李杉 安妮 编译自 QZ
量子位 报道 | 公众号 QbitAI
2006年,李飞飞开始考虑一个想法。
当时刚刚出任伊利诺伊大学香槟分校计算机教授的她发现,整个学术圈和人工智能行业都在苦心研究同一个概念:通过更好的算法来制定决策,但却并不关心数据。
她意识到这种方法的局限——如果使用的数据无法反映真实世界的状况,即便是最好的算法也无济于事。
她的解决方案是建设更好的数据集。
“我们决定做一件史无前例的事情。”李飞飞说,她指的是最初与自己共事的那个小团队。“我们的对象是全世界的物体。”
由此制作的数据集名为ImageNet,它作为论文于2009年发布时,还只能以海报的形式缩在迈阿密海滩大会的角落里,但却很快成为了一场年度竞赛:看看究竟哪种算法能以最低的错误率识别出其中的图像所包含的物体。很多人都将此视作当今这轮人工智能浪潮的催化剂。
参与ImageNet挑战赛的企业遍布科技行业的每个角落。2010年的第一场竞赛优胜者都出任了百度、谷歌和华为的高管。马修·泽勒(Matthew Zeiler)利用2013年赢得ImageNet挑战赛时的程序创办了Clarifai公司,目前获得了4000万美元风险投资。
2014年,谷歌与来自牛津大学的两位研究人员共同赢得竞赛,这两个人很快就被谷歌招募,并加入了他们最近收购的DeepMind实验室。李飞飞本人目前也兼任谷歌云首席科学家、斯坦福大学教授及该校人工智能实验室主任等多项职责。
今天,她将登上CVPR的舞台,最后一次讨论ImageNet的年度结果——2017年是这场竞赛的最后一年。短短7年内,优胜者的识别率就从71.8%提升到97.3%,超过了人类,并证明了更庞大的数据可以带来更好的决策。
即便竞赛本身结束,它留下的遗产仍会继续影响整个行业。2009年以来,数十个新开发的人工智能研究数据集已经引入了计算机视觉、神经语言处理和语音识别等子领域。
“ImageNet改变了人们的思维模式:虽然很多人仍然关心模型,但也很关注数据。”李飞飞说,“数据重新定义了我们对模型的思考方式。”
什么是ImageNet?
1980年代,普林斯顿大学心理学家乔治·米勒(George Miller)启动了一个名叫WordNet的项目,目的是为英语建立一套体系结构。这有点像一本词典,但所有的单词都会按照与其他单词的关系来显示,而不是按照字母顺序排列。
例如,在WordNet里面,dog(狗)将放在canine(犬科)下面,canine则会放在mammal(哺乳动物)下面,以此类推。这种语言组织方式依赖的是机器所能读懂的逻辑,并由此汇集了超过15.5万个索引单词。
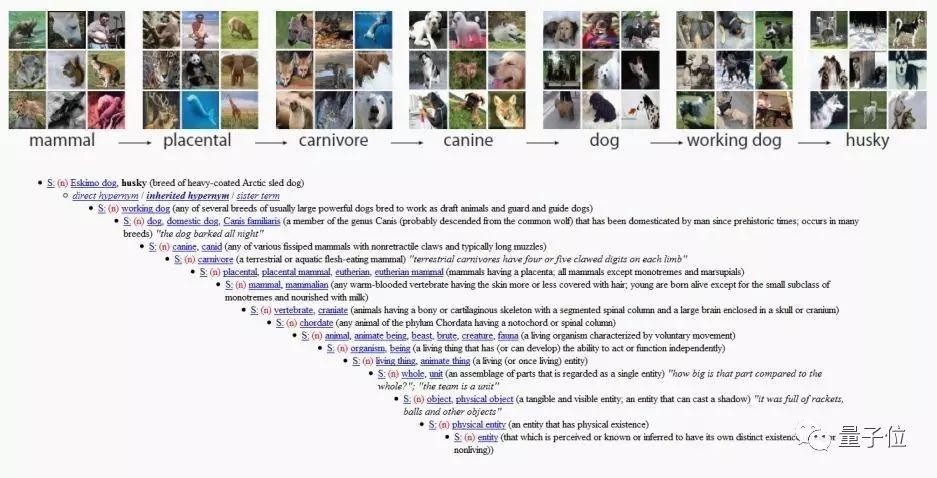 △
ImageNet的层级划分灵感来自WordNet
△
ImageNet的层级划分灵感来自WordNet
李飞飞在伊利诺伊大学香槟分校担任首份教职时,始终受困于机器学习的一个关键矛盾:过度拟合和泛化。如果一个算法只有碰到与其之前看到的数据相似的其他数据时,才能发挥作用,这个模型就被视作对该数据过度拟合。也就是说,它无法理解任何比这些例子更加普遍的数据。另一方面,如果一个模型不挑选数据之间的正确模式,就称之为过度泛化。
李飞飞表示,完美的算法距离我们似乎还很遥远。她认为,之前的数据集并没有体现世界的多样性——就算是识别猫咪的图片也是一件极其复杂的事情。但通过向算法呈现更多例子,使之了解世界的复杂性,那么从数学意义上讲,的确可以起到更好的效果。如果你只看过5张猫咪图片,那就只有5个拍摄视角、光线环境,可能也只看过5个品种的猫。但如果你看过500张猫咪图片,那就可以有更多的例子来得出它们之间的共性。
李飞飞开始研究其他人是如何利用数据体现世界多样性的。在这一过程中,她找到了WordNet。
研究过WordNet的方法后,李飞飞在2006年访问普林斯顿时,找到了一直从事WordNet研究的克里斯蒂安·菲尔鲍姆(Christiane Fellbaum)。菲尔鲍姆认为,WordNet可以为每个单词找到一张相关的图片,但主要是为了参考,而不是建设计算机视觉数据集。通过那次会面,李飞飞设想了一个更加宏大的想法——组建一个庞大的数据集,为每个单词都提供更多例子。
在李飞飞到她的母校普林斯顿大学任职几个月后,便在2007年初启动了ImageNet项目。她开始组建团队来应对这项挑战,先是招募了另外一名教授Kai Li,他随后又说服博士生Jia Deng转到李飞飞的实验室。Jia Deng此后一直协助运营ImageNet项目,直到2017年。
“在我看来,这与其他人所作的事情非常不同。”Jia Deng说,“我明确感觉到这会改变视觉研究领域的运行方式,但我不知道具体如何改变。”
数据集里的物体既包括熊猫和教堂等实物,也包括爱情这样的抽象概念。
李飞飞的第一个想法是以每小时10美元的价格雇佣本科生手工寻找图片,然后添加到数据集中。但她很快发现,按照本科生收集图片的速度,大约需要90年才能完成。
在解散了本科生图片收集小组后,李飞飞和她的团队重新回归算法。能否让计算机视觉算法从互联网上选取图片,人类只负责验证图片的准确性?但经过几个月的研究后,他们认为这项技术同样不可行——未来的算法也会受到局限,只能达到制作数据集时所具备的识别能力。
聘用本科生浪费时间,使用算法存在瑕疵,雪上加霜的是,该团队还缺乏资金——李飞飞说,虽然她四处申请,但那个项目未能获得任何联邦政府拨款。甚至有人说:普林斯顿竟然研究这个课题真是令人感到耻辱,而李飞飞是女性则是这个课题的唯一优势。
当李飞飞跟一个研究生聊天时,事情突然有了转机。那个研究生当时问李飞飞,她有没有听说过亚马逊Mechanical Turk,那项服务可以聘用世界各地的很多人坐在电脑前面通过在线方式完成一些简单的任务,收费也很低。
“她给我看了网站,我可以告诉你,就是在那一天,我知道ImageNet肯定能够实现。”她说,“我们突然之间找到了一款可以扩大规模的工具,如果是聘用普林斯顿的本科生,根本无法想象可以做到这一点。”
 △
亚马逊Mechanical Turk的图像分类界面
△
亚马逊Mechanical Turk的图像分类界面
Mechanical Turk本身也面临一些障碍,很多工作都要由李飞飞的博士生Jia Deng和Olga Russakofsky来解决。例如,每张图片需要多少人过目?或许两个人就能确定猫是猫,但小型哈士奇可能需要经过10轮验证。如果某些参与该平台的人试图欺骗系统该怎么办?李飞飞的团队最终针对Mechanical Turk参与者的行为开发了一批统计模型,确保数据集中只包含正确的图片。
即便是在找到Mechanical Turk后,仍然花了两年半时间才完成这个数据集。其中包含320万张经过标记的图片,共分成5,247种类别,还包含“哺乳动物”、“汽车”和“家具”等12个子树。
2009年,李飞飞和他的团队发表了ImageNet的论文,还附带了数据集——但并未大张旗鼓地展开宣传。李飞飞回忆道,作为计算机视觉研究领域的顶尖会议,CVPR只允许他们发一张海报,不能进行口头宣传。于是,该团队通过向人们赠送ImageNet品牌的钢笔来吸引关注。当时的人们很怀疑通过更多数据就能改进算法这样一个简单的道理。
“当时有人说,‘如果连一个物体都做不好,为什么要做几千个、几万个物体?’”Jia Deng说。
如果说数据是新时代的石油,那么在2009年,它还只是恐龙的骨头。
ImageNet挑战
2009年,在京都一个计算机视觉会议上,同是参会人员的Alex Berg拉住李飞飞,提议大赛中额外加入用算法定位图像目标的任务。
李飞飞想了想说,不如你加入我们吧。
就这样,Berg、Jia Deng和李飞飞三人用这些数据集撰写了五篇文章,想弄清用算法怎样解释这些庞大的数据。其中第一篇论文还成为用算法给图片分类的标准,也就是ImageNet的前身。
“我们意识到,如果想把这个想法大众化,我们还需要走得更远些。”李飞飞在第一篇论文中写着。
随后,李飞飞奔赴欧洲找到备受瞩目的图像识别大赛PASCAL VOC,对方同意与她合作,并帮助宣传ImageNet。PASCAL有高质量的数据集,相较于ImageNet,PASCAL只有20个目标类别。
随着比赛的进行,到了2012年,PASCAL成为衡量分类算法在当时最复杂的图像数据集上的表现的一个基准。




