
作者简介:

方伟
eBay中国研发中心 资深软件工程师
2010年加入eBay,一直在系统平台部负责设计和开发工作。最初负责整个eBay的数据库应用层的开发和优化;接着从事用户行为数据的收集,数据管道的建立以及部分数据分析工作,是开源项目PulsarIO的主要贡献者之一;
目前致力于 eBay 的实时数据传输和计算平台,基于 Kafka 和 Storm 等开源软件。对建设高可用,高扩展性,并且可自动化运维的分布式系统有丰富经验。
前言
本文主题是我们最近一年做的,基于 Kafka 做的企业级数据传输平台,我们实现这个平台,以及这个平台最终上线并在对它运维过程中,得到的心得体会和经验教训。
这是本文主要分四部分:
-
eBay数据传输平台概述
概述我们的数据传输平台,包括我们为什么搭建这个平台,这个平台到底是什么,主要技术架构是什么。
-
平台核心服务
对此平台当中核心服务,做一些稍微详细一点的描述。
-
系统监控与自动化
这个平台上线之后,我们怎么样对它做监控,以及我们花了一些力气在运维自动化上,减少运维人员人工处理。
-
Kafka 性能优化
Kafka 性能优化和性能提升方面,我们做了哪些系统调整,使得 Kafka 有比较好的性能去运行。
1、eBay数据传输平台概述
1.1 为什么要搭建传输平台
首先是平台的概述,什么是数据传输平台,我们为什么要搭建这个平台。
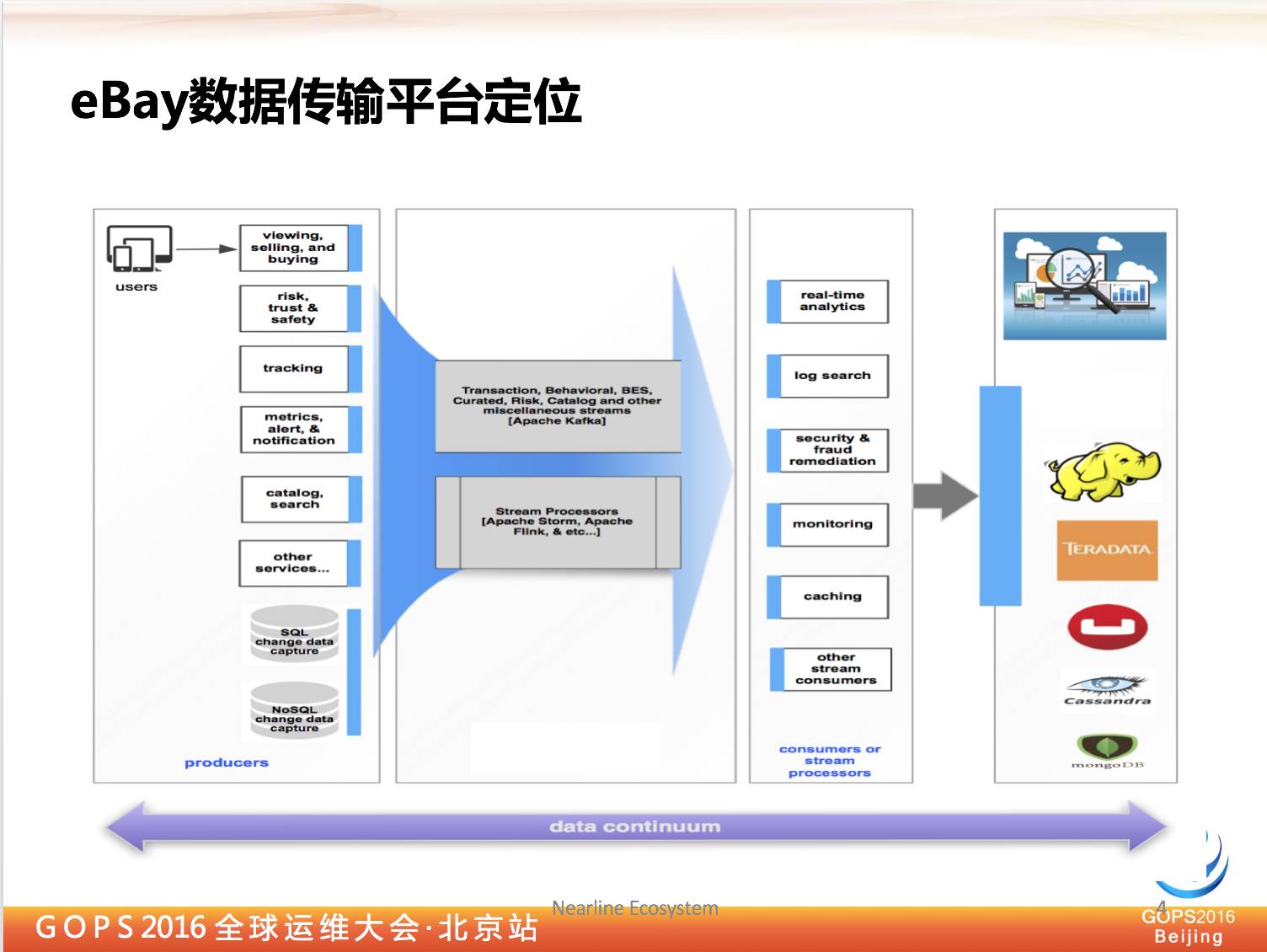
其实在互联网企业当中有很多系统,一般来讲我们可以把互联网当中各个系统分成两类:
一类是在线系统
,在线系统是直接跟用户打交道的站点系统,比如对于电子商务网站来说,我们有商品浏览,商品搜索。我们有卖家发布商品,我们有商品发布系统。
另一类是离线系统
,离线系统最主要的比如我们做BI分析,站点报表,包括财务方面的报表,以及用户行为的分析,离线系统里我们一般有一些产品,比如大数据,最近我们会用 hadoop 做一些数据挖掘。
其实离线系统这些数据最终来源也是从在线系统来的,那我们怎么样从庞大在线系统中,把数据传输到离线系统,这就是我们需要解决的问题。
对于 eBay 来讲,它的在线系统肯定有好几万台,比如我们要采集用户行为,系统里有好几个 PB 的关系型数据库存储,我们要从数据库当中,把数据库变化传输到后台离线系统当中,怎么做呢?
近年来,对实时计算的需求越来越多,很多比如像欺诈检测,像用户个性推荐,这种类型的系统,都要求实时性,我不想等到一夜过后这个数据才过来,我希望马上拿到数据,能够进行计算,得到计算结果,然后反馈到其他在线系统。
在这种情况下,我们需要一个实时平台,把数据从在线系统传输到离线系统,所以这就是我们为什么要搭建这个传输平台。
1.2 为什么要用Kafka
我们为什么要用 Kafka ,这里不对 Kafka 做过多介绍,说一下我们看中了 Kafka 哪些点,我们为什么会最终选用 Kafka 做数据传输平台。
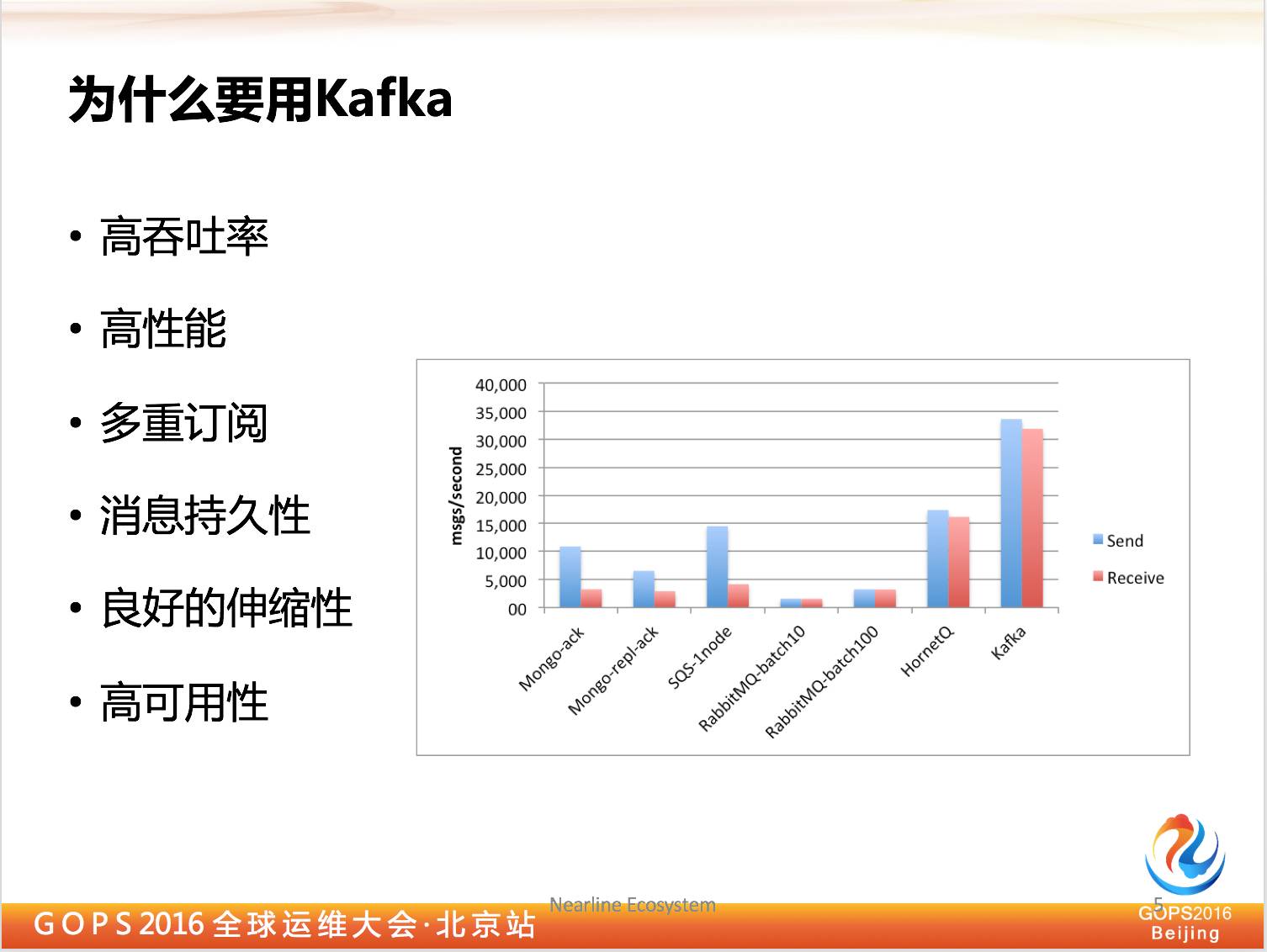
其实我们数据传输平台是很典型消息中间件,消息中间件市面上有很多产品,为什么要用 Kafka 呢?
-
高吞吐率
Kafka 的优势主要是在这几个方面,首先最大的优势是在于高吞吐率,对于其他消息中间件来说, Kafka 基本上可以秒杀其他消息中间件的吞吐率。
-
高性能
它还有许多其他很好的性能,在保证高吞吐率的情况下,它的传输性能也是比较好的,我们说的传输性能主要是数据传输上的,比如端到端的可以达到毫秒级的。
-
多重订阅
除此之外,它该支持多重订阅,这是它做得比较好的地方。
-
消息持续性
同样它保证了消息持续性,也就是进入 Kafka 所有数据,在任何一个时刻都可以回溯一下,前期是这个数据没有被破解掉。
除此之外它也有很好的伸缩性,你增加 Kafka 节点,处理是直线性增长的,同时也可以保证高可用性,像 Kafka 一些节点宕掉的话,不会影响到数据完整性。
1.3 Kafka的处理能力
既然选用了 Kafka ,那么 eBay 在 Kafka 上有多少数据呢?我们大概放了哪些数据在 Kafka 上呢?

目前我们大概有三十多个 Kafka 集群,这些 Kafka 集群主要建立在 eBay 自己的私有云上面,我们基于 OpenStark 搭建的自己私有云,所以我们 Kafka 的节点都是虚拟机。
我们总共有800多台虚拟机,在这些集群里我们总共有1200多个应用跑在上面,这些应用总数加起来超过2.5万个,每天消息达到1000亿次以上。所以这个可以看出这是很典型的大数据实时传输的例子。
那我们为什么要分这么多 Kafka 集群?
这个非常类似数据库的分库,我们基于业务垂直划分 Kafka 集群,比如所有用户行为,用户点击、搜索、对商品的浏览等等用户行为,我们同样会放到 Kafka 集群里,对于所有数据库变化,比如当一个卖价要修改一个价格,这个数据变化我们会放在 Kafka 集群里。
比如还有一些站点,本身自己想发出一些业务事件,比如当一个商品成交了,这些业务事件我们会放在另外一个基于 Kafka 的业务集群了。
我们知道 LinkedIn 是最初提出 Kafka 的,他们应该有60多个 Kafka 。
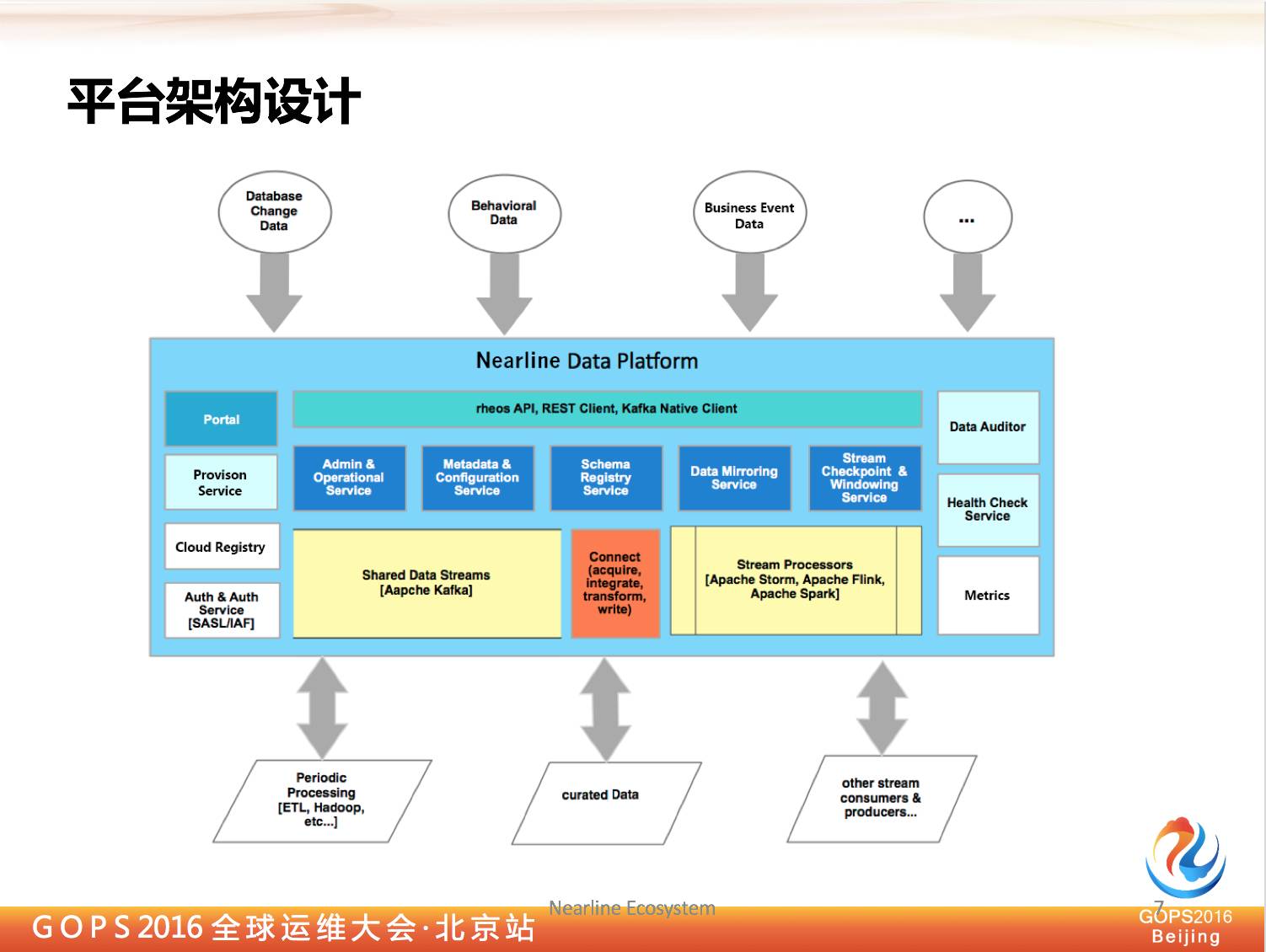
那我们有 Kafka 这样的开源产品,我们是不是可以直接拿来用呢?不需要做任何事情呢?
当然不是,其实 Kafka 提供的是单元功能,作为企业应用来讲,你要做企业实时传输平台解决方案,需要基于 Kafka 做很多额外服务,每个企业总归该是有一些自身需求,比如企业对安全考虑,每个企业实现方式不一样,企业数据中心分布也是不一样,对于不同企业自身的需求,我们需要做一些额外服务支持它。
eBay 做了哪些服务呢?举一些很简单的例子,比如我们想让一个用户在集群上创建他自己的 Kafka topic,你不是直接让他到一个节点上,这显然是不够安全,同时也不够方便。
这样我们必然要有一个提供管理功能的服务器,我们希望提供一个统一的入口,以及统一的 topic 名称空间,那么我们就需要引入原数据中心的服务。
比如我们在上海、北京都有数据中心。我们怎么把数据从上海迁到北京,这时候就需要有数据镜像服务。
再比如我们刚刚讲到,整个 Kafka 集群是在 openstack 云上面,当我们需要建立一个新集群的时候,或者一片集群需要修复,或者为这个集群需要新增节点,或者废弃节点的时候。
我们需要怎样调用 openstack 功能完成?同时我们还有很多监控功能的服务,系统日志服务。
我们都是把所有服务通过界面形式暴露出来,同时把它的下端用户直接到界面上做一些事情,不用非要找到系统管理员才能做,他们可以自己直接做。
2、eBay平台核心服务
以上是我们这个系统拥有的一些服务,下面我会就这个系统里面的服务做稍微详细一点的介绍。
2.1 元数据服务的目的
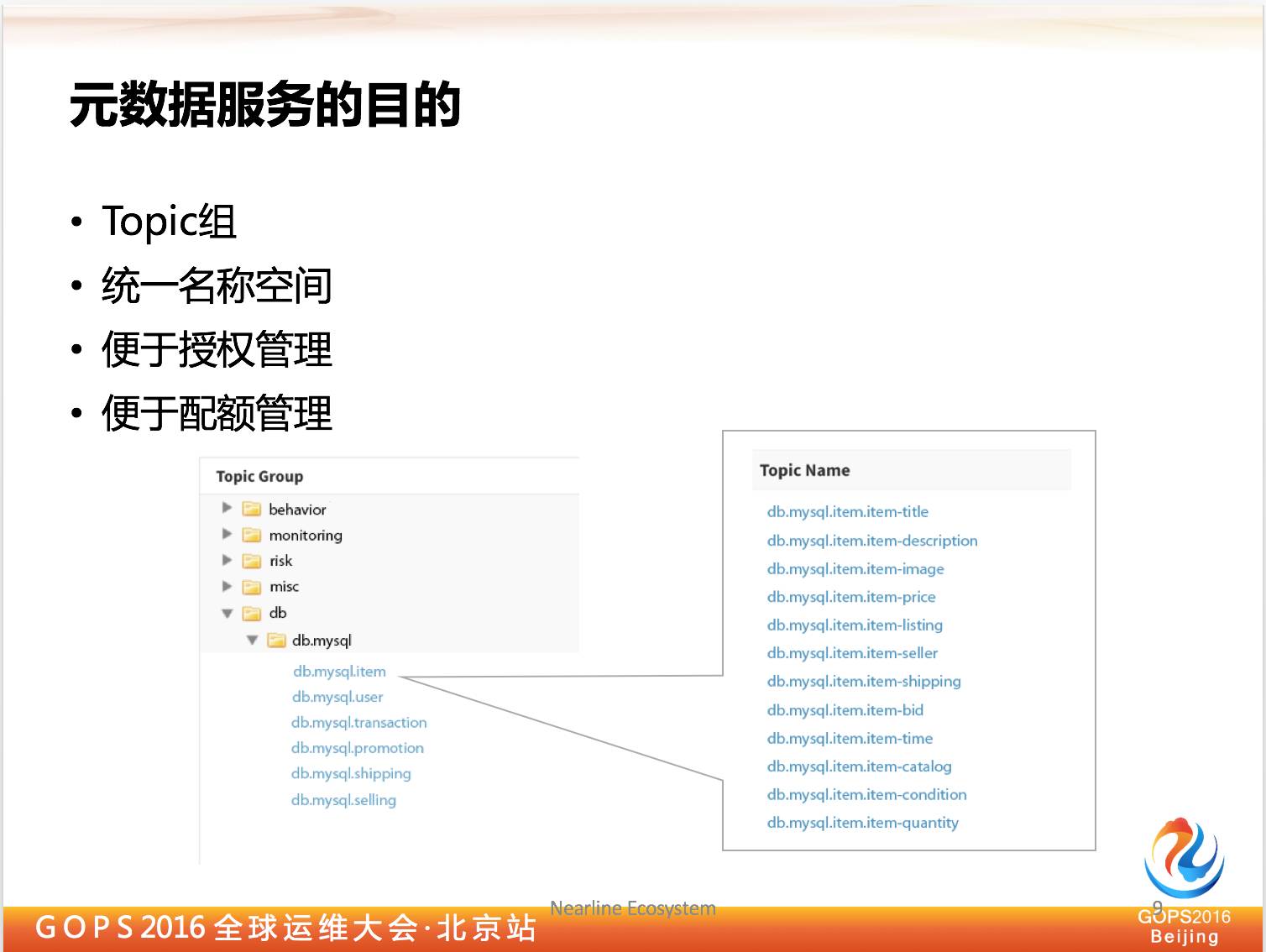
首先是元数据服务,为什么要提出元数据服务,因为我们希望给大家逻辑上提供一个统一的 topic 名称空间,比如我希望访问到用户行为数据,如果我们没有这个服务的话,我必须要让用户知道你的用户行为的 Kafka 集群在哪里,还要知道你连到哪一个。
然后 topic 名称是什么?比如我们从服务里面直接查询一个用户行为,你直接找到这个 topic,服务后面会找到真正的 Kafka 集群在哪里,然后再返回给客户端,让它连上来。
除了提供统一名称空间之外,我们还提出了叫做 topic 分装的概念,为什么会有这种东西呢?
因为我们刚才说到自服务,我们希望用户自己创建,如果说让它无限制创建的话,对系统资源肯定是伤害,因为它不知道你有多少资源还在那边,如果他创建太多了,会把 Kafka 集群宕掉。
这时候就需要有配额管理,我们这边引入的单位就是 topic 组,我们创建 topic 的时候需要系统管理员做审批。
一旦审批通过了,我会给 topic 组分配一些配额,比如我在上面创建多少 topic,在上面发生的网络带宽是多少都可以配置。所以这个也是便于后面的运维管理。
2.2 元数据服务
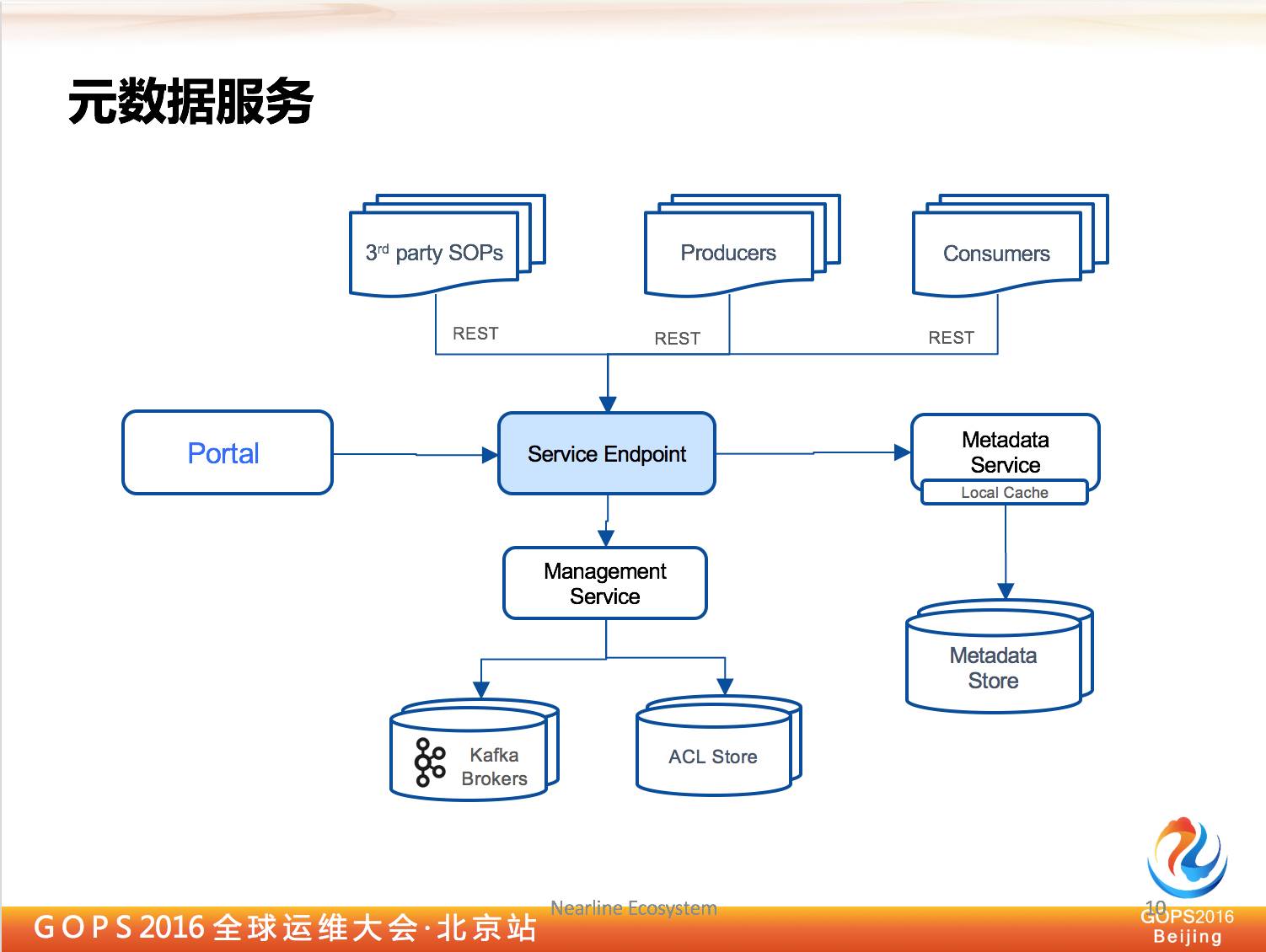
刚才我说了这些,都是要由元数据服务提供,那元数据服务怎么工作的呢?
在 Kafka 集群里,你不可能用这些集群本身所带的管理 topic 去管理元数据,所以我必须要有元数据存储。
2.3 Kafka代理
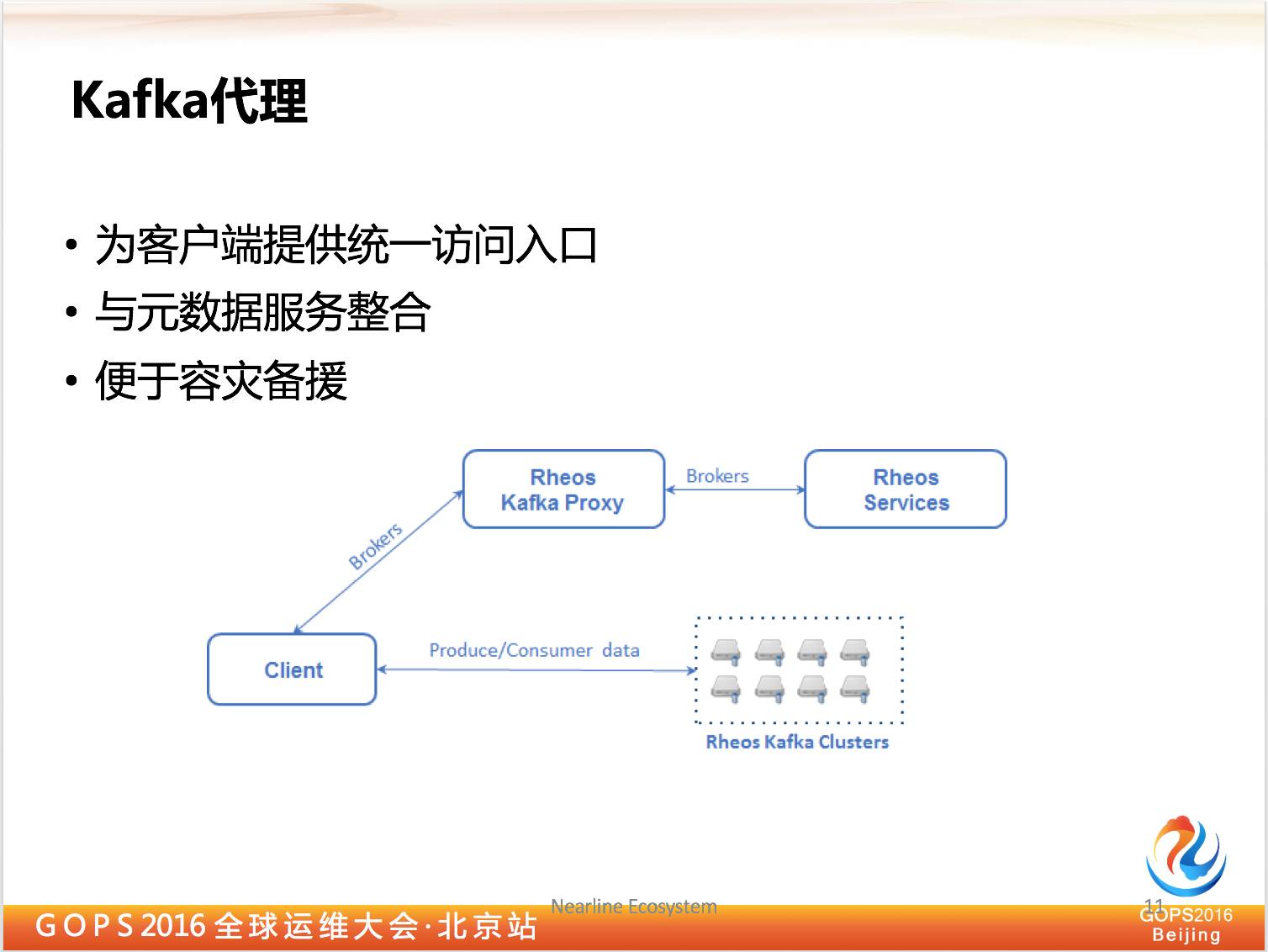
我们引入了逻辑层对三十多个集群看起来就像一个集群,在这种情况下,用户是不是在使用 Kafka API 的时候有问题,因为 API 并不能知道你要用哪一个。
我们看这个 Kafka 代理完全实现了 Kafka 的协议,这个协议定义了很多操作,这些操作是基于 TCP 层的。
我们去这样一个代理,可以完全模拟 Kafka 本身 group 的协议。对于客户端来说,是可以用原本 Kafka 的 API 访问,这个 API 连接代理就像连接到单独的 Kafka 集群一样,这其实不是一个真正的 Kafka 集群,而是后面带了三个 Kafka 集群。
2.4 Tier-Aggregation模式和数据镜像服务
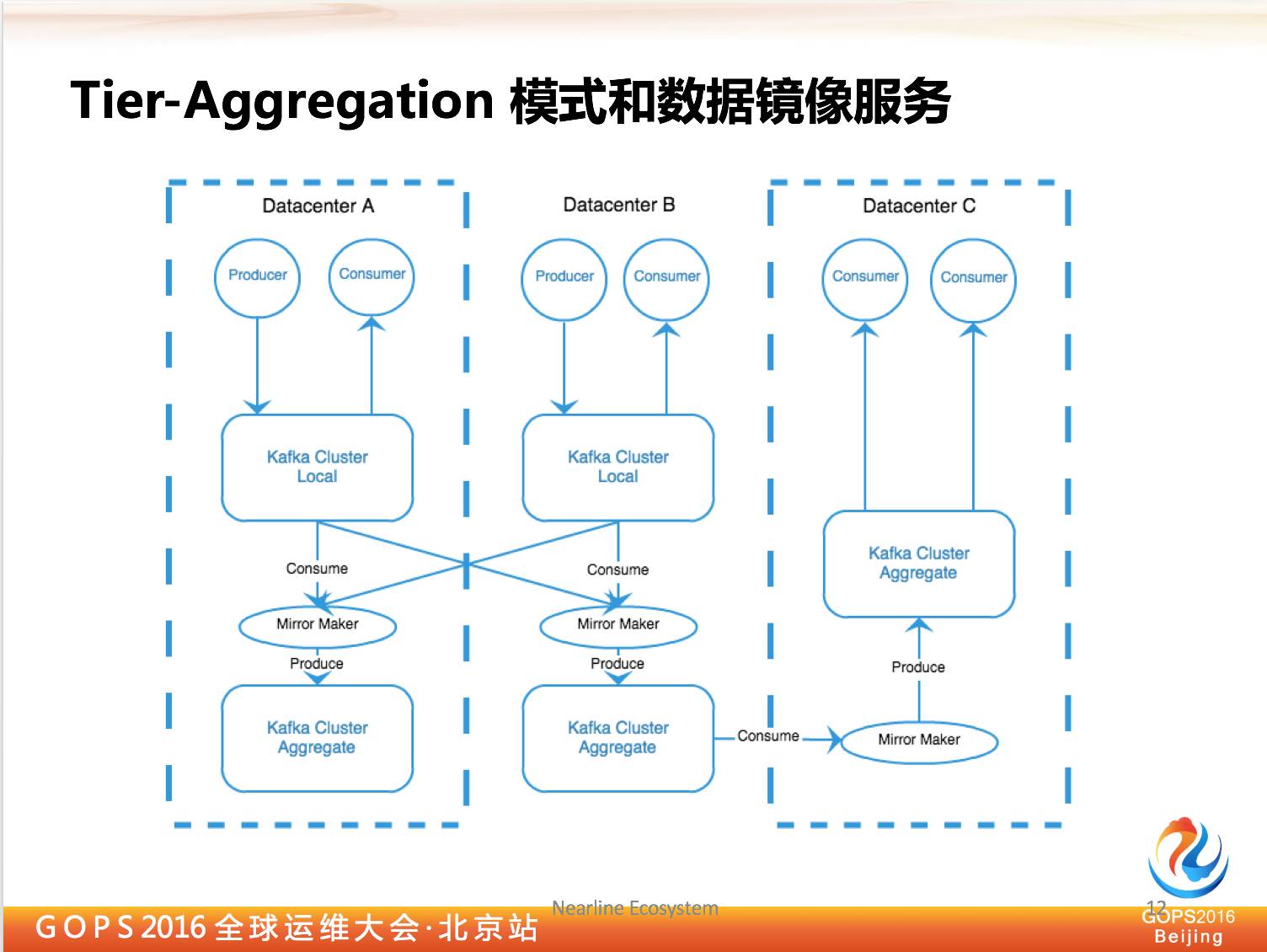
下面讲一下我们镜像服务,其实我们有多个数据中心, Kafka 数据来源本身也是来自数据中心。那么我们大家怎样搭建 Kafka 集群呢?
这里我们有一个模式 Tier—Aggregation,比如上海和北京都有用户行为。我们希望做数据分析的时候,要能够同时分析到上海、北京的数据,我需要把两个地区的数据 run 起来。
比如我们只有两个数据中心,我们创建四个 Kafka 集群,其中有两个 location 的数据。
我们同时也做到跨数据中心的数据冗余,比如北京数据中心烧掉了,我们上海数据中心依然可以把所有数据拿出来。
这个其实最是也是由 LinkedIn 提出的比较推荐的方式,虽然引入了很多数据冗余,但是它保证了它的运行。
因为 Kafka 本身有自己的 location,每个数据来了以后会引起三份网络流量,这个网络流量是为了让 Kafka 集群高可用。
如果 Kafka 集群跨数据中心的话,所谓的网络流量就会是跨数据中心,我们怎么把数据一个数据中心传输到另一个数据中心,这就是需要用到镜像服务。
镜像服务这方面其实我们会有很多管理,比如我多少开多少节点,多少线程,怎么启动,怎么截止,所有管理工作我们都需要有具体服务做这样的事情,也就是我们所说的镜像服务,要实现具体的服务,但是它暴露出一个服务器,让上层应用再去做数据镜像的管理。
3.5 Schema注册服务
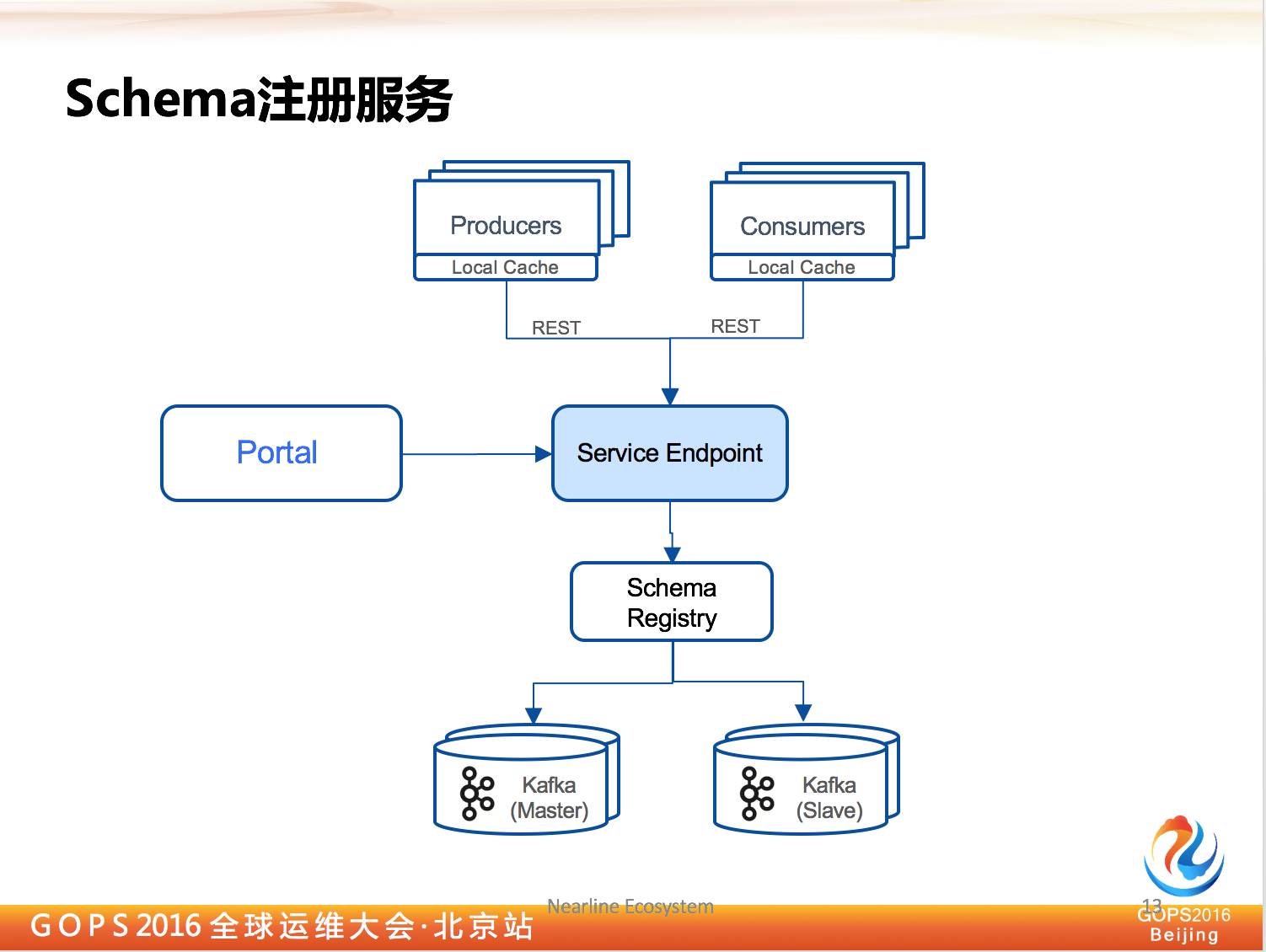
除此之外我们还有 Schema 注册服务,对于普通平台来讲,所有经过平台的数据都是可以进行管理的,我要求数据格式所有人都认识,所以我们定义了统一数据模式在平台里。
Kafka 本身提供了 Schema 组件,背后用 Kafka 做存储,而且高可用也做到了,我们是直接把它拿过来用,但是没有百分百拿过来用。
因为它有一定的局限性,比如它不支持健全,所有人都可以来改,所有人都可以进行版本增加。
2.6 用户自服务
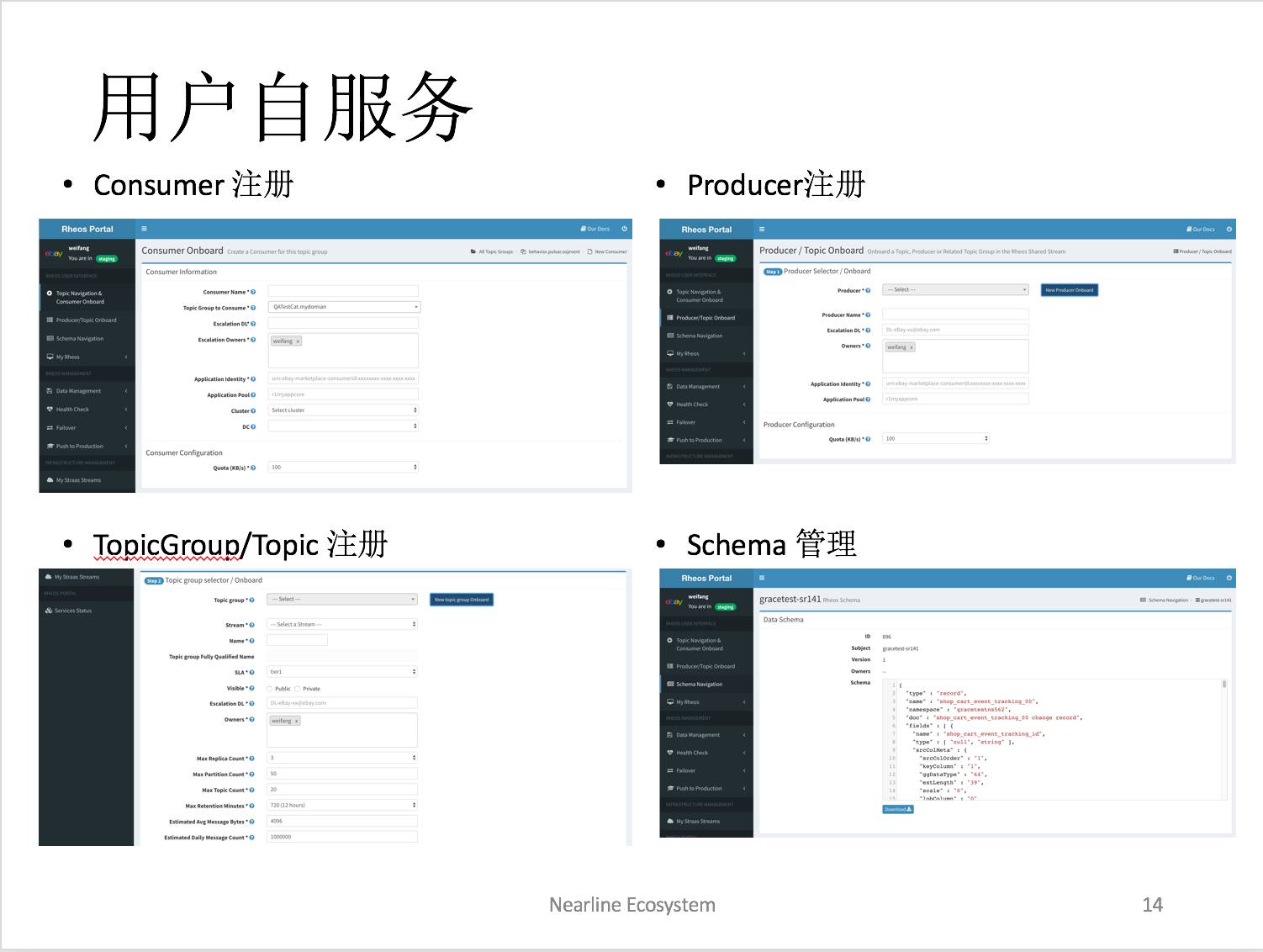
刚才所讲的服务,不管是对用户来讲,还是管理员来讲,我们都需要有一个界面操作它,因为不可能所有人都通过 SSH 去连服务器。
所以我们有一个用户自服务 portal,从 consumer 注册,producer 注册,topicgroup 注册,schema 的注册。
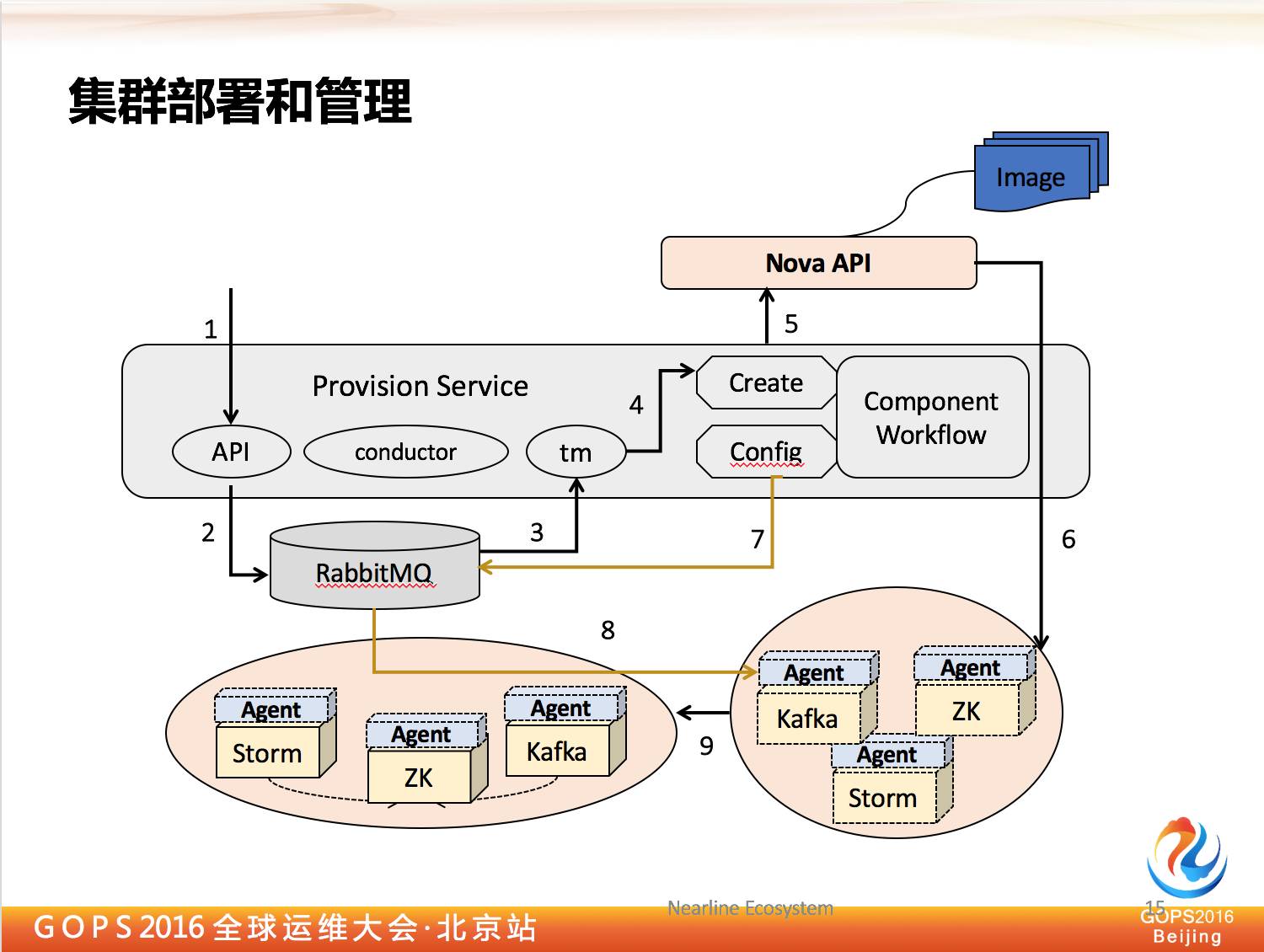
刚才说到了要创建一个集群,对集群地面的一些节点进行替换,我们要新增新的节点等等,我们都需要调 openstack 的功能,但是这个地方我们需要一个很迷你的 PaaS 完成这个系统。
我们其实是基于 openstack 搭建了一个小的迷你 PaaS,除了提供功能工作流之外,还提供的运行工作流管理的功能。
openstack 提供了一套接口做这种事情,但是接口后面必须要选择一个基于 ALQP 的协议,同样对于配置也是一样, Kafka 默认配置是什么样的,我们也有一些配置优化,改了一些配置让它对所有节点优化,怎么管理这些配置也是在 Prism 服务器里做的。
3、系统监控和自动化
那么说了这么多,平台最终上线的时候,我们要对它进行运维,运维里最重要的是我们要把系统监控好,并且当它出现问题的时候我们要及时修复它。对于这个系统监控是非常重要的课题。
3.1 集群节点监控
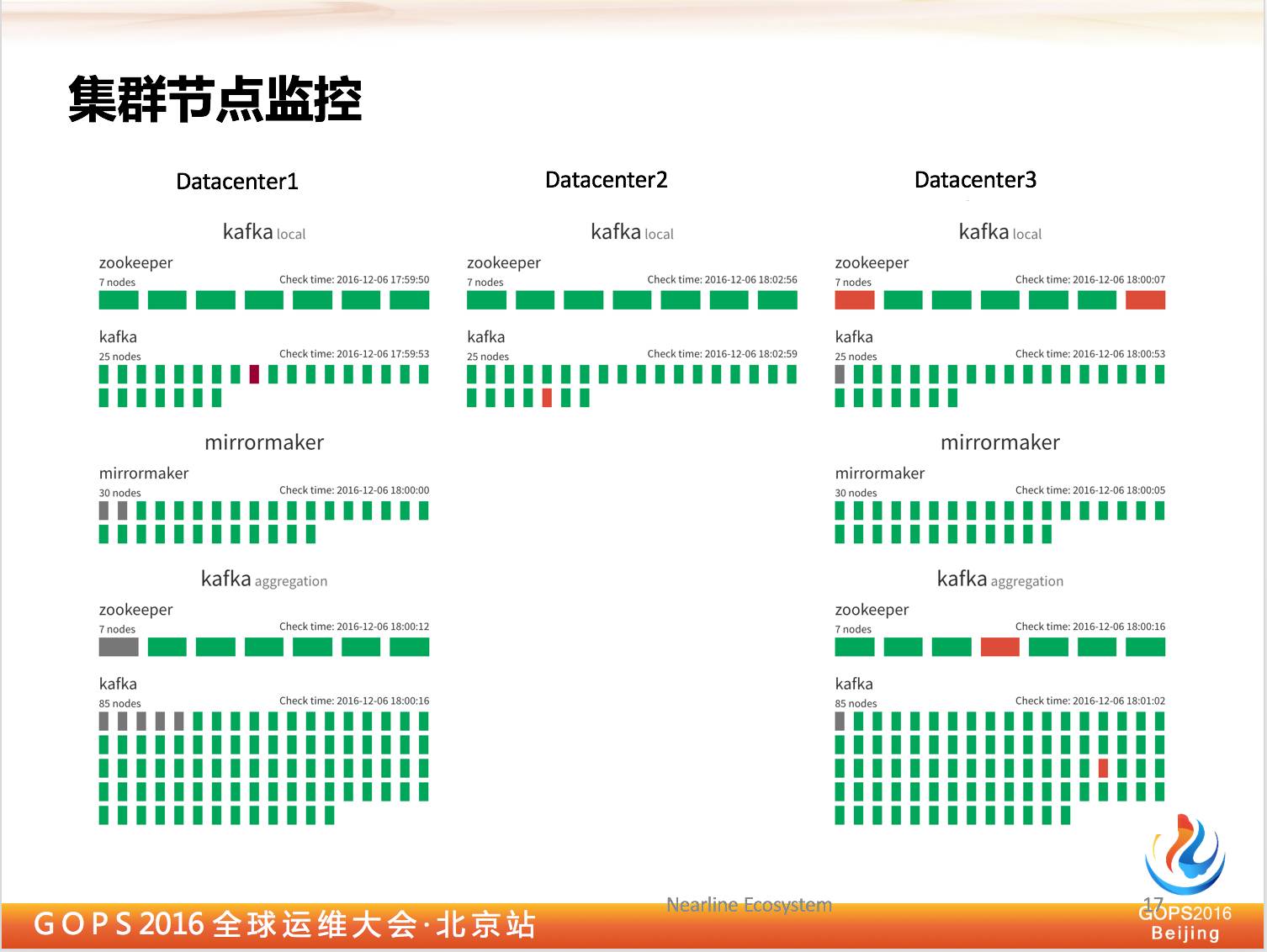
可以看出来,我们在这个系统中,其实是涉及到很多节点,对所有的我们打包起来,让它完成一个业务语义。
在监控方面我们肯定要有统一视角看到一系列集群运行状况,对于所有集群节点来说,并不是说宕一个节点就不行了,因为 Kafka 有数据冗余,宕一两个节点是没有问题的。
所以这里我就列出运营的节点是宕的,还是说健康的,我们运维人员对宕掉的节点进行修复。我们目前还是用人工的方式进行修复,因为我们需要分析这些也点宕掉的原因。
目前来讲,系统运行时间并没有超过一年,所以我们目前采用了人工的方式。以后我们会考虑当任何一个节点出现问题的时候,进行自动替换,自动替换的时候必然要引入一些规则,什么情况下可以自动停,什么情况下不能自动停。
4.2 Kafka状态监控
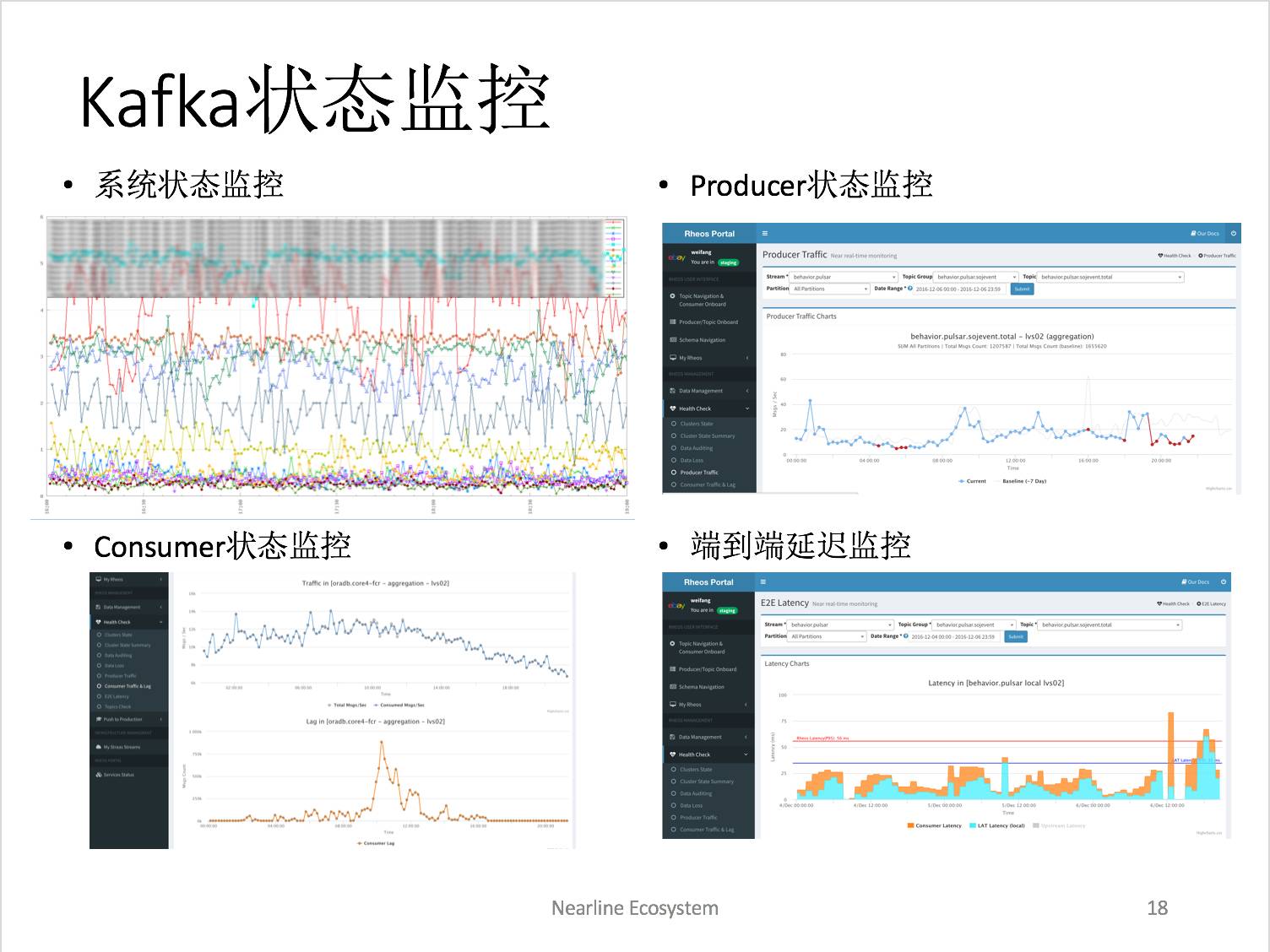
对于 Kafka 来讲,我们对每个节点,还有 Kafka 本身状态的监控。对于 Kafka 系统运维人员来说,这个节点的系统资源也是需要监控很重要的内容,对于管理员来讲系统状态是很重要的。
还有一种情况不仅对管理员重要,对用户也是很重要的,比如 Kafka 状态监控,对于用户来讲,比如我想知道我昨天进入 Kafka 集群有多少数据,所以这个方面的监控,除了给运维人员,也提供给系统的用户。
对于 consumer 也是一样,对于 Kafka 来讲很重要的监控是我要知道我的 consumer 到底有一个 leg。
如果这个 leg 一直增加的话,就说明 consumer 的应用肯定有问题的,我必须要对它进行一定处理,所以这个地方相当于我们帮助用户把这些问题严控起来。
发生问题的时候,不仅 consumer 管理员要知道,它的用户也要知道,所以报警系统也是通知到用户。另外我们有些应用是有端到端要求的,我们必须知道数据从应用发出来,到进到 Kafka ,到底有多长时间。
3.3 故障节点监测与处理

那么在 Kafka 里面,在运维过程我们发现有一个很重要的课题,对于慢节点怎么处理,什么叫慢节点?
其实 Kafka 能够很好的处理节点坏掉的情况,因为宕掉一两个节点对于它来说不要紧,它可以很快把坏的节点拿掉,它可以从别的节点上迅速选过来。
但是这种慢节点并没有死掉,只是比较慢的工作,比如正常情况下,它的吞吐率只有原来的1/10,那 Kafka 就不能把它拿掉,我们发现大部分系统都是存在这种问题。
为什么说一个节点出现性能问题,会影响整个 Kafka 集群呢?我们只有 Kafka 是做数据集群的。一旦这个节点性能出现问题,你到所有其他节点网络连接的数据都会有问题。
相当于它会拖累很多其他节点,出去 Kafka 集群在这个时候把这个节点干掉了,如果没有干掉,这个拖累会一直存在。
所以这就是我们为什么要在慢节点检测,慢节点比死掉的节点处理更麻烦,因为这种也点还在。比如我们可以看你的 CPU 在多长时间达到多少以上,我们要建立一些规则。
同时我们也要对磁盘进行监控,IO 的性能是不是出现了大的问题。同时要对系统日志异常进行分析,最后还有一个更为直接的方式,我们创建一些 footprint topic,我定期对 topic 进行测试,首先看看通不通,再看看速率有没有问题,这样我就可以知道节点有没有问题。
如果我检测出来慢节点之后怎么处理?
最简单的处理方式,就是把它停掉,其实把它停掉还是安全的,如果你觉得停掉对系统吞吐率造成影响的话,我们可以采取重启的方式,但是对于很多慢节点来说,你把它重启了它还是会慢。
如果一个节点,一个盘占用需非常高,这就说明资源分配很不均匀,这个我们引入 partition reassignrnert 来处理就不太好做,还是需要人工去处理。
3.4 Offset索引和自动背援
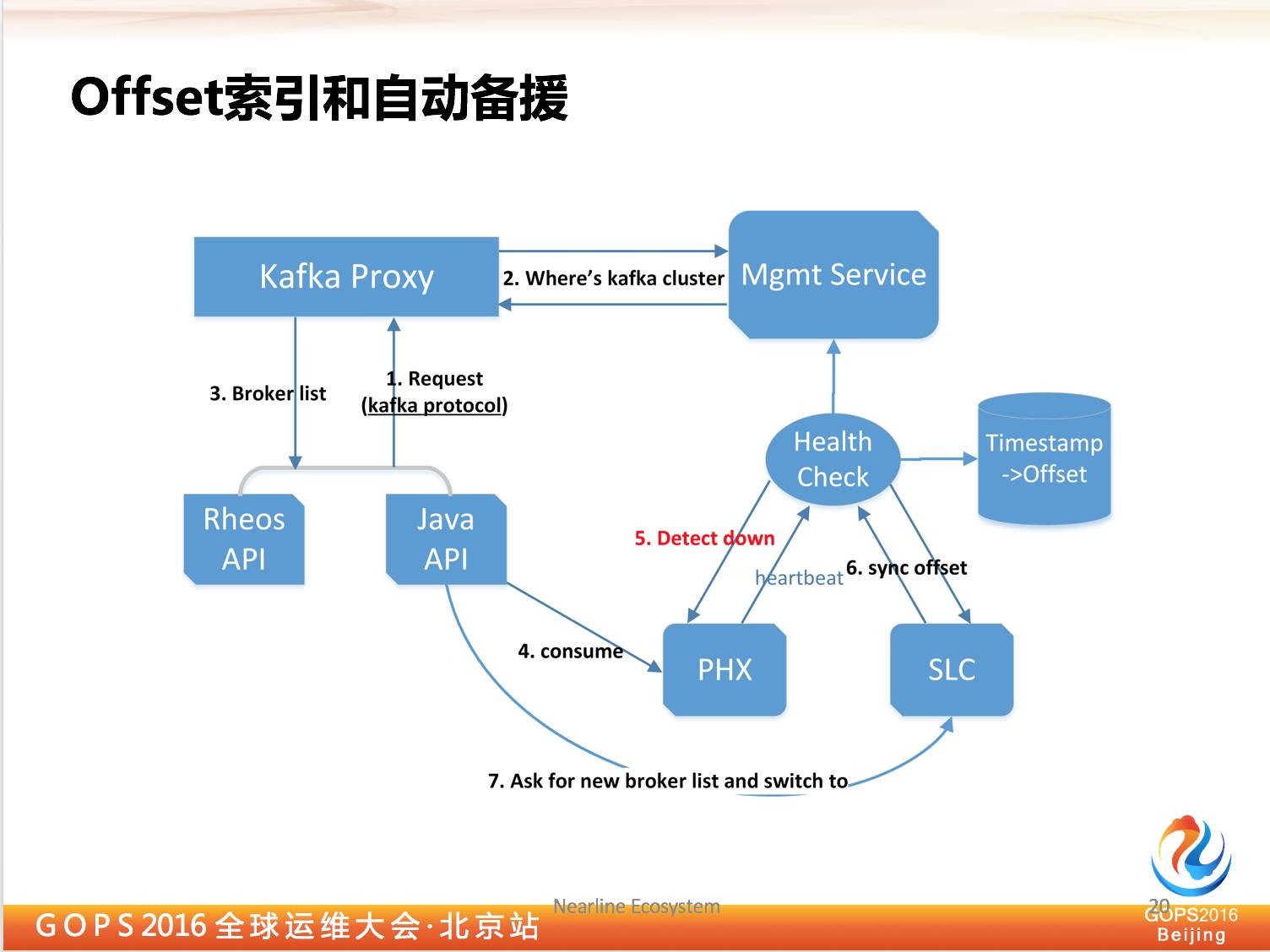
刚才我们说了我们的 Kafka 集群是在每个数据中心有独立拷贝的,比如北京数据中心整个 Kafka 宕掉了,那我能不能切到上海数据中心继续 consumer,那怎么做到这一点,不用人为干预情况下,会自动的切过去?
这就需要用到 Kafka 的代理,如果代理知道数据中心出问题了,把 Kafka 返回的信息发回到另一个数据中心,这时候就可以进行很好的处理。
对于 consumer 需要做另外一个事情,因为对于同一个信息在不同数据中心是不一样的。
比如上海数据中心比北京数据中心的 Kafka 早上一个月,那这个就肯定会有索引量偏移,所以我们就需要一个工具能够找到这个偏移量多大。好在后续版本 Kafka 就提升了一条索引机制在 Kafka 服务器里,但是我们在实现这个功能的时候,那个版本还没有出来。
4、Kafka性能优化
先说一下为什么 Kafka 有这么大的吞吐率和性能。
4.1 磁盘顺序读写

首先它是保证了磁盘顺序读写,因为我们知道磁盘顺序读写是很好的,只要你不引入文件读写。我们知道它这个特性之后,怎么样保证磁盘读写正常运行呢?我们不要让它的磁头经常跳,什么情况下磁头经常跳呢?
受到一个 Kafka 里节点太多了,不同文件切换的时候,就会引起顺序读写的方式。还有比如应用程序里,也会影响大数据读写的性能。如果要保证它是顺序读写的话,尽量避免刚才说的操作。
4.2 以Page Cache为中心的设计
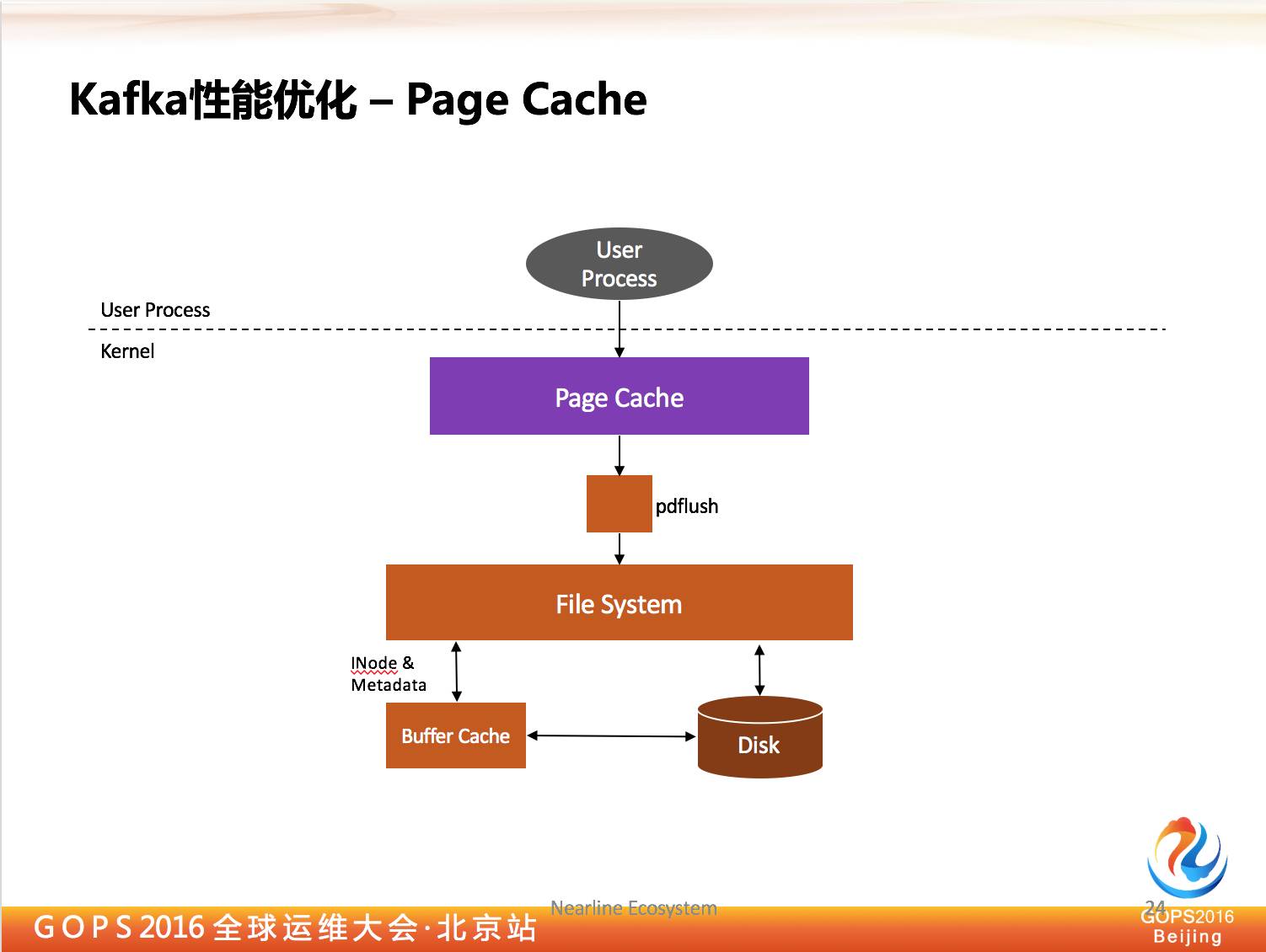
还有一个是 Kafka 通过 Page Cache 保持很高的性能,对于 Kafka 端,如果你跟上的话,它永远是从内部读数据,不是从磁盘读数据。
因为现在操作系统里我们会有 Page Cache 来监控数据处理,我们在运维当中,发现对于 Page Cache 来说,千万不能有 Swap,一旦发生 Swap,节点的性能马上会下降。

如果你是基于云的,特别是基于公有云的,这是很麻烦的事情,你需要在 Hypervisor 上进行设置。我们在使用当中也发现了 NUMA 不平衡的问题,这个会导致其他虚拟机所在的 CPU 内存没有很好的运营起来,它在后续版本的 OpenStack 里,会让你在分配 CPU 的时候,强行 PIN 的操作。







