魁北克风景秀丽,相对安全稳定,居民十分友好热情。4天的会议十分愉快,收获颇丰。
首先看到了与自己研究课题密切相关的工作:
(1) 一个用Gaussian-Mixture Model 做的一个眼底照片异常检测工作,仅判断图片是正常图片(无病变)或者有任何类型的病变。
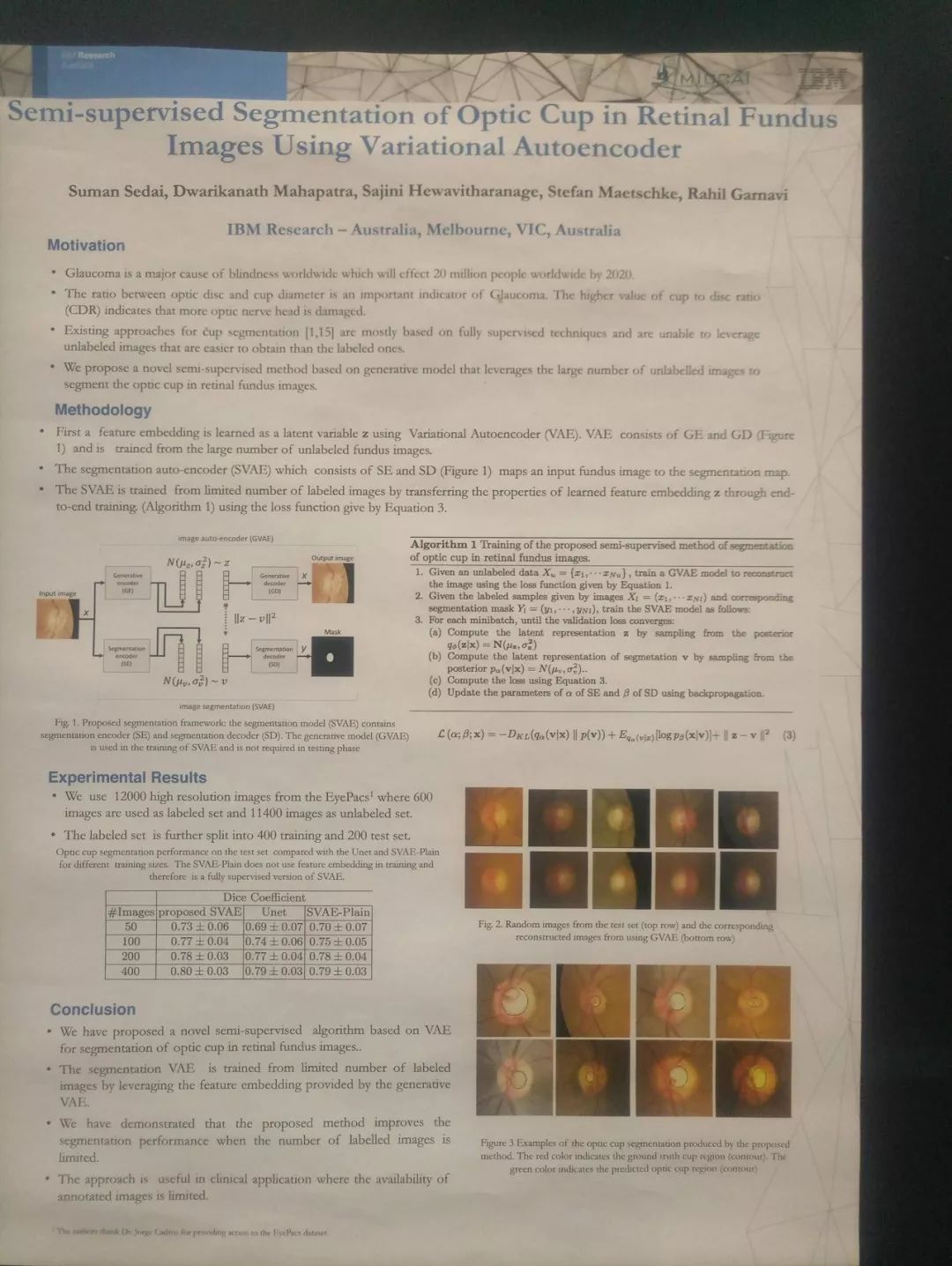
(2) 一个印度机构的工作,使用超分辨率,希望使用超分辨率扩大微血管瘤等精细结构,但是其是否具有科学性个人觉得仍然值得探讨。

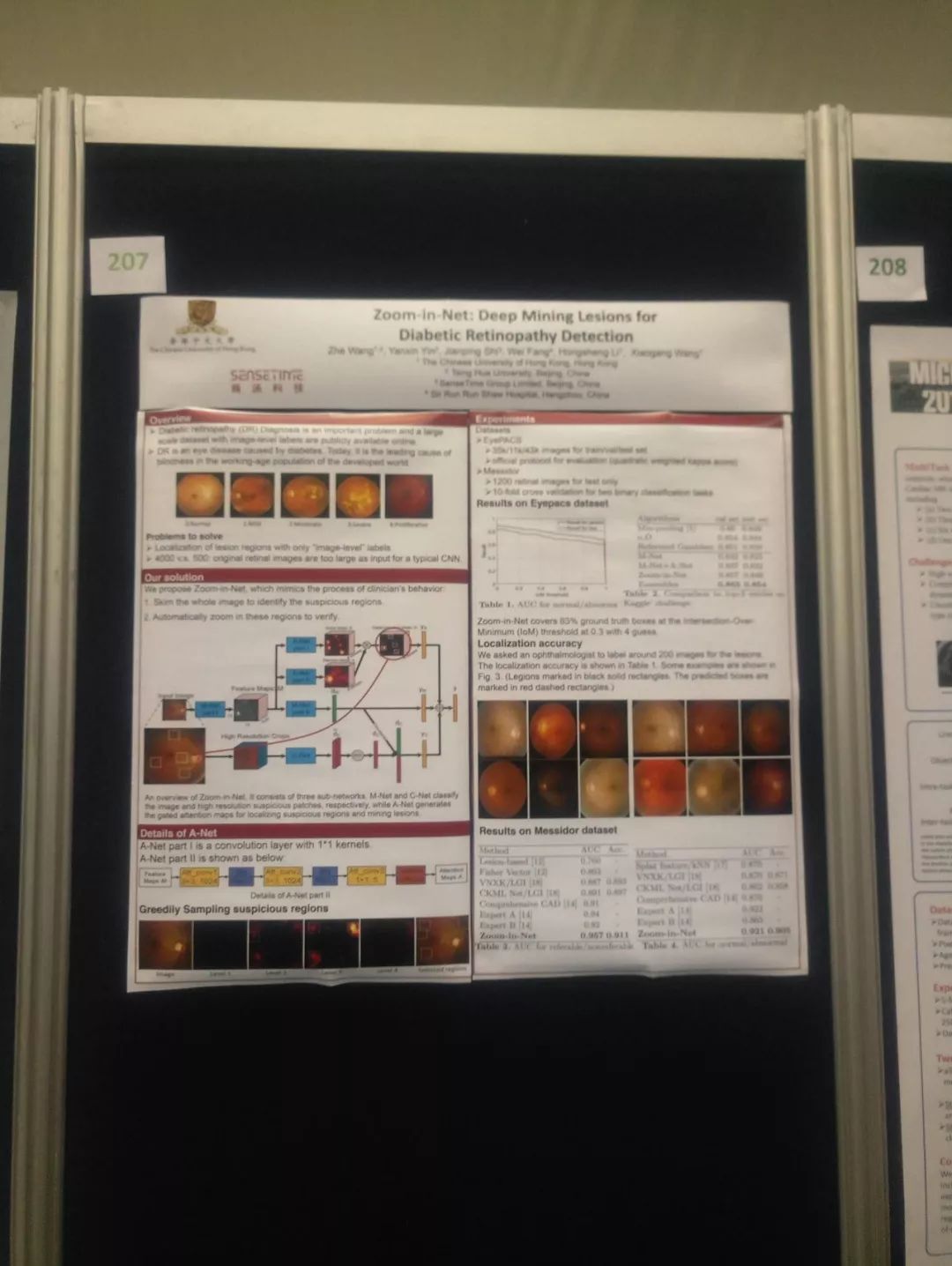
(3)然后是商汤科技,使用 Zoom-in-Net,尝试先找感兴趣的部分,然后在高分辨率诊断?
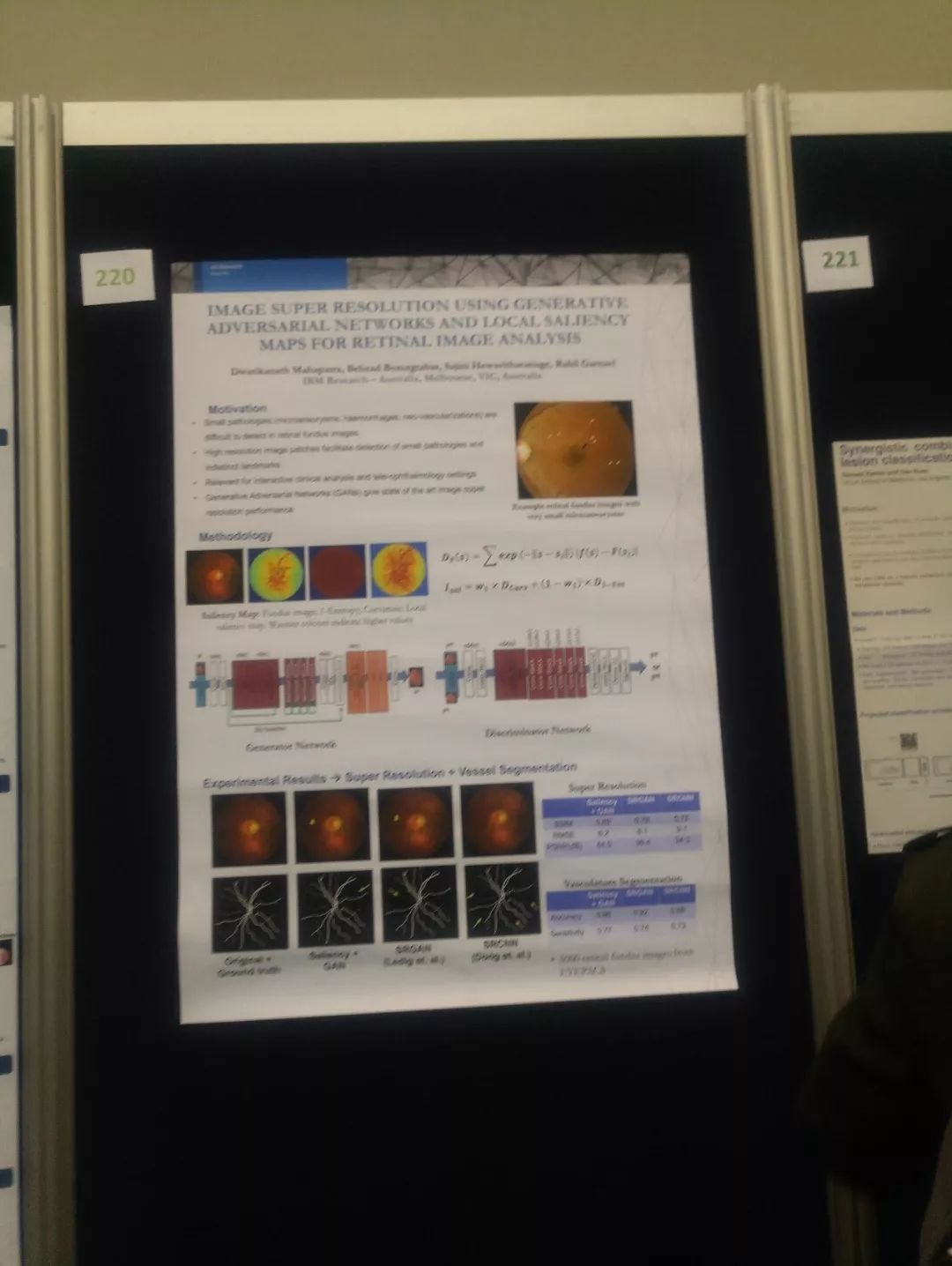
(4) 百度工作:使用bounding box 进行病变分类,之后再进行分级。病变分类发表在MICCAI上,分级及其他功能未透露
(5) Google 在眼底分级中的探索过程

Google在眼底分级过程中也并非一帆风顺,他们研究、迭代过程与我们目前不断迭代过程十分相似。Google眼底分级项目成员比较细致的分享了他们的研究过程,对我们项目很有启发,也肯定了我们正在进行的方向至少是没有大问题的。
Google项目主要在针对印度地区进行,印度地区医疗条件相对比较落后,导致病变诊断缺失十分严重。Google对每张病变图片进行了0~4分级模型训练。最终使用Eyepas数据库进行测试。



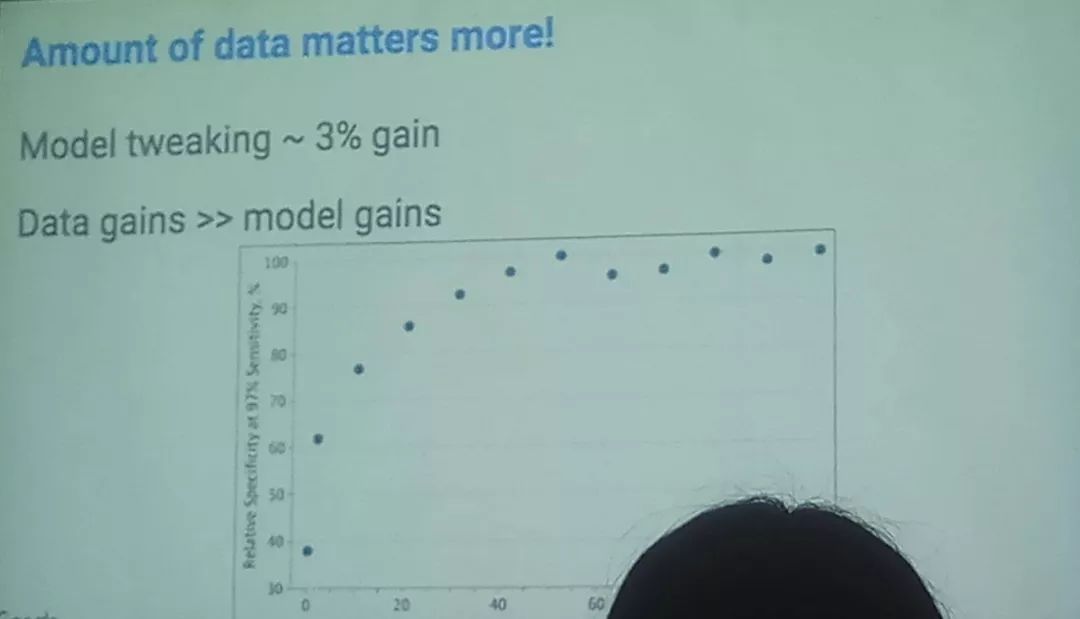
Google也使用了多种网络,多种超参数调整,多种分辨率,最终也使用了集成学习,将
多个神经网络的结果融合(和我目前的框架相同)。Google强调了数据的重要性,在数据较少的情况下难以得到较好的分级结果,在50k图片数量之前,图片越多,分级效果明显提高,图片数量足够多之后分级效果趋于稳定。
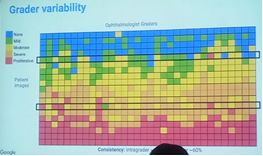
医生标注差异是一个很严重的问题,在Google标注过程中发现标注者的一致性仅有60%左右(就是每个标注与最多标注相同的比例,如下图),这一问题尤其在轻度和中度、中度和重度之间比较明显,PDR及以上一致性相对比较高。我们的一致性比他们高(在我们算法出错的部分,王、李标记与青浦原始标记一致性88%左右)



由此他们强调了高质量数据的重要性(因为他们的标记差异很大)。关于多个标记如何确定ground truth,他们也尝试了多种办法,商议确定、取众数。其中主要的误区在于微血管瘤、误诊的出血、伪影。因此我们做伪影检测、微血管瘤检测、质量检测还是很有意义的。
可以看出在轻度、中度上,AI算法与人工选择比较接近了。同时商议再决定有更高的敏感度。
Google正在考虑的多个视角融合的问题,目前我们的数据包含2个视角,也是一个可以利用的点,Google数据中应该没有这么多多视点的数据。目前他们也正在探索。
关于利用左右眼协同检测,Google、百度等各方都没有先例,只是在kaggle竞赛中一致队伍使用了左右眼协同。





