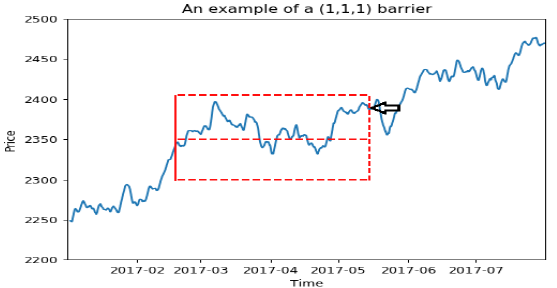
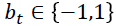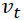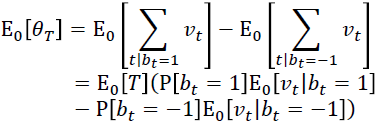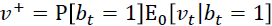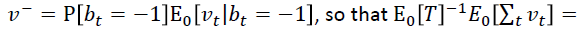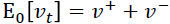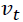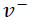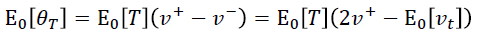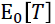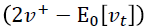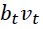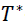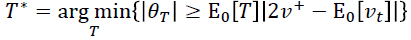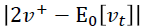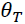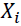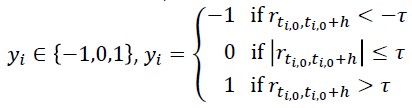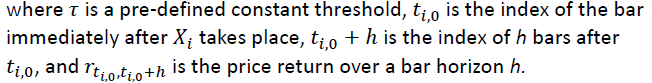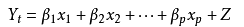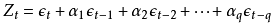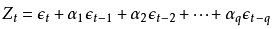作者就举了个例子,例如,您可以从大量患者中获得血液样本,并测量其胆固醇。
当然,一些基本的常见因素会改变胆固醇分布包括平均值和标准差,但样本仍然是独立的。
假设你在实验室中,将每根管子的血液滴取到右侧的9根管子里。
现在,你需要确定预测高胆固醇(饮食,运动,年龄等)的特征,而不必确定每位患者的胆固醇水平。
这也是ML在金融中面临的挑战。


(此段分析来自知乎,作者是:babyquant)
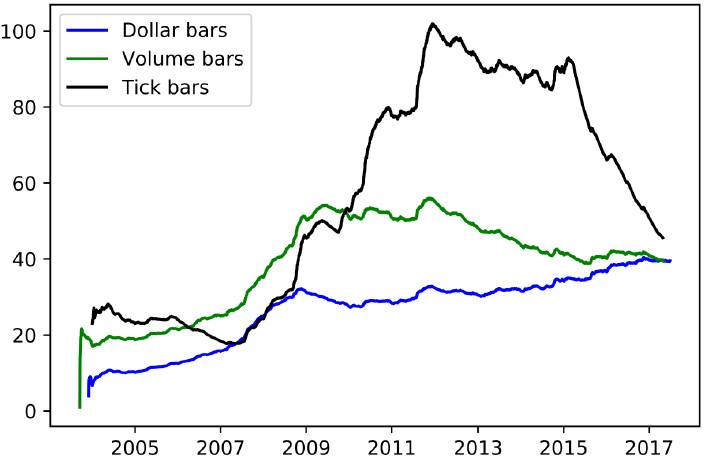
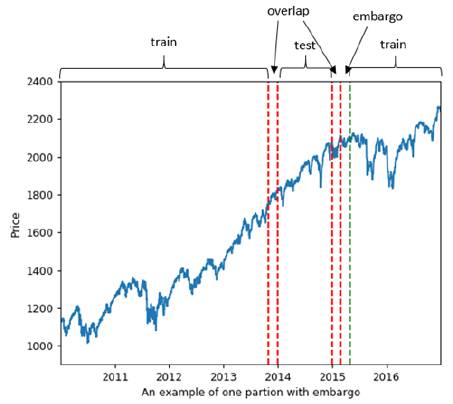
这就是说,样本分布不是独立同分布的。比如它之前说用等成交量来划分,比如都是1000的成交量:
t=1要到t=10才达到1000
t=2其实也是到t=10达到1000
t=3其实也是到t=10达到1000
这说明或许t=10那个时刻的成交量特别大,到了这里就能达到1000,没到这里就不能。因此如果我们做样本的时候,其实t=10这个用了很多次,比如10次,但t=11这个只用了1次。
当然,等时间没有这个问题的,比如1-10,2-11,3-12。。。每个时间的行情都用到同样的次数,除了开头结尾少数几个。
所以他就定义了一个c_t,就是说t这个行情用了c_t次,然后这个行情对应的return就要先除以c_t。其实这部分我没太看懂,按常理来说c_t如果都是一样的那么w_i应该是相等才对,但貌不是。其实它本质上就没打算给每个样本等权重,如果c_t是一样的,那么就是每个样本对应的收益率y_i的绝对值来加权;如果c_t不是恒定的,则用它那种算法计算出来的收益率的绝对值来加权,总之就不是等权。
所以它这么做会给y_i绝对值大的样本更大的权重,更偏向高波动行情了。如上面那个例子:
c_1=1,c2=2...c_10=10,c_11=1....
w_1=|r1/1+r2/2+r3/3+...+r10/10|
w_2=|r2/2+r3/3+...+r10/10|
...
w_10=|r10/10|
然后再除以一个相同的系数,比例不变。这么看w_10的权重会比较低,因为w_10对应的行情r10被用了10次,分到它自己的已经很小了。
如果是等权重的话,因为w_1到w_9对应的样本,其实他们本质上都是依赖r_10的,其他行情可能成交量很低,意义不大,因此,这样r_10就会被计算很多次;现在新的算法大概就是让每个行情的return都一共只被计算1次吧,比如10个r10/10加起来。
这些只对那种按成交量或者其他非等时间划分样本的方法有意义。普通人那种固定时间预测的其实不需要这么复杂。
R语言里面regression的函数一般都支持样本不同权重的,比如glmnet里面有一个参数是weight:
weights observation weights. Can be total counts if responses are proportion matrices.Default is 1 for each observation
所以按照他的方法给每个样本一些权重之后还是不难实现的。
但Python里面的lasso是不支持weighted sample的:

看不到weight相关的参数。总之python做统计类分析是一个很烂的工具,重要一点的东西都没有,只有最基本的,做金融稳定亏钱的节奏啊。(这点对于Python的统计包要吐槽一下,R语言在这方面确实和强势!)
这段分析,个人觉得理解的很不错!以供参考。