主要部分目录
-
高端存储定义忆旧
-
技术发展:磁盘路径冗余
&
写缓存镜像技术
-
RDMA + NVMe-oF
:有利于扩展的
Shared-Everying
-
通用硬件?
Alletra Storage MP B1000
、
X10000
和
VAST
-
参考配置与存储系统架构选型
接前文:《
可软件定义的双机热备(HA)存储方案
》
高端存储定义忆旧
在《
AI时代的高端文件存储系统:IBM、DDN、Weka 和 VAST
》中我讨论了一些知名的文件存储,LLM大模型的热度,确实促进了非结构化数据容量和性能的需求。而今天我要跟大家聊的是块存储(SAN),特别是在云计算兴起之前,多数的交易型结构化数据,比如关键数据库等大都放在上面。
在我的记忆中,传统的
高端存储系统
(阵列)通常认为应包含以下几方面特性:
1、
性能
,对于SAN块存储协议,交易型应用更多看重
IOPS
。这个与支持的磁盘/SSD数量以及控制器配置等有关。
2、
RAS
(可靠性、可用性、可服务性),一般要求
可用性达到6个9
(99.9999%)。中低端存储,包括大多数x86架构的双控阵列达不到这一水平,所以传统高端存储通常
不低于4控
,老式的有些是Scale-up/新型多为Scale-out横向扩展形态。IBM DS8000系列虽为双控制器但基于Power小型机,算是个例外吧。
注:后来游戏规则被玩坏了,也有些双控阵列标称6个9可用性,把2套组成双活冗余也算进去了。
3、支持Mainframe
大型机和FICON
存储网络。以前应该只有IBM、EMC Symmetrix家族和HDS的高端如VSP能达标。但后来一方面大机越卖越少了,另外像HPE 3PAR、国内的菊厂等也推出多控架构的高端存储,不满组这点但性能指标上也够了。
在上一篇转载文章的结尾处,我透露了一些这篇想写的东西。关于今天举例的产品,我在网上看到《
HPE Alletra Storage MP B10000:适用于现代工作负载的多协议存储
》内容不错,给了我一些启发。
https://www.storagereview.com/zh-CN/review/hpe-alletra-storage-mp-b10000-multi-protocol-storage-for-modern-workloads
(英文好的朋友,可以点切换看原文)
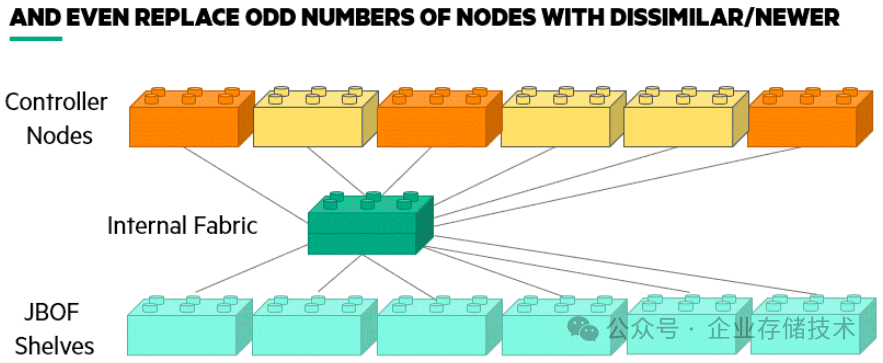
上图中的Internal Fabric使用的是
RoCE
(RDMA以太网),后端JBOF(Just Bundle of Flash)机箱其实也可以称为
EBOF或者E-JBOF
——通过
NVMe-oF
协议将其中的SSD连接到前端控制器节点。这样每块NVMe盘对每个控制器都可见,就属于新型的
Shared-Everything
共享架构。
图中出示的另一点,是可以添加/更换一部分前端的控制器为不同或者较新配置的型号,不像传统SAN块存储阵列那样严格要求对等。谈到这里,我想先回顾下双控/多控存储系统要解决的高可用基础硬件:
技术发展:磁盘路径冗余 & 写缓存镜像技术
1、数据(磁盘/SSD)路径冗余:
在传统集中式存储架构中,
RAID/纠删码
或者
镜像/多副本
只解决了基础的数据可靠性。为了达到整个数据链路高可用,SAN存储的前端服务器连接FC(光纤通道)、iSCSI这些存储网络,都支持
多路径冗余
。而为了应对阵列控制器单点故障,每一块硬盘/SSD至少需要同时连接到2个控制器,这样才能确保HA
故障切换
。
从我进入IT行业以来,先后经历过支持热插拔的80针SCSI硬盘、FC-AL(光纤通道仲裁环路)硬盘、SAS HDD/SSD,以及今天的双端口NVMe SSD。凡是可用在双控阵列中的,基本上都支持
双端口访问
。
下面为
HPE 3PAR
(即后来的Alletra 9000家族)高端存储——4控制器架构的
读/写路径
示意图:
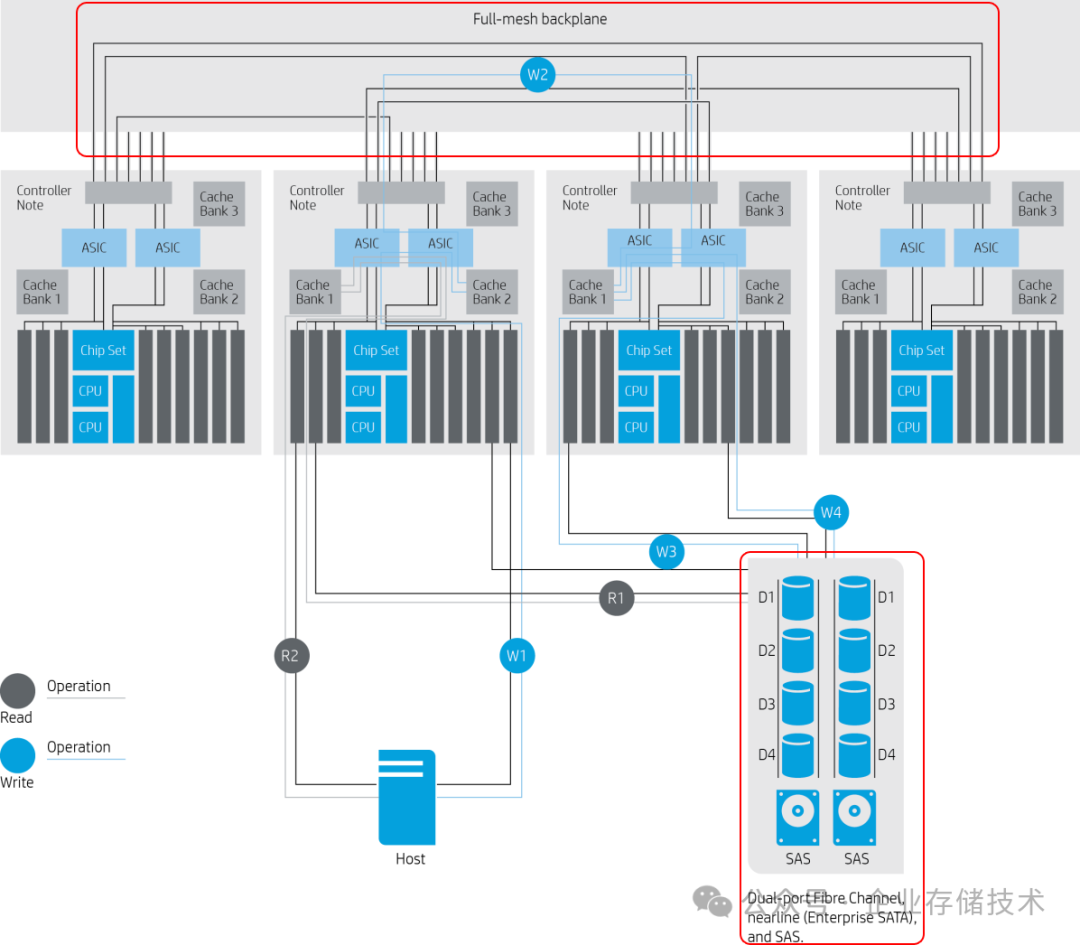
注意:图中可以看到早期3PAR
专有硬件ASIC
在控制器互连和Cache管理中的作用,后来应该是用NTB一类的技术替代了。但是像NTB、PCIe Switch、通过背板实现2-Node对NVMe SSD共享访问这些,仍然
不属于大型云计算服务商数据中心里的标准化硬件
。
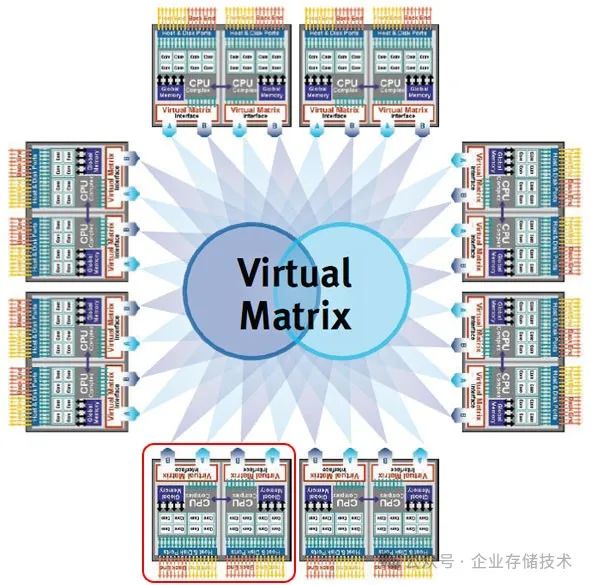
上图示意的中间2个控制器,同时通过SAS线缆连接到后端的一个JBOD磁盘扩展柜。只要这2个控制器不同时坏,磁盘/SSD中的数据就能保持访问。同理,另外2个控制器应该也是同时连接到一个或多个JBOD机箱。
读/写路径中的 “W2”,就是我接下来要说的另一个要点:
2、写缓存冗余保护
落盘的数据保证不丢了,但为了性能更高往往还要在DRAM中缓存一部分写Cache(包括压缩/重删也可以用这个)。这块除了要加
BBU电池/电容
应对断电之外,还要在不同
控制器之间做镜像
保护。如今双控阵列的成熟方案是通过基于PCIe的NTB(非透明桥接)来实现,上面HPE 3PAR的Full Mesh背板则是多控之间的
PCIe全网状连接
——理论上能把缓存镜像到多个控制器。这样在有控制器失效时,就可以换个控制器重建DRAM镜像以减少性能受影响的时间——提高服务质量。
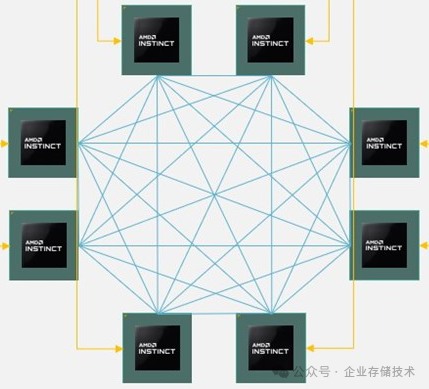
如今AMD Instinct MI300等GPU的OAM UBB互连,看上去与当初3PAR存储架构图里面的控制器互连示意图蛮像的(都是点对点/全网状)。当然Infinity Fabric/xGMI的带宽要大多了。
除了3PAR高端系列的Full Mesh背板之外,中端4控的7000系列存储,曾经是通过点对点PCIe Cable来实现“全网状互连”。如下图:
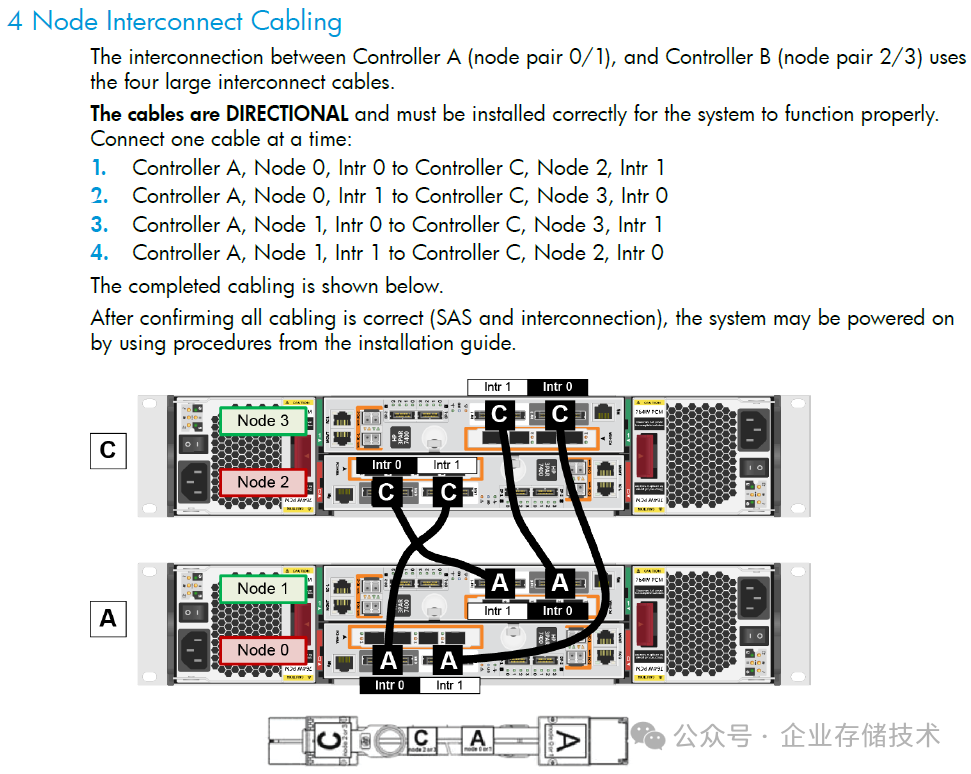
下图则是当年更有代表性的高端存储系统——EMC
Symmetrix VMAX
,它的多控制器(引擎)间互连使用的
InfiniBand
网络,软件架构上类似于NUMA的
全局缓存
管理技术。
扩展阅读:《
从VMAX到PowerMax:Dell EMC新一代NVMe高端阵列解析
》
上图中并没有完全画出VMAX的后端磁盘连接。实际上每个SAS JBOD也是同时连接到一对控制器,比如我用红圈标出的“双控”。到后来使用NVMe SSD的全闪高端存储PowerMax,是通过带有
PCIe Switch的JBOF
连接到控制器,保证性能但同时也不容易拓扑到太大规模。(好在控制器对够多,而且NVMe单盘性能够高)
对于普通双控阵列,除了NTB缓存镜像之外,还有下面这种写Cache保护方法:
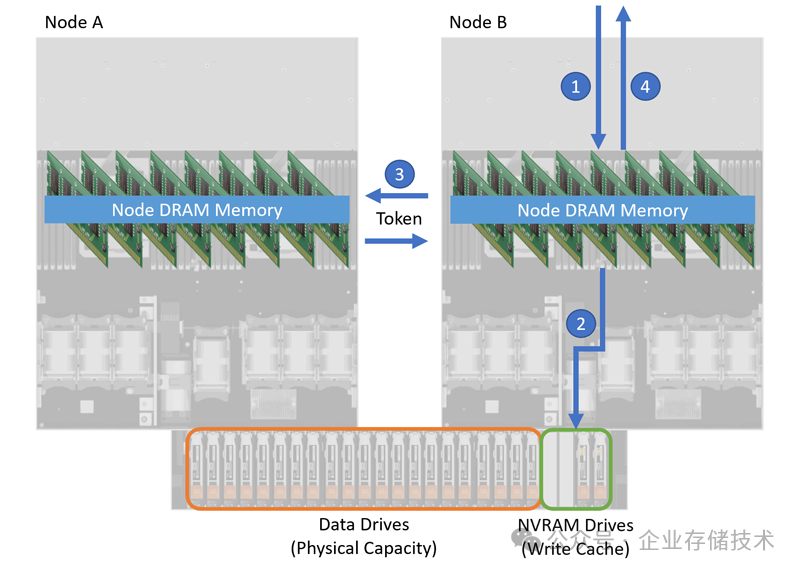
上图我在《
Dell EMC PowerStore详解:NVMe+SAS全闪存阵列,还是一体机?
》中列出过。PowerStore的控制器机箱中除了20个SSD数据盘之外,还会有2-4个使用DRAM的
NVMe接口
“内存盘”,写缓存数据写入到成对的
NVRAM
中进行Mirror保护。
对于今天更流行的
分布式存储
而言,许多时候做不到每节点都有NVDIMM或者NVRAM,一方面有跨节点的数据冗余,另外就是像Ceph那样加上Journal或者WAL日志一类的技术来实现Crash恢复的一致性,以保证数据完整性。这类技术在
写I/O路径上的开销比传统存储要高,好在全闪存流行了,加上软件层面一些新技术的应用&调优,有些Server SAN的性能也可以跑得挺高
。
RDMA + NVMe-oF:有利于扩展的Shared-Everying
前面写了许多铺垫,终于到了本文要谈的代表产品。
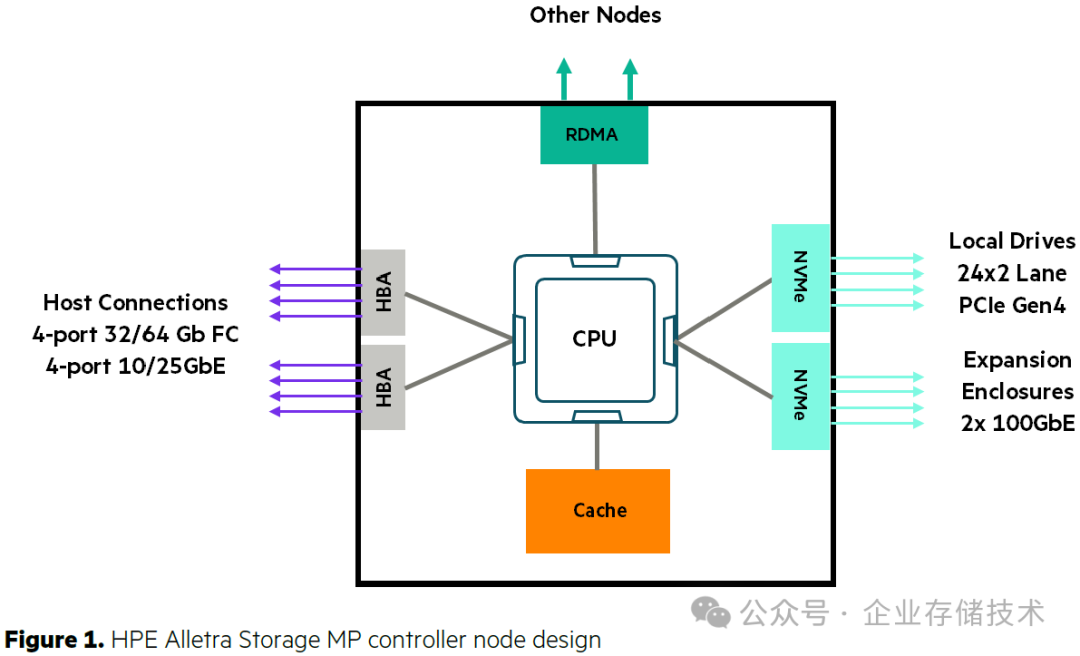
上图来自《
HPE Alletra Storage MP B10000 architecture
》文档,B10000的定位应该是接替以前的9000系列高端块存储系统,但我却找不到像“Full Mesh Backplane”那样复杂的设计结构了。原因是,前后端要解决的那2个问题,都通过RDMA以太网来实现了。
比如NVMe SSD,在示意图的CPU右侧,有一种方式是
本地直连
24个x2 Lane PCIe Gen4固态盘(每块盘另外2个Lane连接到另一控制器);还有一种扩展方式就是通过2个100GbE以太网口连接
NVMe-oF的JBOF
(EBOF)扩展柜。
控制器之间
的网络互连,也在之前PCIe的基础上加入了
RDMA网络,
至少
4控跨机箱
时用的这个。上图中CPU上方绿色部分,虽然没写具体速率,下文中有资料证明是100Gb,而且与NVMe-oF后端SSD扩展使用不同的网卡。
如果B10000是延续3PAR的架构,那么橙色的Cache(写缓存)部分,也可以靠RDMA网络来在控制器间镜像保护吧?后面我还会列出点关于写缓存不同的描述。
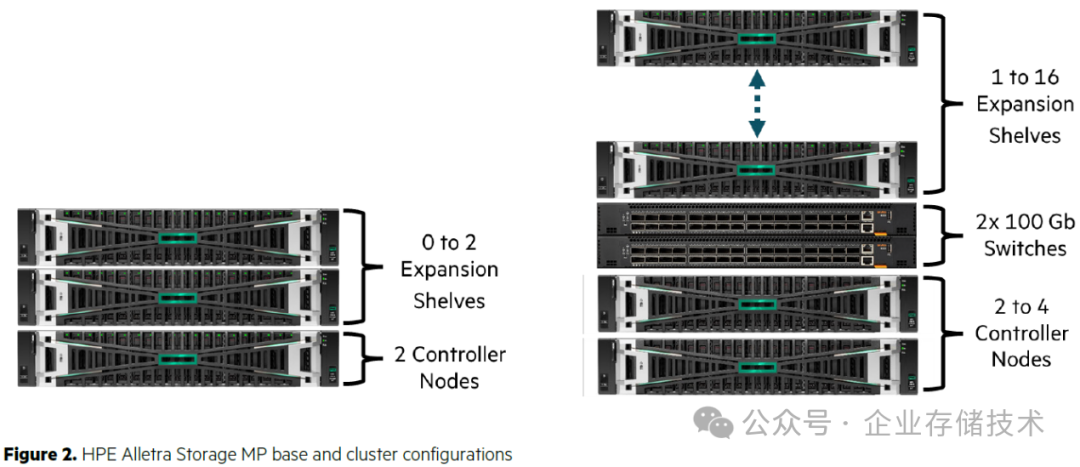
左边是HPE Alletra Storage MP系列
双控
机型的基础硬件,对应
块存储机型
就是无需交换机的B101x0系列。在2U双控节点机箱之外,还可以选配最多2个JBOF SSD扩展柜——最多72个NVMe SSD。




