导读:机器学习是今年的技术热点。工程师应该怎样入门机器学习?机器学习的难点在哪里?工程师应该从哪些方面解决这些问题?高可用架构分享了斯坦福大学一个人工智能博士的思考。
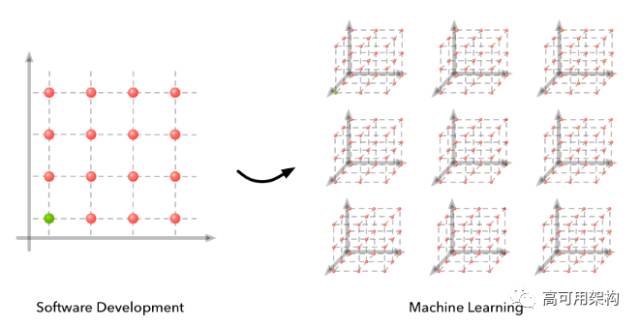
在过去几年中,机器学习取得了巨大的进步。在线课程已经出现,精心编写的教科书已经将前沿研究聚集成一种更容易理解的形式,并出现了无数的框架对构建机器学习系统相关的底层进行了抽象。在某些情况下,这些进步使得将现有模型植入您的应用程序更加容易。
然而,机器学习仍然是一个相对困难的问题。毫无疑问,通过研究推进机器学习算法是困难的。它需要创造力,实验和坚韧。机器学习在实现现有算法和模型以适合新应用程序时仍然是一个难题。专门从事机器学习的工程师相对于软件开发工程师这几年获得了工资溢价。
这个困难往往不是由于数学 - 由于上述框架,机器学习实现不需要强烈的数学。
这个困难的一个方面涉及建立什么工具应该解决什么问题的直觉。这需要理解可用的算法和模型以及每个算法和模型的权衡和约束。这种技能可以通过接触这些模型(类,教科书和论文)来学习,但更多的是通过自己实现和测试这些模型。这种类型的知识体系的建构存在于计算机科学的所有领域,并且不是机器学习所独有的。软件工程需要注意到框架,工具和技术以及明智的设计决策权衡。
困难在于机器学习是一个难于调试问题。机器学习的调试发生在两种情况下:1)您的算法不工作或2)您的算法不能很好地工作。机器学习的独特之处在于,当事情不能按预期工作时,很难弄清楚为什么是错误的。因为调试困难,在执行修复/升级和看到结果之间的调试循环中经常有延迟。很少有一个算法在第一次就工作,所以大部分时间花在建立算法。
指数级调试难度
在标准软件工程中,当你编写一个问题的解决方案,在大多数情况下,某些东西不能按预期工作时,有两个维度,可能会出现问题:算法或实现。 例如,一个简单的递归算法:
def recursion(input):
if input is endCase:
return transform(input)
else:
return recursion(transform(input))
当代码不能按预期工作时,我们可以枚举失败的情况。 在此示例中,网格可能如下所示:
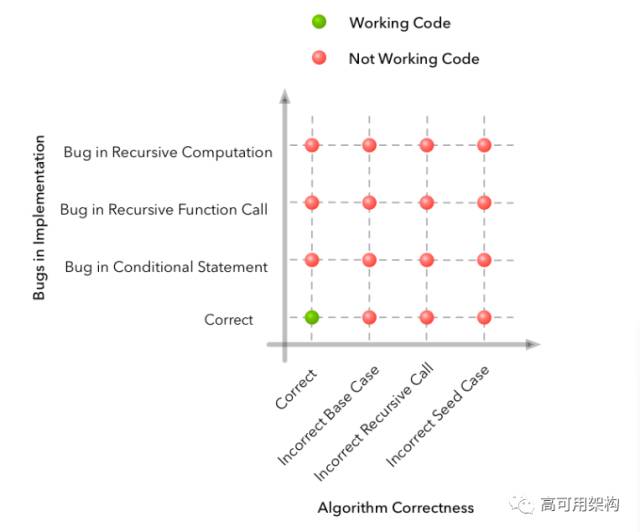
沿着水平轴,我们有几个可能在算法设计中犯了错误的例子。沿着垂直轴,我们有几个例子说明在算法的实现中可能出现问题的地方。沿着任何一个维度,我们可能有问题的组合(即多个实现错误),但是我们唯一有一个有效的解决方案是如果算法和实现都是正确的。
调试过程成为关于错误的信号(编译器错误消息,程序输出等)与你的直觉(问题可能在哪里)的组合问题。这些信号和启发式帮助使您将可能的错误的搜索空间减小。
在机器学习流水线的情况下,有两个额外的维度:实际的模型和数据。为了说明这些维度,最简单的例子是使用随机梯度下降的训练logistic回归。这里算法正确性包括梯度下降更新方程的正确性。实现正确性包括特征和参数更新的正确计算。数据中的错误通常涉及噪声标签,在预处理中产生的错误,没有正确的监控信号或甚至没有足够的数据。模型中的错误可能涉及建模能力的实际限制。例如,当您的真正决策边界是非线性时,可能使用了线性分类器。
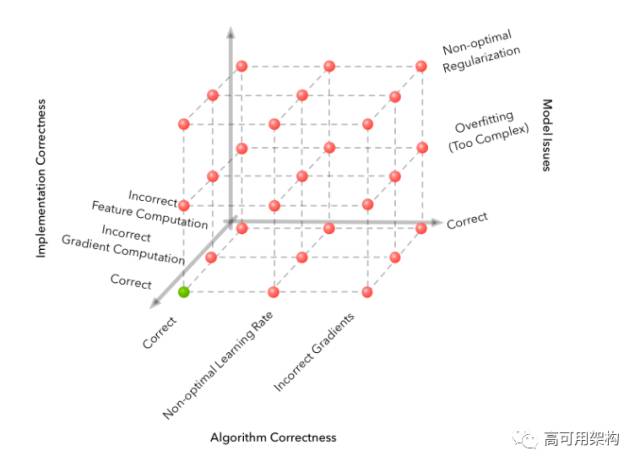
我们的调试过程从2D网格到4D超立方体(为了清楚起见,上面四个维度中有三个)。 第四个数据维可以可视化为这些立方体的序列(注意,只有一个立方体具有正确的解)。
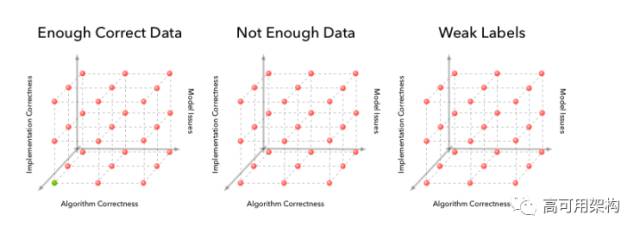
“指数级”更难的原因是如果有n种可能的方式出错,有n x n种方式可能会在2D出错和n x n x n x n方式在4D情况下出错。 必须根据可用的信号建立一个寻找出错地方的直觉。 幸运的是,对于机器学习算法,你还有更多的信号来找出哪里出错了。 例如,特别有用的信号是训练和测试集上的损失函数图,算法的实际输出,开发数据集和算法中间计算的汇总统计。
延迟调试循环
使机器学习调试复杂化的第二个复杂因素是长调试周期。在实施潜在的修正和获得关于改变是否成功的结果信号之间通常是几十小时或几天。我们从Web开发中了解到,启用自动刷新的开发模式可显着提高开发人员的生产力。这是因为您能够最小化对开发流程的中断。这在机器学习中通常是不可能的 - 对数据集训练算法可能需要几个小时或几天的时间。深度学习中的模型特别容易在调试周期中出现这种延迟。长调试循环强制“平行”实验范例。机器学习开发人员将运行多个实验,因为瓶颈往往是算法的训练。通过并行处理,你希望利用指令流水线(对于开发者而不是处理器)来提高并行度。被迫以这种方式工作的主要缺点是,无法利用在顺序调试或实验时构建的累积知识。
机器学习是通常在有许多维度的事情可能出错(或工作得更好)的情况下,发展出错的(或者可以工作得更好)直觉的艺术。这是您继续构建机器学习项目时的一个关键技能:您开始将某些行为信号与问题可能在您的代码中的位置相关联。在我自己的工作有很多例子。例如,我训练神经网络时遇到的最早的问题之一是我的训练损失函数的周期性。损失函数会随着数据的过去而衰减,但每次都会跳回到更高的值。经过多次尝试和错误,我最终得知,这通常是因为一个训练集的情况下,当您使用随机梯度算法处理萧批量数据时,没有被正确地随机化(这是一个实现问题,但看起来像一个数据问题)。
总之,快速有效的调试是实现现代机器学习流水线中最需要的技能。
来源:高可用架构(
ArchNotes
)
编辑:Lixy
近期热门文章Top10
↓ 点击标题即可查看 ↓
1.
无数学不人生——原来数学讲的是满满的人生啊!
2.
二十个令程序员泪流满面的瞬间
3.
热烈祝贺赵忠贤院士荣获2016年度国家最高科技奖
4.
开年革命性发现:金属氢!百年理论终于完成向现实的华丽转身
5.
这个游戏没有玩家,为何在学术圈火了半个世纪?
6.
终于明白“女人如水”的含义 | 线上科学日
7.
物理界的华山论剑,一次会议聚集了地球三分之一的智慧
8.
这些大科学家的logo,你见过吗?
9.
人类为什么要为难自己搞出个闰年?
10.
一言不合折只鸡! | 线上科学日
点此查看以往全部热门文章






