经过对目前已更新9个章节的粗读,我了解到这是一本即全面又有一定深度的著作,能帮助初学者普及知识,也可以做为在某一领域深入研究的朋友更全面的技术参考。选择转载闪存阵列这个章节,与笔者自己的知识背景和兴趣有关。
再举个例子,XtremIO最近的软件更新加入了原生复制功能,看上去没有双活那么显得高大上,而在一些资深用户专家那里(包括金融这样的关键应用),综合考虑网络链路成本、性能等方面因素后,许多时候会认为短至分钟级快照+异步复制更为实用。
2.6 全闪存阵列AFA
经常听人说起全闪存阵列,给人一种很厉害的样子,那这个全闪存阵列到底是个什么东西?下面将以某一款EMC XtremIO为例来带你入门。
本节参考了Vijay Swami写的XtremIO Hardware/Software Overview&Architecture Deepdive一文,图片也主要来自这篇文章。
2.6.1 整体解剖
1.结构
图2-17所示是一个标准的XtremIO全闪存阵列,含有两个X-Brick,之间用Infiniband互联。可以看出,X-Brick是核心,那么X-Brick里面究竟是什么?
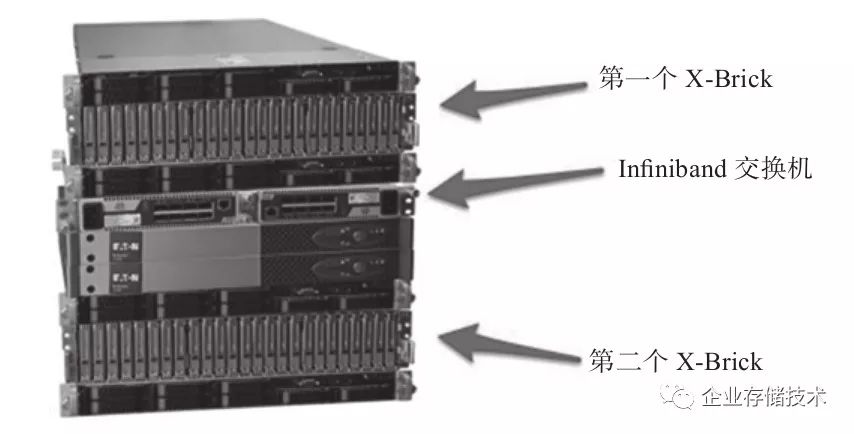
图2-17 XtremIO全闪存阵列结构
我们来看看,一个X-Brick包括:
2.存储控制器
如图2-18所示,存储控制器其实就是个Intel服务器,配有2个电源,看起来是NUMA架构的2个独立CPU、2个Infiniband控制器、2个SAS HBA卡。Intel E5CPU,每个CPU配有256GB内存。

图2-18 存储控制器机箱内部
如图2-19所示,其后面插有各种线缆,看着感觉乱糟糟的,如图2-19所示。设计的架构适用于集群,所以线缆有很多是冗余的。

图2-19 X-Brick背面连线图
阵列正面照,LCD显示的是UPS电源状态。图2-20所示是一个个竖着的就是SSD阵列。

图2-20 Xtrem-IO全闪存阵列正面照片
3.配置
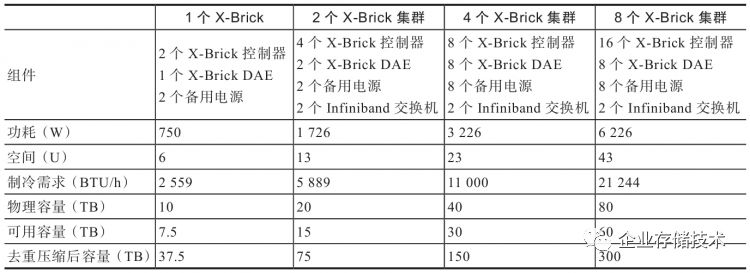
如表2-5所示,一个X-Brick容量是10TB,可用容量7.5TB,但是考虑到数据去重和压缩大概为5∶1的比例,最终可用容量为37.5TB。
表2-5 XtremIO配置表
4.性能
有人做了XtremIO性能测试,在2个X-Brick的全闪存阵列跑了550个虚拟机,为7000个用户服务器提供服务。其每天平均读写带宽为350MB/s~400MB/s,20k IOPS;最高时达到20GB/s,200k IOPS。
5.软件控制台
我们来看看软件控制台参数,如图2-21所示,图左边显示数据降低率2.5:1,其中去重率1.5:1,压缩率1.7:1;图右边是带宽、IOPS和延迟监控图,显示每个SSD当前的性能和汇总的读写性能。
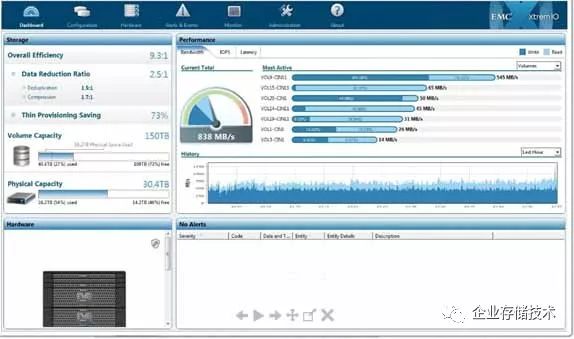
图2-21 软件控制台性能监控
图2-22是每个SSD的监控图,DAE中每个盘下面有模拟的灯,根据盘当前的读写活动不断闪烁,看起来非常酷!
图2-22 SSD监控图
2.6.2 硬件架构
EMC XtremIO是EMC对全闪存阵列市场的突袭,它从底层开始完全根据闪存特性设计。
如图2-23所示,1个X-Brick包含2个存储控制器,一个装了25个SSD的DAE,还有2个电池备用电源(Battery
Backup
Unit,BBU)。每个X-Brick包含25个400GB的SSD,原始容量10TB,使用的是高端的eMLC闪存,一般擦写寿命比普通的MLC长一个数量级。如果只买一个X-Brick,配有两个BBU,其中一个是为了冗余。如果继续增加X-Brick,那么其他的X-Brick只需要一个BBU。

图2-23 X-Brick尺寸
X-Brick支持级联来增加容量,所以其是一种Scale-Out架构,最多可以到4个X-Brick甚至8个X-Brick(见图2-24)。
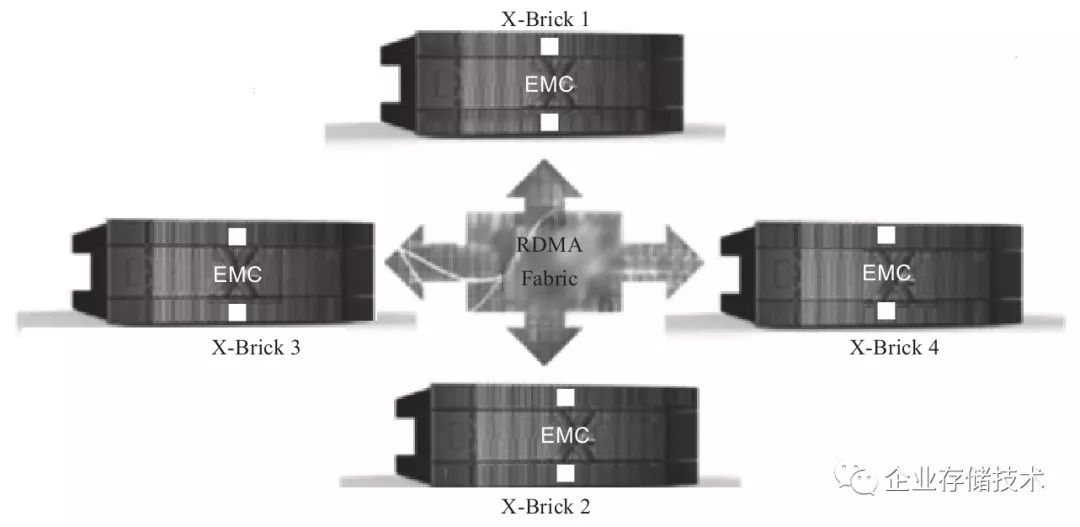
图2-24 X-Brick互联
X-Brick之间采用40Gbps的Infiniband交换机互联。
图2-25所示是一个X-Brick存储控制服务器的所有端口,40Gbps
Infiniband接口是为了后端数据连接,其实就是X-Brick之间的互联。那么,阵列和主机控制端如何进行数据交互呢?可以看出,既可以使用8Gbps
FC,也可以使用10Gbps的iSCSI。那又是如何连到那么多的SSD上呢?用的是6Gbps的SAS接口,和VNX类似。同时,电源和所有的接口都是有冗余的,用来应对故障。那么一个X-Brick节点自己数据的存储如何解决呢?它配有2个SSD,用来掉电时保存内存中的元数据。要知道,去重还是很占用内存的,因为一般每个数据块需要计算出一个Hash值,甚至双重Hash,用Hash值来判断唯一性。同时还有2个SAS硬盘,作为操作系统运行的磁盘。
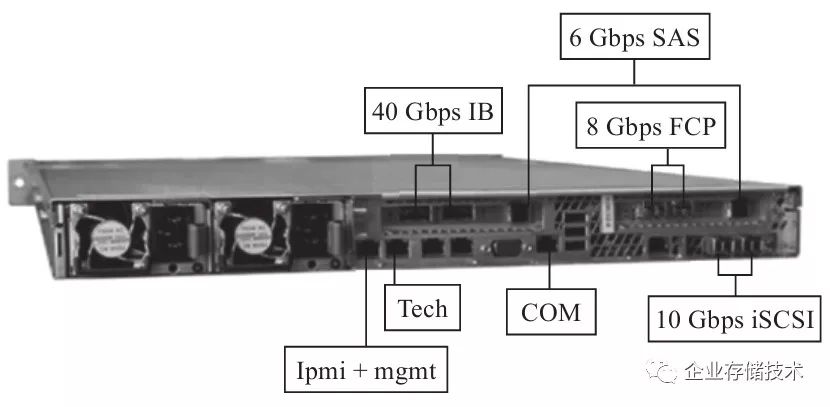
图2-25 X-Brick存储控制器端口
这样一来,存储控制器有自己的硬盘,而不占用DAE里面的SSD阵列,闪存阵列只用于存储用户数据,受2个存储控制器管理。这种架构的好处是结构清晰、界限分明,未来还能直接升级存储控制器软硬件而不动闪存阵列里的数据。
再来看看每个存储控制器的配置:有2个CPU插槽的1U机箱,使用2个8核的Intel Sandy Bridge CPU,256GB内存。
现在很多厂商都以最高性能为荣,拿一个新盘,写一点数据,甚至往DRAM
Cache里面写一点然后读出来,就吹嘘带宽、IOPS、延迟达到什么程度。更有甚者,不写数据,空盘读,达到巅峰带宽,简直把用户当三岁小孩。殊不知,对用户来讲,尤其是企业级用户,最高性能说明不了什么,只能忽悠那些不懂行的人,对真正业内人士来说,实际使用的稳定性能才是王道。
EMC全闪存阵列XtremIO,1个10TB的X-Brick,可用容量只有7.5TB,但是考虑到数据去重,用户能用的容量其实很大,跟实际的应用相关。比如虚拟桌面VDI应用,数据重复率很高,想想不同人安装的Windows
XP虚拟机的系统文件基本都是一样的,去重可以省下多大的空间啊!但是像一般的数据库应用,重复率又很低,毕竟数据库存储的数据几乎是随机的。
我们来看看一个X-Brick的IOPS(见图2-26):
-
100%4KB写:100K IOPS。
-
50/504KB读/写:150K IOPS。
-
100%4KB读:250K IOPS。

图2-26 XtremIO性能
如果是2个或更多X-Brick级联,性能线性增长,前面的数值翻几倍就可以了。
有一点必须得强调,上面说的这个性能看起来一般,但是要知道,这可是实际使用的性能,而且不是空盘拿来跑跑的性能,而是全盘写了至少80%之后的性能。为什么要写至少80%才能测得真正的性能?因为空盘写不会触发垃圾回收,当用户占满了整个带宽,且盘快写满的时候,垃圾回收才开始工作,此时用户能分到的带宽就少了,性能自然下降。而我们买了盘,肯定很快会写很多数据,所以只有快写满了才是常态。
2.6.3 软件架构
存储行业发展到今天,硬件越来越标准化,所以已经很难靠硬件出彩了。若能够制造存储芯片,例如三星这种模式,从底层开始都自己做,则可靠巨大的出货量坐收硬件的利润。但这种模式投资巨大,一般人玩不来,只能靠软件走差异化了,而且软件还有一个硬件没有的优势:非标准化。比如IBM的软件很多是基于自己的UNIX系统开发的,别人用了之后切换到其他厂家的软件难度很大,毕竟丢数据的风险不能随便冒。
看了前面的XtremIO(XIO)硬件架构之后,不少人可能觉得并没有什么复杂的,基本上就是系统集成、组装机嘛。但是,全闪存阵列的核心在软件,软件做好了,才能让用户体验到闪存阵列的性能。试想,如果iPhone装的是Android系统,你还会排队花五六千元去买吗?估计连两三千都舍不得了吧!

图2-27 装了Android的iPhone
1.XIO软件几大杀器
2.XIO软件核心设计思想
1)一切为了随机性能:任何节点上访问任意数据块,都不会增加额外的成本,即必须公平访问所有的资源。这是为什么?这样的结果就是即使节点增加,性能也能够线性增长,扩展性也好。
2)尽可能减少写放大:要知道,对SSD来讲写放大不仅会导致寿命缩短,还会因为闪存的擦写次数升高,导致质量下降,数据可靠性下降。XIO的设计目标就是让后台实际写入的数据尽量少,起到一种数据衰减的作用。
3)不做全局垃圾回收:XIO使用的是SSD阵列,而SSD内部是有高性能企业级控制器芯片的,当前的SSD主控都非常强大,垃圾回收效率很高,所以XIO并没有再重复做一遍垃圾回收。这样做的效果是降低了写放大,毕竟后台搬移的数据量少了,同时,节省出时间和系统资源提供给其他软件功能、数据服务和VAAI等。
4)按照内容存放数据:数据存放的地址用数据内容生成,跟逻辑地址无关。这样数据可以存放在任何位置,提升随机性能,同时还可以针对SSD做各种优化。数据可以平均放置在整个系统中。
5)True Active/Active数据访问:LUN没有所有者一说,所有节点都可以为任何卷服务,这样就不会因为某一个节点出问题而使性能受损。
6)扩展性好:性能、容量等都可以线性扩展。
3.XIO软件为什么运行在Linux用户态?
如图2-28所示,XIO的全闪存阵列软件架构,XIO
OS和XIO的软件都运行在Linux的用户态,这样有什么好处呢?我们知道,Linux系统分为内核态和用户态,我们的应用程序都在用户态运行,各种硬件接口等系统资源都通过内核态管理,用户态通过system
call访问内核资源。XIO软件运行在用户态有几大优点:
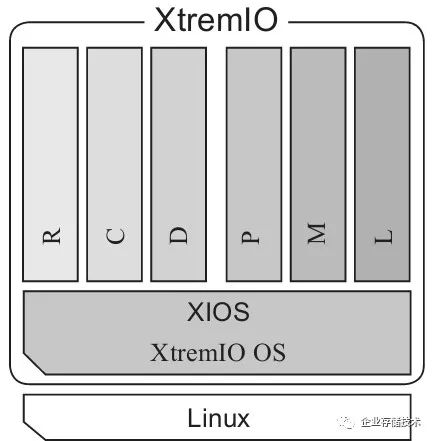
图2-28 XIO 软件架构
-
避免了内核态的进程切换,速度快。
-
开发简单,不需要借助各种内核接口,以及复杂的内存管理和异常处理。
-
不必受到GPL的约束。Linux是开源系统,程序在内核运行必然要用到内核代码,按照GPL的规定,就得开源,在用户态自己开发的应用就不受此限制。这种商业性软件,里面很多东西都是公司花了很多心血开发的核心技术,开源了就太不值了。由此也可以看出软件对全闪存阵列的价值!开源了还能卖那么贵吗?或者说开源了,谁都可以组装起来,装一个开源软件,全闪存阵列就只能打价格战了,高科技当大白菜卖。
在每个CPU上运行着一个XIOS程序:X-ENV,如果你敲一下“top”命令,就会发现这个程序掌控所有的CPU和内存资源。为什么这么做?
第一个作用就是为了XIO能100%使用硬件资源,能够运筹帷幄之中,决胜千里之外。知道自己赚多少钱,才能想清楚该怎么花。
第二个作用是不给其他进程影响XIO性能的机会,保证性能的稳定。
第三个作用是提供了一种可能性:未来可以简单修改就移植到UNIX或者Windows平台,或者从X86CPU移植到ARM、PowerPC等CPU架构,因为这都是上层程序,不涉及底层接口。
XIO是完全脱离了硬件的软件,为什么这么说?因为他们被EMC收购之后,很快就从自己的硬件架构切换到了EMC的白盒标准硬件架构,说明其软件基本不受硬件限制。而且,XIO的硬件基本没有自己特殊的组件,不包含FPGA,没有自己开发的芯片、SSD卡、固件等,用的都是标准件。这样做的好处是可以使用最新、最强大的X86硬件,还有最新的互联技术,比如比Infiniband更快的技术。如果自己开发了专用的硬件,要跟着CPU一起升级就很麻烦了,总是会慢一拍。
甚至,XIO完全可以只卖软件,只不过目前EMC没这么干而已。现在是硬件、软件、EMC客户服务一起卖。没准哪天,硬件不赚钱了,EMC就只卖XIO软件了。
2.6.4 工作流程
1.6大模块
XIO软件分为6个模块,以实现复杂的功能,其中包括三个数据模块R、C、D,三个控制模块P、M、L。
-
P(Platform,平台模块):监控系统硬件,每个节点有个P模块在运行。
-
M(Management,管理模块):实现各种系统配置。通过和XMS管理服务器通信来执行任务,比如创建卷、LUN的掩码等从命令行或图形界面发过来的指令。有一个节点运行M模块,其他节点运行另一个备用M模块。
-
L(Cluster,集群模块):管理集群成员,每个节点运行一个L模块。
-
R(Routing,路由模块):
-
其实就是把发过来的SCSI命令翻译成XIO内部的命令。
-
负责来自两个FC和两个iSCSI接口的命令,是每个节点的出入口“看门大爷”。
-
把所有读写数据拆成4KB大小。
-
计算每个4KB数据的Hash值,用的是SHA-1算法。
-
每个节点运行一个R模块。
2.读流程
读流程如下:
1)主机把读命令通过FC或iSCSI接口发送给R模块,命令包含数据块逻辑地址和大小。
2)R模块把命令拆成4KB大小的数据块,转发给C模块。
3)C模块查A2H表,得到数据块的Hash值,转发给D模块。
4)D模块查H2P表,得到数据块在SSD中的物理地址,读出来。
3.不重复的写流程
不重复的写流程如下(见图2-29):
1)主机把写命令通过FC或iSCSI接口发送给R模块,命令包含数据块逻辑地址和大小。
2)R模块把命令拆成4KB大小的数据块,计算出Hash值,转发给C模块。
3)C模块发现Hash值没有重复,所以插入自己的表,转发给D模块。
4)D模块给数据块分配SSD中的物理地址,写下去。
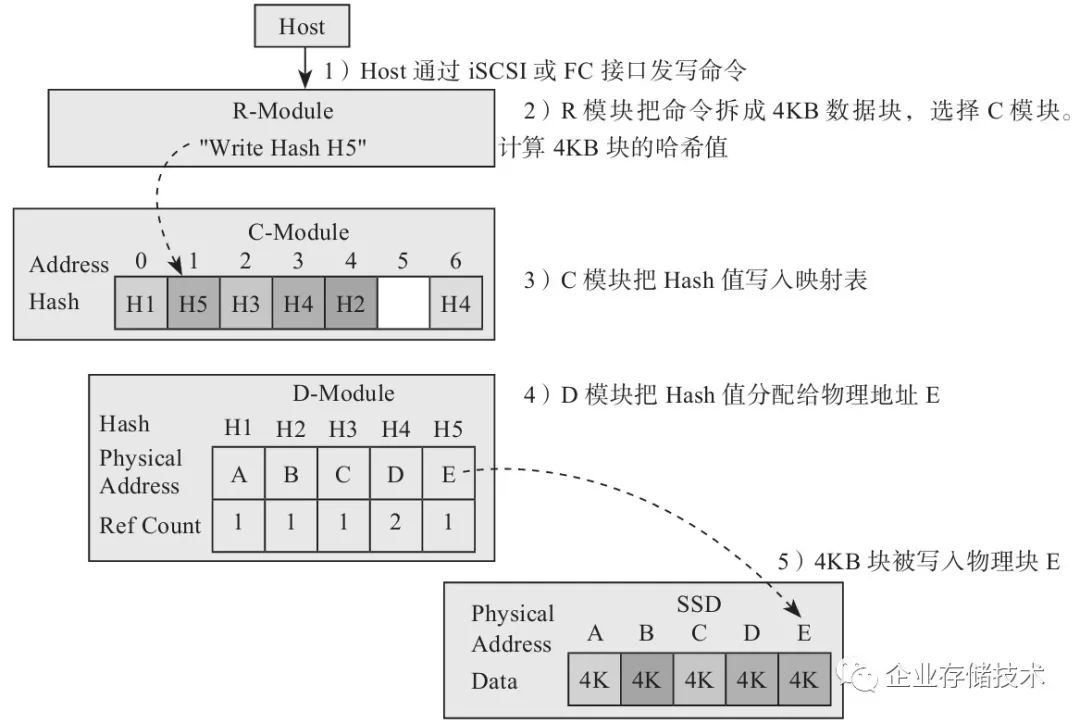
图2-29 不重复的写流程
4.可去重的写流程
可去重的写流程如下(见图2-30):

图2-30 可去重的写流程
1)主机把写命令通过FC或iSCSI接口发送给R模块,命令包含数据块逻辑地址和大小。
2)R模块把命令拆成4KB大小的数据块,计算出Hash值,转发给C模块。
3)C模块查A2H表(估计还有个H2A表,或者是个树、Hash数组之类),发现有重复,转发给D模块。
4)D模块知道数据块有重复,就不写了,只是把数据块的引用数加1。
可以看出,自动扩容和去重都是在后台自然而然完成的,不会影响正常读写性能。
我们可以畅想整合了文件系统inode表和SSD映射表之后,复制会很简单,只需要两个逻辑块对应到一个物理块就可以了,并不需要读出来再写下去。要知道自从全闪存阵列有了去重功能之后,复制这个基本的文件操作竟然如此简单:没有数据搬移,仅仅是某几个计数登记一下而已。下面我们细细道来。
5.ESXi和VAAI
首先我们来解释一下ESXi和VAAI两个名词。
VMware的虚拟化产品,就个人、小企业而言,有Workstation、ESXi(vSphere,免费版)、VMware
Server(免费版)可以选择,Workstation和VMware
Server需要装在操作系统(如Windows或Linux)上,ESXi则内嵌在操作系统中。所以ESXi可以看成是虚拟机平台,上面运行着很多虚拟机。
VAAI(vStorage APIs for Array Integration)是虚拟化领域的标准语言之一,其实就是ESXi等发送命令的协议。
6.复制流程
图2-31所示是复制前的数据状态。
复制流程(见图2-32)如下:
1)ESXi上的虚拟主机用VAAI语言发了一个虚拟机(VM)复制的命令。
2)R模块通过iSCSI或FC收到了命令,并选择一个C模块执行复制。
3)C模块解析出命令内容,把原来VM的地址范围0~6复制到新的地址7~D,并把结果发送给D模块。
4)D模块查询Hash表,发现数据是重复的,所以没写数据,只把引用数增加1。
这样复制完成了,没有真正的SSD读写。
不过有个问题是,这些元数据操作都是在内存中完成的,那万一突然掉电了怎么办?XIO设计了一套非常复杂的日志机制:通过RDMA把元数据的改动发送到远端控制器节点,使用XDP技术把元数据更新写到SSD里面。XIO的元数据管理是非常复杂的,前面讲的流程只是简单介绍而已。
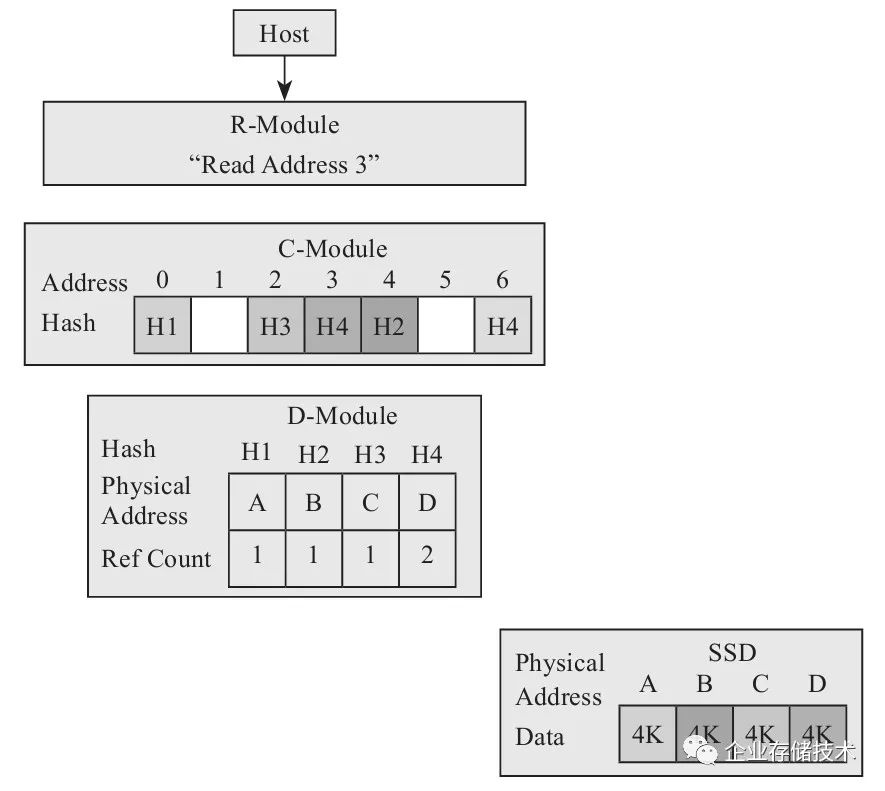
图2-31 复制前的数据状态
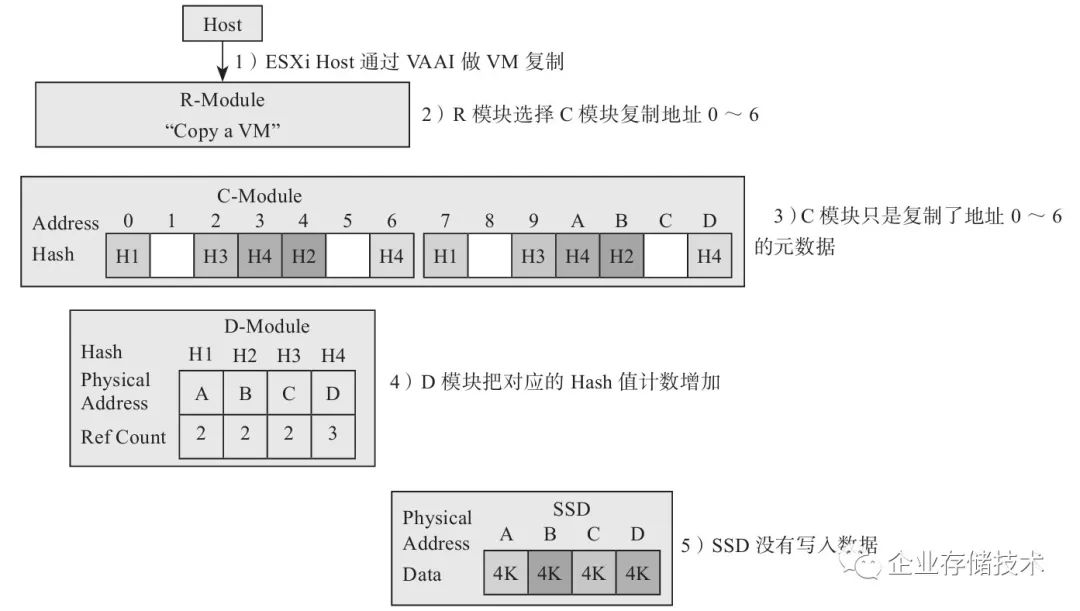
图2-32 复制流程
由于使用了A2H、H2P两张表,数据可以写到SSD阵列的任何一个地方,因为只跟数据的Hash有关,跟逻辑地址没关系。
最近网友们在热追中国高铁十三五规划,尤其是福建到台北的海底高铁更是令人震撼。短短十多年的时间,中国居然成为了世界第一高铁大国,乘坐高铁成为了大家城市间出行的第一选择。那为什么中国这么热衷于建设高铁呢?
人多!就是因为中国人口众多,而且稠密,基本集中在东部地区,比如京沪线,普通铁路的运力根本无法满足这么多人的需求,飞机也没办法拉完这么多人。高铁速度快,自然单位时间内能运载更多的人,交通效率更高。
在存储领域也是这个道理,全闪存阵列底层采用了闪存,所以速度很快,为了不浪费闪存的速度,上层的通信也需要非常高效。下面揭秘XIO全闪存阵列的内部通信。
7.回顾R、C、D模块
前文介绍了R、C、D三个数据相关的模块。
可以看出,R和上层打交道,C是中间层,D和底层SSD打交道,记住这个就可以了。
首先要搞清楚的是,这些模块物理上怎么放在控制服务器里面。前面说过,1个X-Brick的控制服务器有2个CPU,每个CPU运行一个XIOS软件。如图2-33所示,R、C模块运行在一个CPU上,D则运行在另一个CPU上。为什么要这么做呢?
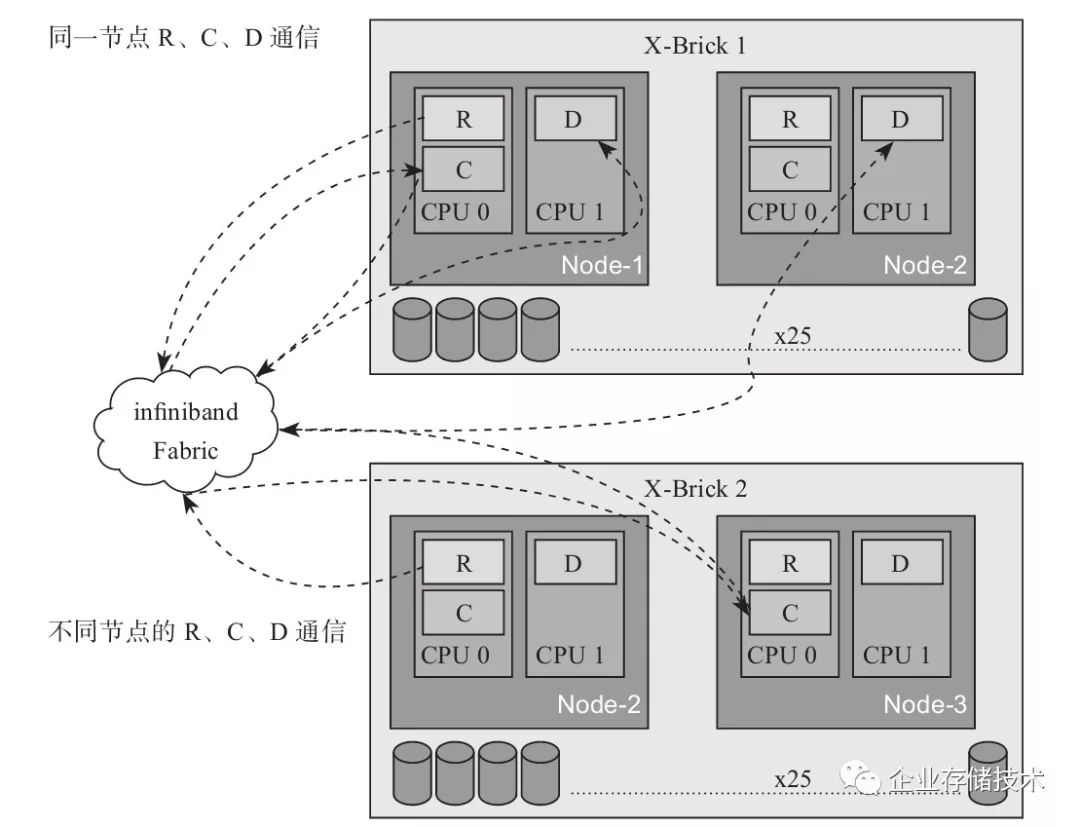
图2-33 X-Brick内部互联图
因为Intel Sandy Bridge CPU集成了PCIe控制器(Sandy Bridge企业版CPU集成了PCIe
3.0接口,不需要通过南桥转接)。所以,在多CPU的架构中,让设备直连CPU的PCIe接口,性能就会很高,而R、C、D的分布也是按照这个需求来设计的。例如SAS转接卡插到了CPU2的PCIe插槽上,所以D模块就要运行在CPU2上,这样性能才能达到最优。从这里,我们又可以看出XIO的架构上的优点,就是软件完全可以按照标准化硬件来配置,通过布局达到最优的性能。如果CPU的分布变化了,也会根据新的架构简单调整软件分布来提升性能。
8.模块间通信:扩展性极佳
我们再来说说正题:模块间如何通信?其实并不要求模块必须在同一个CPU上,就像图2-33所示一样,R和C并不一定要在一个CPU上才行。所有模块之间的通信通过Infiniband实现,数据通路使用RDMA,控制通路通过RPC实现。
我们来看看通信的时间成本:XIO的IO总共延时是600~700μs,其中Infiniband只占了7~16μs。使用Infiniband来互联的优点是什么?其实还是为了扩展性,X-Brick即使增加,延迟也不会增加,因为通信路径没变化。任意两个模块之间还是通过Infiniband通信,如果系统里面有很多R、C、D模块,当一个4KB数据块发到一个前端R模块上,它会计算Hash值,Hash会随机落在任意一个C上,没有谁特殊。这样一切都是线性的,X-Brick的增减会线性地导致性能增减。
2.6.5 应用场景
闪存价格现阶段还是比较昂贵的,尤其是企业级应用使用的eMLC或SLC,所以全闪存阵列XtremIO并不能取代大容量的存储阵列SAN。那它跟哪种应用场景比较般配呢?想想就知道了,闪存的优势就是延迟低、性能高,所以适用于容量要求不高,但是要求延迟低、高IOPS的应用,比如VDI(虚拟桌面基础架构,就是虚拟机)、数据库、SAP等企业应用。
数据库是非常受益的,为什么?首先是性能高,其次就是复制几乎不占空间,所以用户可以很方便、快速地为数据创建多个副本。
已经有人在一个X-Brick上运行了2500~3500个VDI虚拟机,而延迟在1ms以内。虚拟机很多数据也是重复的,毕竟每个系统的文件都差不多,所以去重也能发挥很大作用。
企业应用领域也有人使用XIO加速了关键应用。
总之,只要容量足够,那你的应用用起来肯定比以前快多了!
看完了整个全闪存阵列XIO的技术揭秘,我们发现其实XIO的核心还是在软件,因为硬件都是标准件,都是X86服务器、SAS接口的SSD。AFA到底有什么独特的地方呢?
相比SSD,它没有垃圾回收、Wear Leveling、Read Disturb等传统SSD的功能,因为这些都在SSD里面由主控搞定了。
相比传统阵列,它的特色是去重和RAID6每次写到新的地址的功能。
以前可能你也不知道全闪存阵列到底是怎么弄的,看完了这一节,相信你已经不觉得它神秘了。甚至可以这样看:U盘是一两个闪存芯片和控制器封装,SSD是很多U盘的阵列,全闪存阵列是很多SSD的阵列,只不过U盘是最差的闪存,SSD好一点,AFA用得更好。但是,每升一级,就是一次质变,应用场景也各不相同,软硬件架构要重新设计。
| 人生中,偶遇闪存类产品研发,摸爬滚打十余年,幸见其初起、发展到普及。主要从事SSD/UFS技术研发,包括: 固件、NAND Flash、接口协议和产品管理。
我想再扩大点讨论范围,包括与本文节选新书内容 “全闪存阵列” 相关的各种技术话题,以及对新书的任何疑问和建议都可以写出来。感谢广大读者朋友的支持!





