
Docker提供了一种将Linux Kernel中需要的内容静态链接到你的应用中的方法。Docker容器可以使用宿主机的GPUs,因此我们可以把TensorFlow或者机器学习代码的任何依赖都链接到容器中,这样其他小伙伴就可以使用你的工作成果了。
你可以发布一个可再现的机器学习项目,它几乎不需要用户设置,不需要用户花6小时去下载依赖或者报错:
# 6 hours of installing dependencies
python train.py
> ERROR: libobscure.so cannot open shared object
相反,你可以这样做:
dockrun tensorflow/tensorflow:0.12.1-gpu python train.py
TRAINING SUCCESSFUL
这种方法可以直接运行你的train.py脚本,所有的依赖包括GPU支持都帮你准备好了。
Docker容器是短暂的,不需要持久化任何数据,你可以把Docker容器想象成1G大的tensorflow.exe,它把你所有的依赖都编译进去了。
Why

开源软件因为有难以重现、复杂的依赖网络:不同版本的编译器、丢失头文件、错误的库路径等,所有这些导致在软件的安装配置阶段浪费你大量的时间。
使用Docker时,理论上你只要要让Docker正确工作,然后你所有的代码就可以运行了。幸运的是,Docker已经融资1.8亿美元,并将一部分投入到docker开发中,转换成可以工作的软件。
我打算在Linux上用Docker,Mac上的用法应该一样,除了不支持GPU。
应该怎么做
针对机器学习的使用场景,你最好把你的代码发布到GitHub repo上。你的依赖通常表示成一系列Linux命令行,这些命令行能复制粘帖到终端中运行。(译者注:即依赖放到Dockerfile中)。
Docker用一个命令替换第二部分(译者注:第一部分是把代码放到GitHub repo上,第二部分是在Docker镜像中执行命令行,配置你的依赖),该命令将拉取运行代码所需的正确docker镜像。你会把所有的依赖集成到3G大(压缩后)的镜像中,用户可以直接下载使用你的镜像。
我们看看Torch pix2pix的实现方式:
git clone https://github.com/phillipi/pix2pix.git
cd pix2pix
bash datasets/download_dataset.sh facades
# install dependencies for some time
...
# train
env \
DATA_ROOT=datasets/facades \
name=facades \
niter=200 \
save_latest_freq=400 \
which_direction=BtoA \
display=0 \
gpu=0 \
cudnn=0 \
th train.lua
尽管训练脚本的依赖很少(做到这样很伟大了),但是脚本使用的工具却有很多依赖,而且这些依赖文档不全面,组合在一个镜像中非常复杂繁琐。
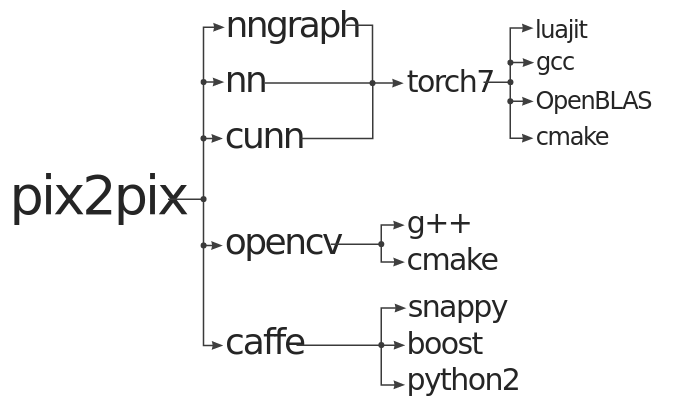
如果你不小心弄乱了依赖,可能会遇到下面的错误:
luajit: symbol lookup error:
/root/torch/install/lib/lua/5.1/libTHNN.so: undefined symbol: TH_CONVERT_ACCREAL_TO_REAL
Docker提供了一种方法,通过Docker Hub分发二进制镜像(译者注:原文是artifact)。
Dockerized
在Linux server上直接安装docker和nvidia-docker,Docker容器可以访问GPU,没有明显的性能损失。
如果你在Mac上你需要安装Docker for Mac(https://docs.docker.com/docker-for-mac/),在Mac上使用Docker我还是有很多经验的。现在你还不能在GPU上运行任何东西,Mac几乎不再支持CUDA。你可以在CPU模式下测试,它工作良好,只是有点慢。
我这里有一个在Ubuntu 16.04 LTS上安装Docker的脚本,适用于云服务提供商:
curl -fsSL https://affinelayer.com/docker/setup-docker.py | sudo python3
装好Docker后,运行pix2pix代码:
sudo docker run --rm --volume /:/host --workdir /host$PWD affinelayer/pix2pix
下面是完整的脚本,多行显示方便阅读:
git clone https://github.com/phillipi/pix2pix.git
cd pix2pix
bash datasets/download_dataset.sh facades
sudo docker run \
--rm \
--volume /:/host \
--workdir /host$PWD \
affinelayer/pix2pix \
env \
DATA_ROOT=datasets/facades \
name=facades \
niter=200 \
save_latest_freq=400 \
which_direction=BtoA \
display=0 \
gpu=0 \
cudnn=0 \
th train.lua
它会下载我构建的镜像(镜像包含Torch,支持nvidia-docker),大小在3G。
运行后会打印debug信息,到这里已经很棒了。但运行在GPU上更重要,因为pix2pix的架构设计在GPU上可以获得足够的训练速度。
GPU
在GPU上运行只需要把上面命令中的docker镜像替换成nvidia-docker。
nvidia-docker不包含在标准Docker中,所以你需要额外的工作。下面的脚本可以在Ubuntu 16.04 LTS上配置nvidia-docker:
curl -fsSL https://affinelayer.com/docker/setup-nvidia-docker.py | sudo python3
大概花费5分钟,而且我已经在AWS和Azure上测试过了。两者都是NVIDIA K80卡,额定值为2.9 FP32 TFLOPS。
nvidia-docker配置好运行:
sudo nvidia-docker run --rm nvidia/cuda nvidia-smi
假设上面的命令正常运行,重新运行pix2pix的脚本:
sudo nvidia-docker run \
--rm \
--volume /:/host \
--workdir /host$PWD \
affinelayer/pix2pix \
env \
DATA_ROOT=datasets/facades \
name=facades \
niter=200 \
save_latest_freq=400 \
which_direction=BtoA \
display=0 \
th train.lua
它使用相同的Docker镜像,但是支持GPU。
提示
使用Python和TensorFlow时,有许多有用的命令行选项:
--env PYTHONUNBUFFERED=x
这会让python立即打印输出,而不是先缓存起来。
--env CUDA_CACHE_PATH=/host/tmp/cuda-cache
这使得你每次启动Tensorflow时都没有1分钟的延迟,它必须从头重新编译CUDA内核。
这两个选项集成到Docker命令行中后:
sudo nvidia-docker run \
--rm \
--volume /:/host \
--workdir /host$PWD \
--env PYTHONUNBUFFERED=x \
--env CUDA_CACHE_PATH=/host/tmp/cuda-cache \
\
这个命令很长,你可以定义命令别名:
alias dockrun="sudo nvidia-docker run --rm --volume /:/host --workdir /host\$PWD --env PYTHONUNBUFFERED=x --env CUDA_CACHE_PATH=/host/tmp/cuda-cache"
定义别名后运行pix2pix-tensorflow(https://github.com/affinelayer/pix2pix-tensorflow):
git clone https://github.com/affinelayer/pix2pix-tensorflow.git
cd pix2pix-tensorflow
python tools/download-dataset.py facades
dockrun affinelayer/pix2pix-tensorflow python pix2pix.py \
--mode train \
--output_dir facades_train \
--max_epochs 200 \
--input_dir facades/train \
--which_direction BtoA
pix2pix-tensorflow除了Tensorflow 0.12.1(当时当前发布的版本)之外没有别的依赖关系。但是即使如此,第一个GitHub issue是一个用户使用错误版本的Tensorflow导致的。
如何集成
幸运地是,集成到你自己的项目中非常简单。
你先新建空目录,新建文件Dockerfile。然后构建镜像:
mkdir docker-build
cd docker-build
curl -O https://affinelayer.com/docker/Dockerfile
sudo docker build --rm --no-cache --tag pix2pix .
构建结束后你就可以查看镜像了:
sudo docker images pix2pix
REPOSITORY TAG IMAGE ID CREATED SIZE
pix2pix latest bf5bd6bb35f8 3 seconds ago 11.38 GB
通过docker push把你的镜像推送到Docker Hub上:
sudo docker tag pix2pix /pix2pix
sudo docker push /pix2pix
Docker新用户可以先使用我的镜像。docker提供了不依赖Docker Hub分发镜像的机制,但是他用起来不是很方便:
# save image to disk, this took about 18 minutes
sudo docker save pix2pix | gzip > pix2pix.image.gz
# load image from disk, this took about 4 minutes
gunzip --stdout pix2pix.image.gz | sudo docker load
再现性
虽然Docker镜像容易复制,但是从Dockerfile到镜像的转换不一定是可复制的。你可以使用下面的命令检查镜像的构建历史记录:
sudo docker history --no-trunc pix2pix
它不会显示被添加到镜像中的所有文件。比如,如果你的Dockerfile包含git clone或者apt-get update,很可能在两个不同的日子里构建产生不同的镜像。
另外,如果docker构建时指定了cpu版本,那么镜像在其它机器上很可能不工作。
只要我们分发的是Docker镜像,那么它就是可再现的。如果你想通过Dockerfile再现镜像,如果你不非常小心编写构建Dockerfile的话,很可能失败。(译者注:镜像构建好后不会变,可再现,但是从Dockerfile构建,很可能因为cpu版本、git clone仓库更新而不可再现镜像)
目前还不清楚这些优势是否值得付出努力,但是如果你的Dockerfile是从头开始构建的,并且使用--network none选项,大多数情形镜像是可重现的。
如果镜像再现很容易,这项技术将会很酷。现在Docker已经取得实质性进展,让依赖再现成为可能,这是伟大的进步。
译者说
这篇文章介绍了Docker与深度学习结合的例子。Docker的优势是解决了依赖的问题,方便分发个人工作成果;缺点是不直接支持GPU,需要开发者自己安装nvidia-docker。
文章最后作者论述了Docker镜像的可再现问题,总结如下:
分发的是Docker镜像,那么基本可以保证镜像的一致性(可再现)。
分发的是Dockerfile,Dockerfile中存在git clone或者apt update,会因为时间因素导致clone的repo更新导致镜像不一致。

【3天烧脑式微服务架构训练营 | 上海站】本次培训涉及:DevOps?微服务?需要解决的问题、回归、微服务那些事儿、Spring Cloud简介、服务发现:Eureka、客户端负载均衡:Ribbon、声明式的客户端:Feign、使用断路器实现微服务容错:Hystrix、微服务网关:Zuul、统一配置管理:Spring Cloud Config、微服务跟踪:Spring Cloud Sleuth、Spring Cloud常见问题总结等,点击下面图片即可查看具体培训内容。

点击阅读原文链接可直接报名。






