的App,实现更平滑和流畅的渲染效果。
- 当系统收到显示器的 Vsync 信号时,DisplayEventReceiver.onVsync() 函数会被调用,并将时间戳和Displayer物理属性传递给App。
- App收到时间戳和Displayer物理属性后,FrameHandler可以帮助应用程序将渲染帧与 Vsync 信号同步,当 FrameHandler 接收到 Vsync 信号时,FrameHandler会调用 sendMessage() 方法,并将帧同步消息作为参数传递给该方法。
第一个痛点是: 数据量大,不方便统计,导致淹没真实卡顿Case。第二个痛点是: 不能简单使用平均值和方差。因为不同设备的卡顿标准线不一样,我们应该按照设备等级划分标注线- 指标二: XPM评分(denzelzhou):离散程度
监测范围
慢函数监测
技术需求: 通过外部配置阈值记录Android慢函数,如果超过阈值,那么将慢函数方法名和耗时间信息记录在本地JSON文件
- 首先定义一个类 SlowFunctionClassVisitor,继承自 ClassVisitor,用于实现对类的字节码的修改。
- 在 SlowFunctionClassVisitor 中重写 visitMethod 方法,用于实现对方法的字节码的修改。在 visitMethod 方法中,先调用父类的 visitMethod 方法,然后使用 ASM 的 API 生成新的方法字节码,并将原来的方法字节码替换为新的方法字节码。
- 在生成新的方法字节码时,使用 Label 和 JumpInsnNode 等 ASM 的 API 插入代码,实现对方法的耗时进行判断。如果方法耗时超过阈值,则记录慢函数信息,并将其写入本地 JSON 文件中。
- 为了实现记录慢函数信息和将其写入本地 JSON 文件中,使用了 org.json.JSONObject 和 java.io.FileWriter 等相关的 API。
假设我们要记录的慢函数是指执行时间超过100ms的函数,并且阈值的配置方式是通过一个配置文件,其中包含一个键值对 "slow_function_threshold=100",存放在assets目录下的config.json文件中。首先,在Android Studio中创建一个新的Android项目,并将以下代码添加到build.gradle文件的dependencies块中:dependencies {
implementation 'org.ow2.asm:asm:9.2'
implementation 'org.ow2.asm:asm-util:9.2'
}
接下来,我们需要创建一个ASM的ClassVisitor,用于在方法调用前后插入代码。public class SlowFunctionClassVisitor extends ClassVisitor {
private String className;
public SlowFunctionClassVisitor(ClassVisitor classVisitor) {
super(Opcodes.ASM9, classVisitor);
}
@Override
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {
className = name;
super.visit(version, access, name, signature, superName, interfaces);
}
@Override
public MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions) {
MethodVisitor mv = cv.visitMethod(access, name, descriptor, signature, exceptions);
return new SlowFunctionMethodVisitor(Opcodes.ASM9, mv, access, name, descriptor, className);
}
private static class SlowFunctionMethodVisitor extends AdviceAdapter {
private final String methodName;
private final String className;
protected SlowFunctionMethodVisitor(int api, MethodVisitor mv, int access, String name, String descriptor, String className) {
super(api, mv, access, name, descriptor);
this.methodName = name;
this.className = className;
}
private static final String startTimeFieldName = "_start_time";
@Override
protected void onMethodEnter() {
//在方法进入时插入代码
visitFieldInsn(Opcodes.GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
visitLdcInsn("enter " + methodName);
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V", false);
visitVarInsn(Opcodes.ALOAD, 0);
visitMethodInsn(Opcodes.INVOKESTATIC, "java/lang/System", "currentTimeMillis", "()J", false);
visitFieldInsn(Opcodes.PUTFIELD, className, startTimeFieldName, "J");
}
@Override
protected void onMethodExit(int opcode) {
//在方法退出时插入代码
visitVarInsn(Opcodes.ALOAD, 0);
visitFieldInsn(Opcodes.GETFIELD, className, startTimeFieldName, "J");
visitMethodInsn(Opcodes.INVOKESTATIC, "java/lang/System", "currentTimeMillis", "()J", false);
visitInsn(Opcodes.LSUB);
visitVarInsn(Opcodes.LSTORE, 2);
Label l1 = new Label();
visitVarInsn(Opcodes.LLOAD, 2
visitLdcInsn(100L); // 100ms
visitInsn(Opcodes.LCMP);
visitJumpInsn(Opcodes.IFLE, l1);
// 超过阈值,记录慢函数信息
visitFieldInsn(Opcodes.GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
visitLdcInsn("exit " + methodName + " cost " + Long.toString(2L) + " ms");
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V", false);
// 加载阈值
visitLdcInsn("slow_function_threshold");
visitMethodInsn(Opcodes.INVOKESTATIC, "android/content/res/Resources", "getSystem", "()Landroid/content/res/Resources;", false);
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "android/content/res/Resources", "getAssets", "()Landroid/content/res/AssetManager;", false);
visitLdcInsn("config.json");
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "android/content/res/AssetManager", "open", "(Ljava/lang/String;)Ljava/io/InputStream;", false);
visitTypeInsn(Opcodes.NEW, "org/json/JSONObject");
visitInsn(Opcodes.DUP);
visitTypeInsn(Opcodes.NEW, "java/io/InputStreamReader");
visitInsn(Opcodes.DUP);
visitVarInsn(Opcodes.ALOAD, 4);
visitMethodInsn(Opcodes.INVOKESPECIAL, "java/io/InputStreamReader", "", "(Ljava/io/InputStream;)V", false);
visitMethodInsn(Opcodes.INVOKESPECIAL, "org/json/JSONObject", "", "(Ljava/io/Reader;)V", false);
visitLdcInsn("slow_function_threshold");
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "org/json/JSONObject", "optInt", "(Ljava/lang/String;)I", false);
// 比较耗时和阈值
visitVarInsn(Opcodes.LLOAD, 2);
visitInsn(Opcodes.LCMP);
visitVarInsn(Opcodes.ILOAD, 5);
Label l2 = new Label();
visitJumpInsn(Opcodes.IF_ICMPLE, l2);
// 超过阈值,写入本地JSON文件
visitFieldInsn(Opcodes.GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
visitLdcInsn("write to local json file: " + methodName + " cost " + Long.toString(2L) + " ms");
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V", false);
visitTypeInsn(Opcodes.NEW, "org/json/JSONObject");
visitInsn(Opcodes.DUP);
visitVarInsn(Opcodes.ALOAD, 0);
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/lang/Class", "getName", "()Ljava/lang/String;", false);
visitLdcInsn(methodName);
visitVarInsn(Opcodes.LLOAD, 2);
visitMethodInsn(Opcodes.INVOKESPECIAL, "org/json/JSONObject", "", "()V", false);
visitVarInsn(Opcodes.ASTORE, 6);
visitTypeInsn(Opcodes.NEW, "java/io/FileWriter");
visitInsn(Opcodes.DUP);
visitLdcInsn("slow_function.json");
visitMethodInsn(Opcodes.INVOKESPECIAL, "java/io/FileWriter", "", "(Ljava/lang/String;)V", false);
visitVarInsn(Opcodes.ASTORE, 7);
// 将慢函数信息写入JSON文件
visitVarInsn(Opcodes.ALOAD, 7);
visitVarInsn(Opcodes.ALOAD, 6);
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "org/json/JSONObject", "toString", "()Ljava/lang/String;", false);
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/FileWriter", "write", "(Ljava/lang/String;)V", false);
visitVarInsn(Opcodes.ALOAD, 7);
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/FileWriter", "flush", "()V", false);
visitVarInsn(Opcodes.ALOAD, 7);
visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/FileWriter", "close", "()V", false);
visitLabel(l2);
}
super.visitInsn(opcode);
}
}
以上是一段使用ASM技术实现记录Android慢函数的代码。它通过在方法的字节码中插入代码来判断方法耗时,如果超过阈值,就记录慢函数信息,并将其写入本地JSON文件中。在实现过程中,使用了ASM的相关API来生成字节码,并在方法执行过程中进行修改。流畅性监测
Activity、Service、Receiver 组件生命周期的耗时和调用次数也是我们重点关注的性能问题。例如Activity的onCreate不应该超过 1 秒,不然会影响用户看到页面的时间。Service 和 Receiver 虽然是后台组件,不过它们的生命周期也是占用主线程的,也是我们需要关注的问题。对于组件生命周期我们应该采用更严格的监测,可以全量上报各个组件各个生命周期的启动时间和启动次数。一般的做法是,通过编译时插桩来做到组件的生命周期监测。FPS监测
我们需要采集的卡顿数据有: 卡顿次数/交互次数比,帧绘制时间采样. 处理方式可以参考下面的内容:- 定义一个FPS监测类,该类中包含FPS计算的逻辑:
public class FPSMonitor {
private static final long ONE_SECOND = 1000000000L;
private long lastTime = System.nanoTime();
private int frameCount = 0;
private int fps = 0;
public void update() {
long currentTime = System.nanoTime();
frameCount++;
if (currentTime - lastTime >= ONE_SECOND) {
fps = frameCount;
frameCount = 0;
lastTime = currentTime;
}
}
public int getFps() {
return fps;
}
}
- 使用ASM字节码框架在编译期间对代码进行插桩,将FPS监测的逻辑插入到游戏或应用程序的主循环中:
public class GameLoop {
private FPSMonitor fpsMonitor = new FPSMonitor();
public void loop() {
while (true) {
long startTime = System.nanoTime();
// 游戏或应用程序的主逻辑// ...// 在主循环中插入FPS监测逻辑
fpsMonitor.update();
int fps = fpsMonitor.getFps();
System.out.println("FPS: " + fps);
// 控制FPS为60long elapsedTime = System.nanoTime() - startTime;
long sleepTime = (1000000000L / 60) - elapsedTime;
if (sleepTime > 0) {
try {
Thread.sleep(sleepTime / 1000000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
- FPS监测逻辑被插入到了应用程序的主循环中,在每一帧结束时计算FPS,并将计算结果输出到控制台。我们使用插件可以将上述代码转换成字节码文件。转换代码如下:
public class FpsMonitorClassVisitor extends ClassVisitor {
public FpsMonitorClassVisitor(ClassVisitor classVisitor) {
super(Opcodes.ASM5, classVisitor);
}
@Override
public MethodVisitor visitMethod(int access, String name, String desc, String signature, String[] exceptions) {
MethodVisitor mv = super.visitMethod(access, name, desc, signature, exceptions);
if (name.equals("loop")) {
mv = new FpsMonitorMethodVisitor(mv);
}
return mv;
}
private static class FpsMonitorMethodVisitor extends MethodVisitor {
public FpsMonitorMethodVisitor(MethodVisitor mv) {
super(Opcodes.ASM5, mv);
}
@Override
public void visitCode() {
super.visitCode();
mv.visitVarInsn(Opcodes.ALOAD, 0);
mv.visitFieldInsn(Opcodes.GETFIELD, "GameLoop", "fpsMonitor", "LFPSMonitor;");
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL, "FPSMonitor", "update", "()V", false);
mv.visitVarInsn(Opcodes.ALOAD, 0);
mv.visitFieldInsn(Opcodes.GETFIELD, "GameLoop", "fpsMonitor", "LFPSMonitor;");
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL, "FPSMonitor", "getFps", "()I", false);
mv.visitFieldInsn(Opcodes.PUTSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");
mv.visitInsn(Opcodes.SWAP);
mv.visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/PrintStream", "println", "(I)V", false);
}
}
}
创建了一个 FpsMonitorClassVisitor 类来处理插桩逻辑,它继承自 ClassVisitor 类。在 visitMethod 方法中,我们判断当前访问的方法是否为 loop 方法,如果是,则创建一个 FpsMonitorMethodVisitor 对象来处理该方法的插桩逻辑。在 FpsMonitorMethodVisitor 中,我们将 FPS 监测逻辑插入到了游戏或应用程序的主循环中,在每一帧结束时计算 FPS,并将计算结果输出到控制台。最后,我们将创建的 FpsMonitorClassVisitor 对象传递给 ASM 的 ClassReader,并通过 ClassWriter 来生成修改后的字节码。Thread监测
由于文件IO开销、线程间的竞争或者锁可能会导致主线程空等,从而导致卡顿。我们可以借助BHook对线程进行监测,需要监测以下两点:1. 线程数量
需要监测线程数量的多少,以及创建线程的方式。例如有没有使用统一的线程池,这块可以通过 hook 线程的 nativeCreate() 函数,主要用于进行线程收敛,减少线程数量。2. 线程时间
监测线程的用户时间 utime、系统时间 stime 和优先级。主要是看哪些线程 utime+stime 时间比较多,占用了过多的 CPU。上报时机
超过设置慢函数的阈值,开始收集慢方法函数和时间,开始上报。业务降级
注意事项
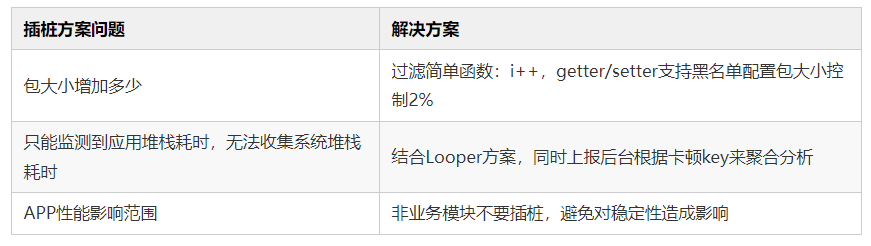
方案优化
为了提高自身性能,我们是不是可以同步线程方式进一步优化获取堆栈性能getStackTrace
getStackTrace获取堆栈信息有如下两大业务痛点:
为了解决上述业务痛点,我们可以采取ThreadDump和AsyncGetCallTrace两种解决方案。
StackSampler
在SafePoint处,JVM可以确保所有线程都停止执行,从而保证当前状态的一致性。利用SafePoint,我们可以实现无需挂起主线程的异步堆栈采样,从而避免了主线程被挂起的影响。public class StackSampler {
private static final int MAX_STACK_DEPTH = 32; // 最大堆栈深度
private static final int MAX_STACK_SAMPLES = 100; // 最大缓存采样数
private static final long SAMPLE_INTERVAL = 100L; // 采样间隔,单位:毫秒
private final ConcurrentLinkedQueue stackSamples; // 堆栈采样缓存
private final AtomicBoolean profiling; // 采样标志位
public StackSampler() {
stackSamples = new ConcurrentLinkedQueue<>();
profiling = new AtomicBoolean(false);
}
// SafePoint 采样方法
private void sample() {
if (profiling.compareAndSet(false,true)) {
// 在 SafePoint 处异步采样堆栈信息
new Thread(() -> {
// 延迟一段时间,等待所有线程进入 SafePoint
try {
Thread.sleep(SAMPLE_INTERVAL);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 采样堆栈信息并添加到缓存中
String stackTrace = getStackTrace();
stackSamples.offer(stackTrace);
// 重置采样标志位
profiling.set(false);
}).start();
}
}
// 获取当前线程的堆栈信息
private String getStackTrace() {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
StringBuilder sb = new StringBuilder();
for (int i = 2; i 2); i++) {
sb.append(stackTrace[i].toString()).append('\n');
}
return sb.toString();
}
// 输出所有采样结果
public void dump() {
int count = 0;
String stackTrace;
while ((stackTrace = stackSamples.poll()) != null && count System.out.println(stackTrace);
count++;
}
}
public static void main(String[] args) throws InterruptedException {
StackSampler sampler = new StackSampler();
sampler.sample(); // 开始采样
Thread.sleep(MAX_STACK_SAMPLES * SAMPLE_INTERVAL); // 等待采样完成
sampler.dump(); // 输出采样结果
}
}
用SafePoint实现了异步堆栈采样,并在每次采样时延迟一段时间,等待所有线程进入SafePoint,以确保采样的堆栈信息是当前线程的真实状态。同时,采样的结果存储在一个线程安全的队列中,等待输出。当采样完成后,通过 dump() 方法输出所有的采样。另外,为了避免频繁地采样堆栈信息导致性能问题,我们可以通过减少采样频率的方式进行优化。例如,可以通过将采样间隔从10毫秒调整为100毫秒,来减少采样的次数,从而降低对系统性能的影响。另外,为了更高效地采样和处理堆栈信息,我们可以考虑采用缓存和批量处理的策略。例如,可以将采样的结果存储在一个缓存队列中,当队列达到一定大小时再进行批量处理,从而减少对队列的频繁访问和操作,提高程序的执行效率。AsyncGetCallTrace
通过使用SIGPROF定时器,Native层收集堆栈方式,优化getStackTrace获取堆栈需要暂停主线程运行和相关性能问题#include
#include
#include
#include
#include
#include
#define SAMPLE_INTERVAL 100 // 采样间隔,单位:毫秒
#define MAX_STACK_DEPTH 32 // 最大堆栈深度
#define MAX_STACK_SAMPLES 100 // 最大缓存采样数
volatile sig_atomic_t profiling = 0; // 采样标志位
// SIGPROF 信号处理函数
void profiling_handler(int signum) {
profiling = 1; // 标记需要采样堆栈信息
}
// 开始采样
void start_profiling() {
struct sigaction sa;
struct itimerval timer;
// 注册 SIGPROF 信号处理函数
sa.sa_handler = profiling_handler;
sa.sa_flags = SA_RESTART;
sigemptyset(&sa.sa_mask);
sigaction(SIGPROF, &sa, NULL);
// 设置定时器
timer.it_value.tv_sec = SAMPLE_INTERVAL / 1000;
timer.it_value.tv_usec = (SAMPLE_INTERVAL % 1000) * 1000;
timer.it_interval = timer.it_value;
setitimer(ITIMER_PROF, &timer, NULL);
}
// 停止采样
void stop_profiling() {
struct itimerval timer;
// 关闭定时器
timer.it_value.tv_sec = 0;
timer.it_value.tv_usec = 0;
timer.it_interval = timer.it_value;
setitimer(ITIMER_PROF, &timer, NULL);
}
// 收集堆栈信息并输出到标准输出流
void dump_stack() {
void *stack[MAX_STACK_DEPTH];
int depth = backtrace(stack, MAX_STACK_DEPTH);
if (depth > 0) {
backtrace_symbols_fd(stack, depth, STDOUT_FILENO);
}
}
int main() {
start_profiling(); // 开始采样
int sample_count = 0;
while (sample_count if (profiling) { // 如果需要采样堆栈信息
profiling = 0; // 重置采样标志位
dump_stack(); // 收集堆栈信息
sample_count++; // 统计采样数
}
}
stop_profiling(); // 停止采样
return 0;
}
start_profiling() 和 stop_profiling() 函数用于开启和关闭 SIGPROF 定时器,定时器的时间间隔由 SAMPLE_INTERVAL 宏定义指定。profiling_handler() 函数是 SIGPROF 信号的处理函数,每次接收到信号后,将 profiling 变量置为 1。dump_stack() 函数用于收集堆栈信息,通过 backtrace() 函数获取堆栈信息,并输出到标准输出流中。在 main() 函数中,循环收集堆栈信息,直到采样数达到最大值为止,最大采样数由 MAX_STACK_SAMPLES 宏定义指定。通过 SIGPROF 定时器和信号处理函数的方式,可以在 Native 层收集堆栈信息,避免了在 Java 层获取堆栈信息的开销和性能问题。不过需要注意的是,堆栈采样对应用程序的性能有一定影响,需要权衡好采样间隔和采样深度等参数。
当测试提出卡顿问题,测试会新建Bug单给责任人处理。导致卡顿的原因有很多,比如函数非常耗时、I/O 非常慢、线程或锁间竞争等。随着移动端用户越来越注重产品体验,APM系统也逐渐成为互联网公司重要基础设施。卡顿是衡量App性能的一个重要指标,建设卡顿APM监测平台是Android卡顿优化长效治理关键。同时,通过建设卡顿APM监测平台,帮助业务找到卡顿原因也是架构组TL考核评测员工重点OKR指向。为了解决卡顿标准不明确问题,小木箱今天和大家着重探讨了卡顿监测的方方面面。如果小木箱的文章对你有所帮助,那么欢迎关注小木箱的公众号: 小木箱成长营。我是小木箱,我们下一篇见~https://github.com/Tencent/matrix/wiki/Matrix-Android-TraceCanary
http://gityuan.com/2017/02/25/choreographer/
https://www.jianshu.com/p/9e8f88eac490
最后推荐一下我做的网站,玩Android: wanandroid.com ,包含详尽的知识体系、好用的工具,还有本公众号文章合集,欢迎体验和收藏!

扫一扫 关注我的公众号
如果你想要跟大家分享你的文章,欢迎投稿~
┏(^0^)┛明天见!










