 欢迎点击上方订阅本公众号。
欢迎点击上方订阅本公众号。
导读
本文为CCSGR研究员、上海社会科学院新闻研究所助理研究员方师师和黑龙江大学新闻传播学院院长、教授郑亚楠的《计算知识:人工智能参与知识生产的逻辑与反思》一文摘要,获取全文请参阅刊发杂志
。
本文从知识表示与推理KR²的视角来反思人工智能参与知识生产,揭示其系统逻辑、实现目标与社会意义。KR²是人工智能的底层逻辑,它致力于以计算机系统来表示世界和解决复杂任务。本文认为,基于知识库和事实规则逻辑的KR深刻影响了人工智能作为一种中介化的媒介形式所进行的知识生产,这样生产出的知识是一种“计算知识”,特点是具有一种“膨胀的知识感”:它依赖知识聚集,具有强自反性,是一种集体性的真实,但缺乏知识创新所必要的批判性。

就“人工智能对社会的影响”,一个颇具启发性的观点是:“人工智能对于社会的真正价值在于其是否可以实质性地取代人类进行知识生产”。
这一点非常重要且关键,可以带来经济奇点、创新实践和社会生活领域的重构。当我们把计算机作为一种“媒介”时,数字化、虚拟化和交互主动性是需要研究的现象。戴维•温伯格从媒介的视角对于人类数千年来既有的知识形态进行过一个分类梳理,认为人类发展至今,知识的形态存在“三阶”——即物理知识,媒介知识和混乱知识。其中物理空间的实体——“物品”对应着物理知识,“纸张”对应着媒介知识,而超越自然实体的“数字媒介”对应着混乱知识。而对于“混乱知识”,他敏锐地指出,
“现在我们亲眼看到,知识并不存在于我们头脑里,知识存在于我们之间;它从公开和社会的思想中浮现,并且存在于此。因为社会认知,就像创造了它的全球对话一样,是永无终点的。”
温伯格试图通过构建这样的一个“三阶”知识体系推进对于既有知识体系的建构认知,虽然他所给出的这样的一种“三阶知识”依然是一个静态的分类体系,但他指出了知识形态的几个重要因素:第一,知识的形态不是固定不变的。随着“媒介”形态的变化,会出现新的知识表现形式;第二,知识具有主体间性。知识并不是一种主体对客体的固定化的认知,而是一种随着场景与语境不断变化的互动过程;第三,知识可以被再生产。知识可以通过不同的形式再生和浮现出来,并且知识的结构并非都是显性且条理分明的。

当前在新闻传播领域,“算法”和人工智能对于内容的接入,已经成为一个世界性的潮流。基于算法和人工智能所进行的“内容推荐引擎”服务,对用户接收必要的知识并有效地重新利用知识具有重要的影响;社交媒体可以通过提供交互式协作技术在隐性知识的分享过程中发挥作用;人工智能拥有从巨大且复杂的信息源中提取、识别和构建体系的能力,在那些任务目标明确且相关数据丰富的领域,以深度学习为代表的算法能够让机器学习新的技能,制定有效策略,从而在短时间内提出超过人类现有的学习能力和知识体系,给出创新式的问题解决方案。
如果我们顺着温伯格的媒介与知识形态的思路而下,这是否意味着,人工智能也可以算作是一种新的媒介形态?
而关于知识是如何生产出来的,1997年Banhlme等人提出的“知识演化模型”认为:知识体系是不断演化的,知识体系进化的动力来源于环境的新需求,新的解决方案对环境的适应性会传承至下一代,并不断累积直至达到适应性的极点。2018年,Agrawal等人从魏兹曼的观点出发,认为知识生产在很大程度上就是一种“对原有知识的组合过程”。
那么由人工智能参与的社交媒体上进行的内容聚合和分发,会产生新的知识么?如果假设这是一种继“混乱知识”之后另外一种新的知识形态,又会具有怎样的特点与特征?

二、知识表示与推理KR²:人工智能的底层逻辑及其构建
西格弗里德•J.施密特(Siegfried•J. Schmidt)曾经从社会结构主义的视角将人们熟悉的把传媒当作“间歇性”和“中介”的观点相关联,认为“认识和传播在范畴上是可分的,因此也是独立的;但是传媒却保证了这两个领域之间长期的结构上的耦合。”这一耦合不能理解为直接的连接,而应该理解为文化的作用。而正是在传播、认识、文化和传媒维度之间的不断循环,才产生了“实在”的对象,也就是我们所说的知识。
在人工智能领域,知识表示与推理(Knowledge representation and reasoning, KR²)是一种致力于以计算机系统来表示世界、解决复杂任务的结合形式。
它结合了心理学的研究成果,在引入人类如何表达知识和解决问题的同时,通过设计来呈现知识,进而构造出使复杂系统更容易处理和构建知识的方式。知识表示和推理包含了各种自动化表示查询结果和进行逻辑推理的过程,其表现形式包括语义网(semantic nets)、系统架构(systems architecture),框架语言(frame language),规则(rules)和本体(ontologies),实例则包括自动推理引擎,定理证明和分类器等。
作为人工智能基础底层架构的知识表示与推理是一种“技术人造物”,它可以对知识进行改造和再生产。
在这个过程中,“技术逻辑”既是一种生产工具,也是一种逻辑架构,更是一种关系形态。被结构化了的事实和规则会“推理”出确定可重复的结果,并满足一种可被验证的真实感与确定感。
知识表示实际上是一种“中介化”的概念,是对知识本体的一种重新度量。
它并不诉诸于在本体意义上的真正的知识内容是什么,而是追求一种形式化的表现方式。它通过结构性的规则与逻辑,将一系列要素组织和串联起来,以实现系统的目的要求。而当系统达到某个阈值的时候,规则和逻辑无法再适应要求,就存在更改结构和规则的可能。但是这种变化既不是没有条件的,也不能无限度地使用。知识表示如同一种知识本体的“技术形态”,决定了知识能被“认知”的程度与可
能。如果我们说媒介从一定程度上是人类认识世界的逻辑框架,那么知识表示实际上也是这样一种逻辑构成,并且更加具有人工参与的痕迹。

2006年,Gruber提出了一类称为“集体知识系统”的应用,它利用语义网的知识表示和推理技术来解锁社交网的“集体智能”。如果说社交网站是一个参与的生态系统,其价值是由许多个人用户贡献的总和来创造,那么语义网是一个数据生态系统,价值是通过整合来自多个来源的结构化数据来创造。
如何将这两者结合起来这一想法在2018年Gruber等人申请的谷歌算法专利中得到充分的体现,在这份叫做《为满足用户需求的信息众包》(Crowd sourcing information to fulfill user requests)的专利中,数字助理或虚拟助理系统像个人助理一样,执行请求的任务,并提供建议、信息或服务。数字助理系统对用户请求产生满意响应的能力取决于系统实现的自然语言处理(包括文字、声频、视频等)、知识库和人工智能。而在任何时候,数字助理都可能受到其特定实现方式的限制,无论这种实现方式多么复杂,还是不能避免对用户的请求产生不令人满意的响应,甚至还会出现意料之外的情况。

2018年5月8日,在谷歌I/O开发者大会上,谷歌CEO桑达尔•皮查伊(Sundar Pichai)展示了一款AI助手,它可以替代人类打电话预约理发、订餐等,能够理解无序的对话,记住并完成自己的核心任务,“不被带偏”。在整个对话过程中,谷歌助手仿佛真人一样,不仅对场景应付自如,甚至可以说出“嗯哼”这样的口语,而人类接线员却错误百出。虽然事后有分析指出,谷歌展示的AI助手实际可以应用的场景非常有限,而且也不清楚这样的对话的成功率是多少,但这一技术就是构成“集体知识系统”的语义网、深度学习和语言转文字领域的一次现实应用。
从数据到信息,再到知识和智慧,这是一个螺旋上升的过程。
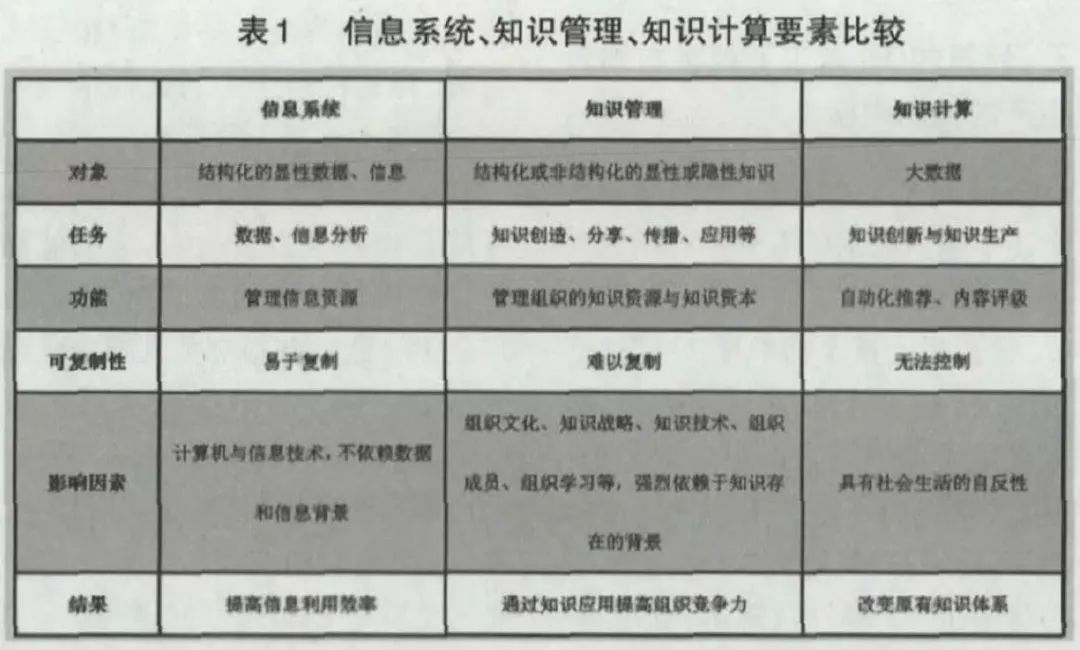
从知识表示与推理视角来看,人工智能参与的知识生产就是一种基于知识库和规则事实逻辑的“集体知识系统”,是包含搜集、处理、生成、匹配、推荐为一体的某种“实在的对象”的生产系统。比照计算机科学领域的术语,我们把这样一种形态的知识生产称为“知识计算”,其生产出的知识是一种“计算知识”。如果将数字时代的知识按照信息系统、知识管理、知识计算的形态进行一个粗略的划分和比照,我们可以得到表1。
科学知识社会学认为,秩序与知识是一体两面的,改变知识就是改变秩序。计算知识目前仍然处于初级阶段,但同之前的“三阶”知识相比,
计算知识建构了一种新的知识——文化秩序,我们把它称为“膨胀的知识感”——“你知道的和你认为你知道的之间的界限变得越来越模糊”。
一方面,
出于对数据、算法、算力的要求,知识计算不断关注于自身系统的可扩展性,这种可扩展性使得整个系统更为关注数据和信息处理的效率,而不是表示的充分性;
另一方面,
知识计算也是一种传播过程,传播产生了社会知识,同时在传播中通过可参与性经验又确证了这一知识。语言表达并不指向“实在”,而是指向集体知识的构建,并在交往过程中不断膨胀。交往中继承下来的生产性结构和真实性的确证,是一种集体性的真实。这种特征不仅体现在计算知识本身的属性上,还体现在社会层面和个体感知上。

与传统的知识创新类似,人工智能进行知识生产首先依赖于“知识聚集”,具体体现在大规模地对机构化和用户数据的占有、挖掘和再生产。
以YouTube为例,YouTube是基于谷歌大脑系统(Google Brain System)的一种深度神经网络(Deep Neural Networks),属于目前最为主流的弱人工智能的发展前沿,代表了该行业目前规模最大、最先进的推荐系统。深度神经网络以套嵌式的多层次模式识别系统组成的“神经”架构为基础,通过组合低层特征形成更加抽象的高层属性、
类别或特征,借以发现数据的分布特点。深度神经网络推荐系统被广泛用于推荐新闻、引用和内容评级。
YouTube的视频推荐算法其核心任务和设计目标在于处理和应对三大挑战:数据规模(scale)、数据新鲜度(freshness)和噪音(noise),这样的生产方式高度依赖数据的结构性特征。在YouTube运作的前期,主要通过训练已有的数据来弥补缺乏用户使用满意度、隐含反馈缺失等问题。在未来,系统的可扩放性(scal
ability)则是发展的远期目标。

但另一方面,这样方式生产出来的知识更多的是一种“形式化的内容”。
2017年,Hosseini等人(2017)设计的一种自动视频分析算法用来检测谷歌云视频的API。该研究提出了针对两类基本视频分析算法的攻击方案,即视频分类和镜头检测,通过巧妙的操作,人类观察者可以感知原始视频的内容,但视频分析算法会返回对手所需的结果。实验通过镜头更改(视频内的场景更改)和镜头标签(随时间推移描述视频事件)的方式修改视频内容,API接收视频文件并返回视频标签(视频内的对象),结果显示,API是通过处理视频每秒的第一帧来生成视频和镜头标签。
因此,攻击或者操纵者可以通过定期将图像以每秒一帧的速率插入视频来欺骗API,以仅输出期望的视频和镜头标签。实验还显示API返回的镜头变化模式大部分可以通过比较连续帧直方图的算法来恢复。
该研究从反面说明了YouTube的视频推荐算法机制更加注重的是系统效率而非内容本身,即知识形式而非知识内容。

在YouTube上,用户不仅仅是进行内容生产,更多的则是一种对于公共空间(common space)的参与,用户内容生产(user-generated content, UGC)的要义不在于浏览量或者阅读量,而是触发了更多的相互反应。
在YouTube上大受欢迎的内容,不但需要具有一定的技术水平,同时还要符合网站和社会的价值观念和文化规范。这样一来,一方面出现了市场化和非市场化内容生产的两类。
YouTube具备成为文化公共空间的潜质,但是由于网站本身处于谷歌资产的复杂框架下,其天然的广告驱动收入模式和对于用户数据的占有和支配,使得其是否可以算是一种“公共媒体系统”,始终处于争议的核心;另一方面,即便是非市场化的内容,也存在“私人的公开化”(publicly private)和“公共的私人化”(privately public)的现象:即在YouTube上进行内容生产的主体,为了发展和维护社交网络,会通过物质性和阐释性的双重方式,或者暴露身份但是限定内容的传播范围,或者将公共性的内容进行私人化表述。这样的形式带来的后果是,对于YouTube平台上的内容,其公私边界不再清晰,来源、真伪、价值都不再重要,取而代之的是是否能够激发、维持和协商社交互动。由于当前人工智能参与的知识计算,其核心目标是持续不断卷入更多在线时间、用户数据和金钱资本,本身缺乏批判性和反思性,因此其创新程度还非常有限。
(图片来自网络)
作者
方师师
复旦发展研究院传播与国家治理研究中心 研究员
复旦大学新闻学博士、社会学博士后
上海社会科学院新闻研究所助理研究员
本文刊载于《新闻与写作》2018年第12期。
本文由作者授权发布,未经许可,请勿转载(个人转载不在版权限制之内)。如公开出版机构需转载使用,请联系刊发杂志及作者本人获得授权。
方师师,郑亚楠.计算知识:人工智能参与知识生产的逻辑与反思[J].新闻与写作,2018(12):40-47.






