想必2016年的美国大选是有史以来最奇怪的一次大选,而近期纸牌屋里的大数据分析走进现实,让我们重新将目光聚焦在社交网络和大数据分析已经成为助力美国大选不可或缺的渠道和工具。早在08年大选中,奥巴马的竞选团队就让人们见识到了社交网络在竞选中的力量,并且在上任后不再是端正的总统先生,而是“不正经”的表情包奥巴马。奥巴马之于社交网络,就如肯尼迪之于电视。据估计,2016年预计竞选广告费用总计114亿美元,其中有5亿美元会投放在社交媒体上。社交网络上的数据分析,会帮助构建选民的用户画像,画像会帮助指导竞选广告应该投放在哪些网站的哪些年龄层次、哪些偏好的用户身上,这也是精准营销与广告计算的应用领域。
说到社交网络,这个虚拟世界和现实世界的桥梁,不同的社交网络承载着不同的特质。Facebook/微信是基于朋友之间的强关系网络,有助于朋友之间的联系与关系维系;Twitter/微博/豆瓣是基于单向关注的弱关系社交网络,有助于消息的传播和塑造意见领袖;Linkedin是面向工作的职业社交网络,帮助商务交流与求职招聘。这些社交网络每天都会产生大量的用户数据(UGC,User Generated Content),会吸引大量的研究者、商业人员和广告投放商来对这些用户数据进行研究。
对于社交网络的分析和研究范围很广,也存在着许多有意思的研究课题。例如,在社交网络中社区圈子的识别(Community Detection)、 基于好友关系为用户推荐商品或内容、社交网络中人物影响力的计算、信息在社交网络上的传播模型、虚假信息和机器人账号的识别、基于社交网络信息对股市、大选以及互联网金融行业中的反欺诈预测等。社交网络的分析和研究是一个交叉领域的学科,所以在研究过程中,我们通常会利用社会学、心理学、信息论、新闻传播等多种学科基本结论和原理作为指导,通过人工智能领域中使用的机器学习、数据挖掘和图论等算法对社交网络中的行为和未来的趋势进行模拟和预测。
今天我们主要来介绍下社交圈子的识别,也称作社区发现算法。
其实说到社交圈子,不得不提一下社交网络中的推荐算法,比如说人人网中的好友推荐、应用推荐、个性化推荐(用户偏好、用户兴趣)等,主流的推荐方法是协同过滤、内容过滤,再有就是基于图的方法,也就是这里介绍的通过社交圈子识别后,在社交圈子内为用户做推荐,这时候的准确率和效率都会提升。发现社交圈子作为社会网络分析中一个重要的基础研究,它揭示了社交网络最核心的人与人之间的关系,而且每个人根据与他人关系的不同以及兴趣的不同可以属于多个社交圈子。映射到数据层面来分析用户的亲密度的话,可能会包括共同好友数目、个人资料相似程度、用户互动频度和用户的兴趣。
从学术的角度来阐述这个问题的话,往往会将整个社交网络看作是一个图的结构,每个用户就是图中的节点,人与人之间的关系就是节点之间的边,根据不同类型的社交网络,所构成的图可以是有向图也可以是无向图,关系的强弱也可以利用边上不同的权重来体现。社交网络也是复杂网络的一种,复杂网络是复杂系统的抽象,现实世界中的万维网、食物链、基因网、交通网络、电力电路网络等等都可抽象为复杂网络。对复杂网络的研究一直是许多领域的研究热点,复杂网络有三大特性,无尺度分布(scale-free distribution)、小世界效应(the small-world effect)和强社区结构(strong community structure)。
在大规模网络中,结点的度服从幂率分布(power law distribution)。在社交网络中,结点的度可以理解为一个人连接的朋友的个数。结点的度服从幂率分布,也就是说大部分结点有很低的度,而少数结点有非常高的度。在重对数尺度下,度分布近似线性。由于分布的形状不随尺度而改变,也称为无尺度分布。
所谓小世界网络,在日常生活中有些你觉得遥不可及的人,也许你的朋友就认识他;或者一个陌生人却与你有相同的朋友,会让你感慨“这个世界好小”。用图论来解释的话,小世界网络就是一个由大量节点构成的图,任意两点之间的平均路径长度要远远小于节点数量。其中最被人熟知的就是六度分割理论,即通过不超过六个人就能串联两个人的社交关系。如果你上Facebook的话,Facebook上的15.9亿人中间,仅隔着3.57个朋友而已。
复杂网络的第三大特性,强社区结构,引导我们认知到有别于规则网络和随机网络的真实社交网络是拥有社区结构的,社区内节点与节点之间的关联关系相交于社区与社区间的关联关系更加紧密,也就是说一个社交圈子中的成员之间互动会很频繁,两个社交圈子之间成员之间的互动频率会远远低于一个社交圈子内的互动。对于社交圈子的发现算法来说,社交圈子的质量依赖于圈子内成员的关系的紧致度以及不同圈子间的分离度。
聚类算法可以用于解决社区发现算法的问题,K-means等聚类算法可以充分利用社交网络中的联系的强弱、频繁程度、以及互动的文本内容,可以从更深的层次和视角来研究人与人之间的关系,来研究社区划分,来实现真实场景下的社交圈子识别。K-Means算法的思想是初始随机给定K个聚类中心,按照距离最近原则把待分类的样本点分到各个聚类,然后按平均法重新计算各个聚类的质心,从而确定新的聚类中心,迭代计算,直到聚类中心的移动距离小于某个给定的误差值。使用算法描述语言,只要三个步骤:
-
任意选择K个点作为初始聚类中心;
-
计算每个样本点到聚类中心的距离,将每个样本点划分到离该点最近的聚类中去;
-
计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心。
-
反复执行2、3,直到聚类中心的移动小于某误差值或者聚类次数达到要求为止。
聚类和社区发现算法之间最大的不同在于,社区发现中的点被网络连接到了一起,而聚类中的数据点并没有构成网络。所以,在使用K-means算法来发现社区之前,需要先定义好网络中点之间的距离,也可以理解为节点与节点之间的相似度。有三种方法,分别是相同的邻居数,交往的频繁程度和交往内容的情绪色彩。相似度定义好之后,就可以使用K-means算法了。另一个需要考虑的地方就是K-means算法需要预先设定聚类初始节点,在社区发现的场景中,可以选取一些网络中比较重要的节点,例如度比较高的节点,也就是连接边较多的节点,这样的节点更可能是一个社团的中心。
然而实际的社交圈子是一个更为复杂的网络,因为用户会具有多种兴趣,可以属于多个社交圈,发现这种圈子的研究也被称为重叠社区的发现。一种比较简单的启发式方法是,以网络中度很大的节点作为初始的圈子,然后把对圈子贡献最大的邻接节点依次加入到圈子中,直到全局贡献度达到极值,并形成一个圈子。如果存在对多个圈子贡献度都很大的边界节点,则将其加入到多个圈子中。
贡献度的计算方法有很多,最简单的是计算节点与圈子相连边个数与圈子内边个数之比,另一种常用的衡量圈子划分质量的指标是
模块度(modularity),由Newman提出的。模块度不仅仅作为优化的目标函数提出,它也是目前是最流行的用来衡量社区结果好坏的标准之一,它的提出被称作社区发现研究历史上的里程碑,这是第一次对社区这个模糊的概念提出了量化的衡量标准。模块度是基于一个思想,社区是节点有意识地紧密联系所造成的,它内部边的紧密程度总比一个随机的网络图来的紧密一些,它表示所有被划分到同一个社区的边所占的比例,再减除掉完全随机情况时被划分到同一个社区的边所占的比例。模块度越大,社区结果越明显。例如工业界优化最多的Louvain算法,初始化每一个节点作为一个社区,通过计算模块度收益来合并社区,并且重复这个过程直到模块度无收益为止,得到社区划分结果。然而,模块度优化问题已经被证明是有解法限制的,尤其是针对大规模网络和较小社区的网络,但仍然有非常多的学者在研究基于模块度的社区发现算法。
但对于数以亿计的节点来说,目前的圈子发现算法还很难处理特大规模的数据,因此很多研究者提出了启发式的方法去减少程序处理的复杂性,对最终结果进行近似的求解。近期使用标签传播算法(Label Propagation Algorithm)来解决重叠社区的发现算法逐渐走上科研舞台。
这是一个非常快速且易于扩展的社区发现算法,被广泛应用与大规模网络的社区发现,主要思想是用网络结构来指导社区结构的发现。算法LPA的思想非常简单。网络中的每个节点都有一个标签,经过标签的迭代更新,最终标签一致的节点作为一个社区。这种方式,紧密连接的节点群组会有一个一致的特殊标签,由此快速的构成一个社区。由于算法LPA是近线性的算法,时间复杂度低,并且易于扩展适应于大规模的社区发现。
LPA算法的改进算法SLPA,是基于Speaker-listener模型的标签传播算法,模仿了信息传播的过程,就像人们热衷于传播那些经常热门讨论的信息。借助于SLPA算法的思想,我设计了改进算法HLPA,不会忘记上一次迭代中节点所更新的标签信息,给每个节点设置了一个标签存储列表来存储每次迭代所更新的标签。最终的节点社区从属关系将由标签存储列表中所观察到的标签的概率决定,当一个节点观察到有非常多一样的标签时,很有可能这个节点属于这个社区,而且在传播过程中也很有可能将这个标签传播给别的节点。更有益处的是,这种标签存储列表的设计可以使得算法可以支持划分重叠社区。并且不同于SLPA算法的是,HLPA重新设计了标签传播机制,SLPA为同步更新每一个节点的标签,同步更新模式会导致摇摆现象,而单纯的异步更新模式会导致每次的社区划分结果都会很不同,所有HLPA采用了一种同步+异步的一种混合更新模式。首先,将图的边排列成两边节点的模式,这样可以消除更新过程中摇摆现象。在每次迭代过程中,采用同步更新的方式来更新每一边的节点标签列表。最后,基于存储标签列表中的标签进行后期处理,使用阈值r用于输出社区结果集和。
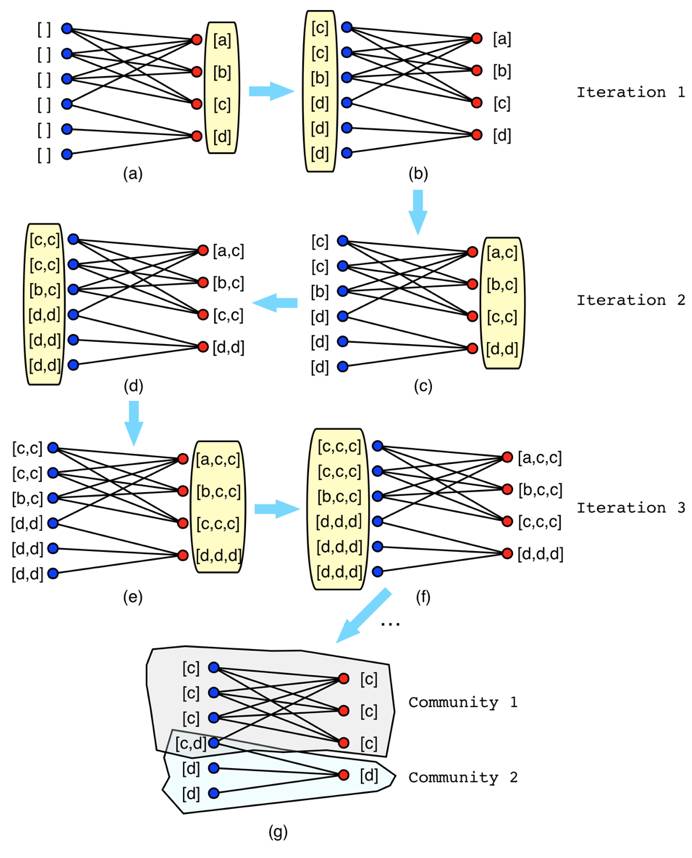
图1 标签传播算法HLPA中混合更新模式
社交圈子发现算法并不仅局限在用户主动建立起的关系上,其更重要的价值在于对用户非显性的潜在关系发现。从社交圈子发现的结果中,我们能够更加清楚地看出属于一个圈子的人群。比如,喜爱MacTalk的同学也有可能喜欢Smartisan手机,喜欢看小道消息的同学估计也会喜欢吃海底捞。社交圈子还能帮助我们分析信息是如何传播的,例如微信朋友圈中的信息流,都是通过我们的关系圈逐层向外传播的,我们所看的的消息也直接来自我们所关心的人,更外围的消息也必须逐层传播才能接触到我们。与传统媒体依靠内容作为传播的主题形式有所不同,社交网络上的信息传播,更加依赖于发布者的影响力以及社会关系,通过好友或粉丝的关系将信息扩散到社交网络中,这种信息在社交网络中会被好友及粉丝看到,并以一定的概率被分享和转发,从而进行传播。
其实大家一定好奇,线上的圈子与线下的真实社交圈子是否是一致的?当两个人在社交网络中互动很频繁时,他们在线下是否也是真实的好友?答案是算法很智能,但还没有这么智能,不过还是有迹可循的。其实,我和池大的认识也是从线上开始,直到某一次技术交流大会才很古老的互留了手机号(虽然从来没打过)。但一旦我们互相存了对方的手机号,那么从数据的角度来说我们是真实好友的可能性就非常大了。包括微信、Linkedin、telegram、band等产品,如果真的能够做好基于手机通讯录的社交网络,我们就可以通过异构的社交网络对社交圈子进行综合性的判断,其价值不可估量。
后记:这是一篇旧文,如果没有池大的督促就没有这篇文章。感谢~
请我喝杯咖啡吧~






