
概要 :MIT训练AI将图像、声音和文字匹配起来
来源:36Kr
看到汽车跟听见引擎响是一回事。
从单项能力来说,现在的AI已经很先进了,比如说AI能识别我们说的话,照片里面的对象,下棋能胜过人类冠军等等。但是就像交互设计之父Alen Cooper所说那样,计算机能识别你说的话,但它可能不懂你的意思。为什么?上下文语境、背景等信息对于理解意思和意义是非常重要的。如果我们希望未来的机器人执行我们的命令的话,就必须让它们能彻底理解周围的世界——如果机器人听见了狗叫,它要知道是什么导致了狗发出叫声,那条狗是长什么样的,以及它想要什么。
过去的AI研究注重的是单项突破(感知世界和执行任务方面)。可以想象一下,如果你一次只能使用一种感觉,不能管将你听到的东西跟看到的东西进行匹配的话会是什么感觉?这个就是AI的现状。但是要解决深层次的问题,就需要将这些单项的成功进行统合。幸运的是,目前MIT 和Google
的研究人员已经在开展这方面的探索。这两家机构最近发表了相关论文,解释了其在协调AI进行看、听和读方面的初步研究,这些成果有望颠覆我们教机器了解世界的办法。
MIT的AI博士后Yusuf Aytar是论文的联合作者之一,他说:“你是看到了汽车还是听见了引擎并没有关系,你马上就能识别出这事同一个概念。你大脑中的信息已经自然地把它们协调统一起来了。”

MIT训练AI将图像、声音和文字匹配起来
协调正是研究的关键。研究人员并没有教算法任何新东西,而是建立了一种方式让算法将一种感觉获得的知识与另一种进行连接或协调。Aytar举了一个无人车的例子,比方说无人车的声音传感器可能会先听到救护车的响声,然后激光雷达才看到救护车(视线受阻)。有关救护车的鸣叫声、样子以及职能的知识可以让无人车放慢速度,切换车道,给这辆车腾出地方。
为了训练这套系统,MIT的研究小组首先给神经网络展示了与音频相关的视频帧。在神经网络发现了视频中的对象并且识别出特别的音频之后,AI就会尝试预测哪一个对象跟声音关联。比方说,招手会不会发出声音呢?
接下来,研究人员把带有标题的类似情况下的图像提供给同一个算法,这样它就能够将文字与对象和图中的动作关联起来。想法跟前面一样:首先网络会单独识别出图中所有的对象以及相关问题,然后进行匹配。
乍看之下这种网络似乎没什么了不起,因为AI独立识别声音、图像、文字的能力已经很了不起了。但当我们对AI进行声音/图像、图像/文字的配对训练时,系统就能在未经训练指导哪个单词与不同声音匹配的情况下将声音与文字关联起来。研究人员宣称,这表明神经网络对于所看到的、听到的或者读到的东西已经形成了一种更加客观的看法,而这种看法的形成并不是完全依赖于它用来了解这一信息的媒介的。
能够统合对象的观感、听觉以及文字的算法可以自动将自己听到的东西转化成看到的东西。比方说,算法听到斑马在叫的时候,它会假设斑马的样子类似于马(在不知道斑马样子的情况下):
它会知道斑马是一头动物,它会知道这头动物会发出这类的声音,并且自然地将这一信息在不同形态间做转化。
这类假设使得算法会在想法之间建立新的连接,强化了算法对世界的理解。
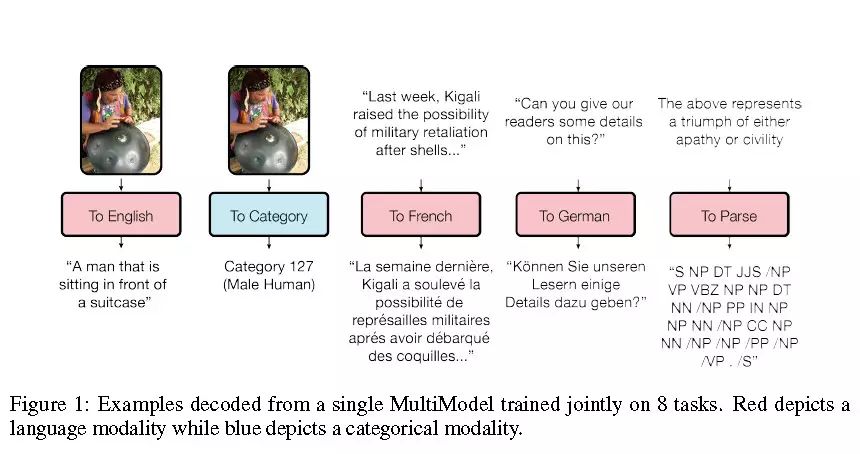
Google用一种深度学习模型来处理多领域的任务。图中红色是语言类任务,蓝色为分类任务。
Google也进行了类似的研究,不过Google更强一点的是它还能够将文字转化成其他的媒体形式。但是从准确率来说这些技术还比不上单用途的算法。不过Aytar的看法很乐观,他觉得这种情况不会持续太久:
如果你有了更多感觉的话,准确率就会更高。
来源:36Kr





