厚缊 业余的R语言可视化重度患者个人博客:houyun.xyz邮箱:[email protected]
转载本文(包括长期转载账号)必须联系厚缊授权
相关系数矩阵可视化已经至少有两个版本的实现了,魏太云基于base绘图系统写了
corrplot
包,应该说是相关这个小领域中最精美的包了,使用简单,样式丰富,只能用惊艳来形容。
Kassambara的
ggcorrplot
基于
ggplot2
重写了
corrplot
,实现了
corrplot
中绝大多数的功能,但仅支持“
square”
和“
circle”
的绘图标记,样式有些单调,不过整个
ggcorrplot
包的代码大概300行,想学习用
ggplot2
来自定义绘图函数
,看这个包的源代码很不错。还有部分功能相似的
corrr
包(在写
ggcor
之前完全没有看过这个包,写完之后发现在相关系数矩阵变
data.frame方面
惊人的相似),这个包主要在数据相关系数提取、转换上做了很多的工作,在可视化上稍显不足。
ggcor
的核心是为相关性分析、数据提取、转换、可视化提供一整套解决方案,目前的功能大概完成了70%,后续会根据实际需要继续扩展。
这里要介绍的
ggcor
是
corrplot
的有一种实现,在吸收借鉴(或者说是全般)
corrplot
的基础上,略有提升,使用上会更灵活简单。这里不得不说下整个开发过程,一方面是为了感谢来自五湖四海的朋友提的许许多多的专业意见,另一方面是深感歉意,由于我考虑不周,
ggcor
(第一次上传github测试大约在十天前,名字还是
ggcorrr
)存在各种各样的小bug,也有很多限制,这次为了升级和简化,不仅名字变了,里面的函数也变得完全不一样,若你们以前写了
ggcorrr
的代码,现在基本不可以重用了。
尽管这一版本的更新我考虑了很多应用场景,综合了方方面面的意见,但是bug和限制还是在所难免,希望朋友们继续提意见,提需求。当然,这一次有两点是可以保证的:一是包名不会变了,再变都成精了;二是包内的主体函数和参数不会变了,而且即使要变,我也会考虑兼容性。
安装
if(!require(devtools))
install.packages("devtools")
if(!require(ggcor))
devtools::install_github("houyunhuang/ggcor")
数据预处理函数
ggplot2
要求的数据格式是
data.frame
,要把相关系数矩阵处理成理想的数据格式需要一系列的操作。
ggcor
提供了两个主要的函数,一个是
as_cor_tbl()
函数,另一个是
fortify_cor()
函数,两者结合应该能满足绝大多数的应用场景需求。
as_cor_tbl()
是更底层的函数,
fortify_cor()
本质上调用了
as_cor_tbl()
来得到最终的数据结果。这个函数适用于已经知道,或者需要用其它更特殊的函数(非
stats::cor()
)来处理得到系数的情况,常用的参数是前三个。
-
x
—— 相关系数矩阵(或者数据框),矩阵行名和列名是必要的,若没有或者缺失值会自动补全名字,行名以“Y”开头,附上递增的整数序列,列名以“X”开头,附上附上递增的整数序列。
-
type
—— 相关系数矩阵图样式,“upper”截断下三角,“lower”截断上三角。
-
show.diag
—— 相关系数矩阵图中是否包含对角线,仅对对称矩阵有效。
-
p
—— 相关系数检验p值矩阵(或者数据框),必须与
x
一一对应。
-
low
—— 相关系数置信区间下界矩阵(或者数据框),必须与
x
一一对应。
-
upp
—— 相关系数置信区间上界矩阵(或者数据框),必须与
x
一一对应。
-
cluster.type
—— 是否对相关系数矩阵进行重新排序,“none”表示不重排,“all”表示行列均重排,“row”表示对行重排,“col”则只对列重排。
-
...
—— 其它传递给
matrix_order()
函数的参数。
library(ggcor)
corr df df
## # A tibble: 121 x 3
## x y r
## *
## 1 1 11 1
## 2 1 10 -0.852
## 3 1 9 -0.848
## 4 1 8 -0.776
## 5 1 7 0.681
## # … with 116 more rows
## Extra attributes:
## xname: mpg cyl disp hp drat wt qsec vs am gear carb
## yname: carb gear am vs qsec wt drat hp disp cyl mpg
## show.diag: TRUE
fortify_cor()
主要适用于处理原始数据表,即调用
cor()
求相关系数,
cor
函数对数据按列进行两两相关性计算,默认使用
pearson
方法,当然理论解读中提前的
spearman
和
kendall
方法也都支持。
调用(若需要)
cor.test()
函数进行统计检验,并返回
ggcor
需要的数据类。
-
x
—— 原数据矩阵(或者数据框),列名是必要的,若没有或者缺失值会自动补全名字,列名以“X”开头,附上附上递增的整数序列。
-
y
—— 原数据矩阵(或者数据框),列名是必要的,若没有或者缺失值会自动补全名字,列名以“X”开头,附上附上递增的整数序列。当
y
不为空(NULL)时,相关系数是
x
中的每一列和
y
中的每一列的相关性。
-
type
—— 相关系数矩阵图样式,“upper”截断下三角,“lower”截断上三角。
-
show.diag
—— 相关系数矩阵图中是否包含对角线,仅对对称矩阵有效。
-
cor.test
—— 逻辑值,是否进行相关性检验。
-
cor.test.alt
—— 相关性检验备择假设,详细请查看
cor.test()
帮助。
-
cor.test.method
—— 相关性检验方法,详细请查看
cor.test()
帮助。
-
cluster.type
—— 是否对相关系数矩阵进行重新排序,“none”表示不重排,“all”表示行列均重排,“row”表示对行重排,“col”则只对列重排。
-
cluster.method
—— 当
cluster.order
为“HC”(默认)时算法,详细请查看
ggcor::matrix_order()
。
-
...
—— 其它传递给
cor()
函数的参数。
df01 TRUE, cluster.type = "all")
df01
## # A tibble: 121 x 6
## x y r p low upp
## *
## 1 1 11 1 7.44e-232 1.000 1.000
## 2 1 10 0.750 7.83e- 7 0.543 0.871
## 3 1 9 0.428 1.46e- 2 0.0927 0.676
## 4 1 8 0.527 1.94e- 3 0.218 0.740
## 5 1 7 0.395 2.53e- 2 0.0537 0.654
## # … with 116 more rows
## Extra attributes:
## xname: carb hp wt cyl disp drat am gear qsec mpg vs
## yname: vs mpg qsec gear am drat disp cyl wt hp carb
## show.diag: TRUE
as_cor_tbl()
和
fortify_cor()
返回值均是
cor_tbl
类的数据框(准确的说是
tibble
),并包含其它额外特殊属性,要充分利用
ggcor
包中一系列工具函数带来的便捷性,必须调用(手动比较麻烦)这两个函数预处理数据。
初始化绘图函数
ggcor
封装了一个基本的初始化函数
ggcor()
,用来处理数据、绘图类型、背景、坐标轴、颜色映射、图例等。看上去
ggcor()
函数非常复杂,但若仔细观察参数命名规则和分类,又是非常简单的。绘图区网格线参数名字均以
grid.*
开头;坐标轴相关参数均以
axis.*
开头;图例相关(主要是colourbar)的参数均以
legend.*
开头;还有
panel.backgroud
、
xlim
、
ylim
均是常见的参数,
panel.backgroud
参数用来设置绘图区背景颜色,
xlim
、
ylim
则是设置x/y轴的范围。把这几大块参数去掉后,剩下的参数只有6个了,瞬间清爽了不少。
要完全理解
ggcor()
的作用原理及相关参数的设置,需要先讲讲
ggcor()
内部构成
。
ggcor()
本质上是调用了
ggplot()
来初始化
,
然后根据相关系数图的样式添加了一些辅助的图层。
-
x
、
y
、
mapping
、
is.cor
、
show.diag
和
...
参数均和数据预处理和映射相关。
-
x
可以是
cor_tbl
、矩阵(数据框)。当为
cor_tbl
时直接作为
data
参数传递给
ggplot()
;为矩阵(数据框)时,若是(
is.cor = TRUE
)相关系数矩阵(数据框)时,调用
as_cor_tbl()
函数处理成
cor_tbl
,若不是(
is.cor = FALSE
)相关系数矩阵(数据框)时,调用
fortify_cor()
函数处理成
cor_tbl
,此时
x
、
y
、
show.diag
和
...
均传递给
as_cor_tbl()
或者
fortify_cor()
。
-
mapping
对应
ggplot()
中的
mapping
参数,当为空(默认)时,根据
cor_tbl
中的变量情况添加,基础形式是
aes(x = x, y = y, r = r, fill = r)
。若
cor_tbl
包含“p”(进行了相关系数显著性检验),则最基础形式基础上额外添加
p = p
,若检验方法(
cor.test.method = "pearson"
),再加上
low = low
和
upp = upp
。
-
fill.*
均是fill颜色映射函数相关的参数。
-
若
fill.scale.add
为
FALSE
不添加颜色映射函数。若为
TRUE
(默认),则会在初始化中自动添加颜色映射函数。
-
fill.colours
是颜色字符向量,用来控制填充色(fill)的颜色映射,若为空(默认),使用
corrplot
默认配色,可以通过
ggcor:::.defualt.colors
查看具体颜色。
-
fill.bin
是否对连续性颜色进行分组(默认
FALSE
)。当
fill.scale.add = TRUE
时,若
fill.bin = TRUE
,
ggcor()
的颜色映射函数是使用
scale_fill_steps2n()
,若
fill.bin = FALSE
,
ggcor()
的颜色映射函数是使用
scale_fill_gradient2n()
。
-
背景网格线是通过
geom_tile()
(目前来看,
geom_tile()
会存在一些难以处理的缺点,以后可能会添加专用的网格线图层函数),
panel.backgroud
(fill)、
grid.*
系列参数传递给
geom_tile()
。
-
legend.position
传递给
theme()
中对应的参数,用来控制图例位置,其它
legend.*
开头参数传递给
guide_colourbar()
或者
guide_colorsteps()
。
legend.breaks
用来控制图例颜色棒标签显示位置,
legend.labels
是对应的标签。若
fill.bin = TRUE
,
legend.breaks
也是图例颜色棒切割分组的位置。
-
coord.fixed
逻辑值,为真
xlim
、
ylim
传递给
coord.fixed()
函数,为假传递给
coord_cartesian()
函数。在
ggcor
包中,相关系数矩阵若是n * m的矩阵,那么第i行对应的坐标点(即
as_cor_tbl()
返回结果中的y)为n-i(为了和表格呈现样式一致,行方向翻转了),第j列对应的坐标点(即
as_cor_tbl()
返回结果中的x)为j,得到第(i, j)个数据点所在的方格坐标为(xmin = j-0.5, xmax = j+0.5, ymin = n-i-0.5, ymax = n-i+0.5)。从这个规律我们不难算出默认的
xlim
、
ylim
取值范围。
注意,对
cor_tbl
数据框,或者说是
ggcor
包中函数操作数据,均不会改变每个数据单元格在图中的坐标位置。
ggcor()
初始化之后,本质上返回的是
ggplot
对象,若是想改变默认设置,可以按照
ggplot2
的相应的函数和设置方法去调整。
我写
ggcor()
函数花的时间最长,耗费的精力最多,但到现在仍然是半成品的感觉,有些问题直到现在我也没找到相对完美的解决方案。尽管如此,对于新手,我还是建议调用
ggcor()
来进行初始化,若自己去研究各种图层函数,折腾很多细节,一天也难得出一幅图,对于心里的打击比较大。看几个初始化之后的效果。
ggcor(mtcars)
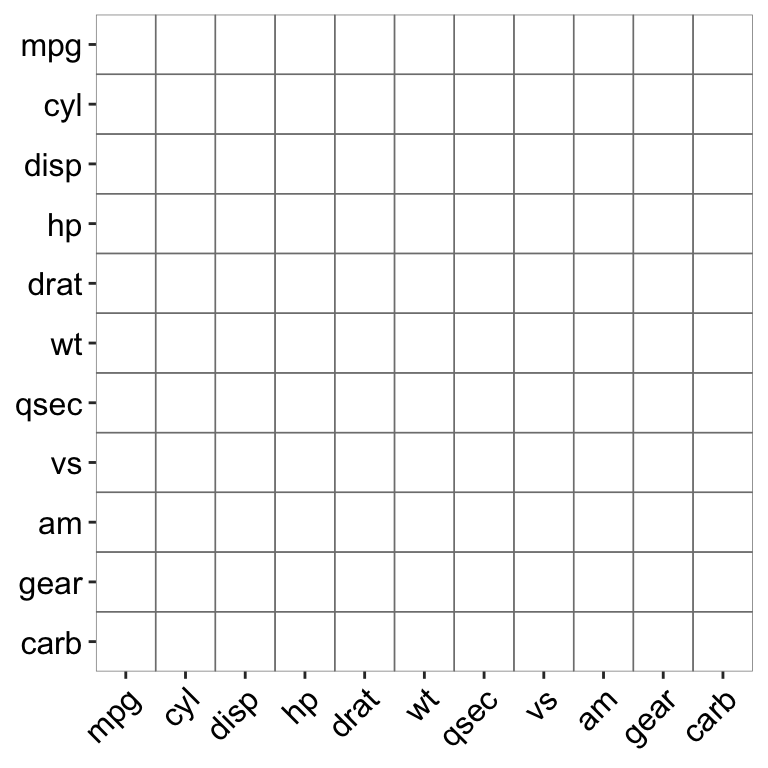
ggcor(mtcars, type = "lower")
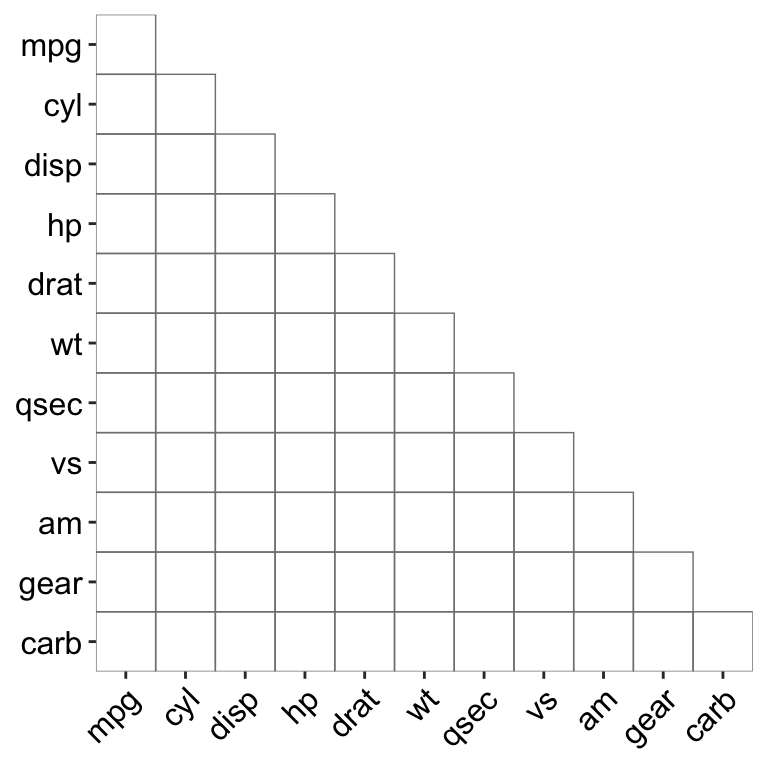
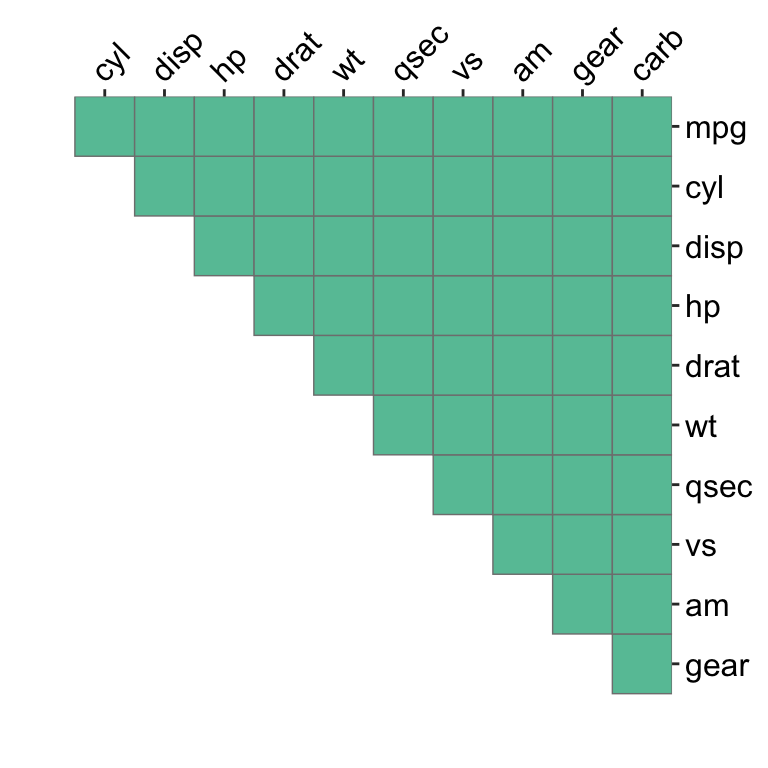
df02 "upper")
ggcor(df02, panel.backgroud = "#66C2A5")
图层函数
ggcor
提供了定制的
geom_square()
、
geom_circle2()
、
geom_ellipse2()
、
geom_pie2()
、
geom_colour()
、
geom_confbox()
、
geom_num()
、
geom_mark()
、
geom_cross()
9个
ggplot2
图层函数,可以根据需要进行叠加。除了
ggplot2
中一般化的参数(
x
、
y
、
fill
、
colour
、
size
等)最常用参数
r
、
p
、
low
、
upp
、
num
、
r0
、
sig.thres
、
sig.level
、
mark
等。
-
-
r
—— 相关系数,适用于
geom_square()
、
geom_circle2()
、
geom_ellipse2()
、
geom_pie2()
、
geom_confbox()
、
geom_mark()
(统计显著性标记的系数,与
1.234
∗∗
1.234
∗
∗
类似)。这些参数之所以都设置为“r”,主要是因为在相关系数可视化中基本都映射为相关系数,统一命名可以减少一些参数记忆,方便使用。
-
p
—— 相关系数检验P值,适用于
geom_mark()
、
geom_cross()
,结合
sig.thres
等参数来根据显著性水平做一些辅助标记。
-
r
、
low
、
upp
—— 适用于
geom_confbox()
,三个参数均是必须的,
low
、
r
、
upp
分别确定置信区间盒子的下端、中间和上端线条位置。
-
num
—— 适用于
geom_num()
,数值变量。这个函数封装于
geom_text()
,做了一点点优化,以后可能会删除。
-
-
r0
,外接圆半径缩放系数,适用于
geom_square()
、
geom_circle2()
、
geom_ellipse2()
、
geom_pie2()
函数。该参数的主要意义是处理图形覆盖问题,当在每个单元格画半径为0.5的方块、圆等图标时,会相互覆盖掉背景网格线,影响视觉效果。该参数默认值是0.48。
-
sig.thres
统计显著性临界值,用来过滤非显著的数据行。适用于
geom_mark()
、
geom_cross()
。
-
sig.level
、
mark
适用于
geom_mark()
,前者为统计显著性水平向量(如
c(0.001, 0.01, 0.05)
),后者为对应的标记符号(
c("***", "**", "*")
)。统计显著性水平向量不要求一定要按顺序排列,只要求和标记符号一一对应就行。
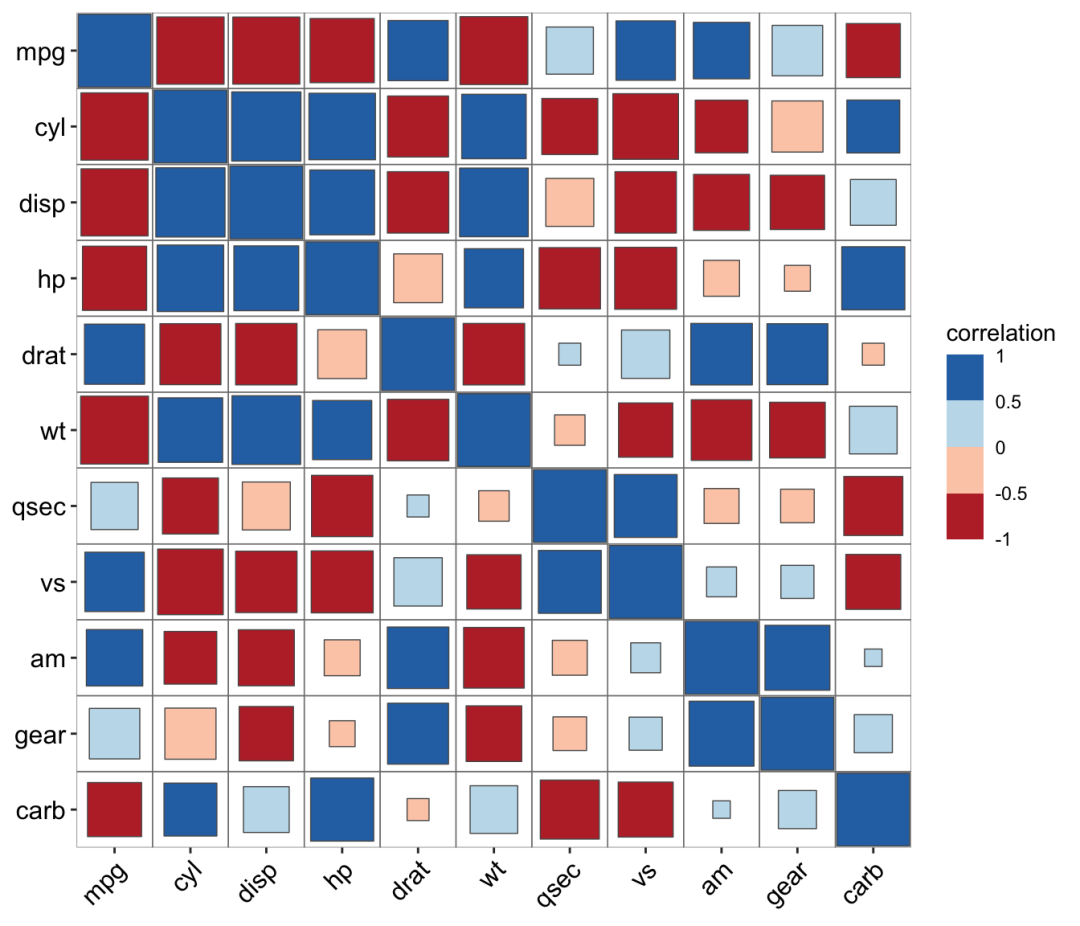
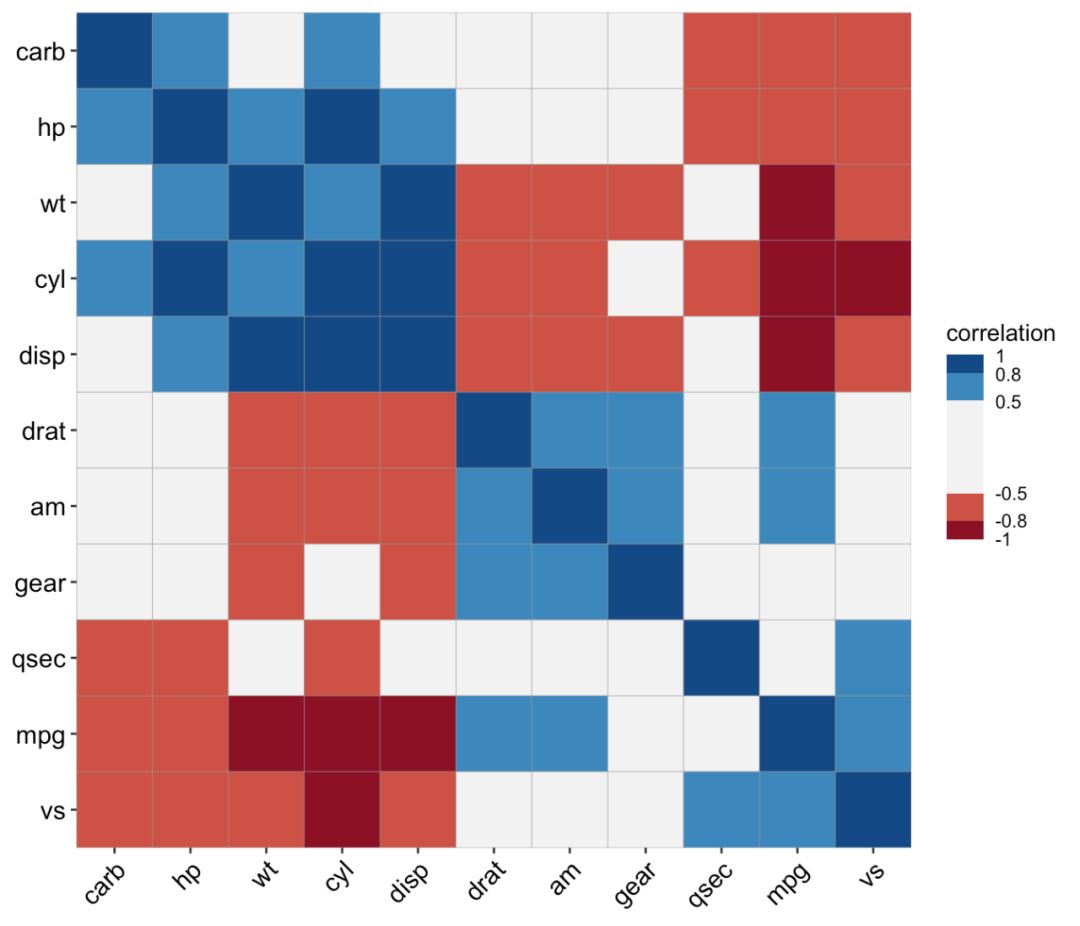
ggcor(mtcars) + geom_square()
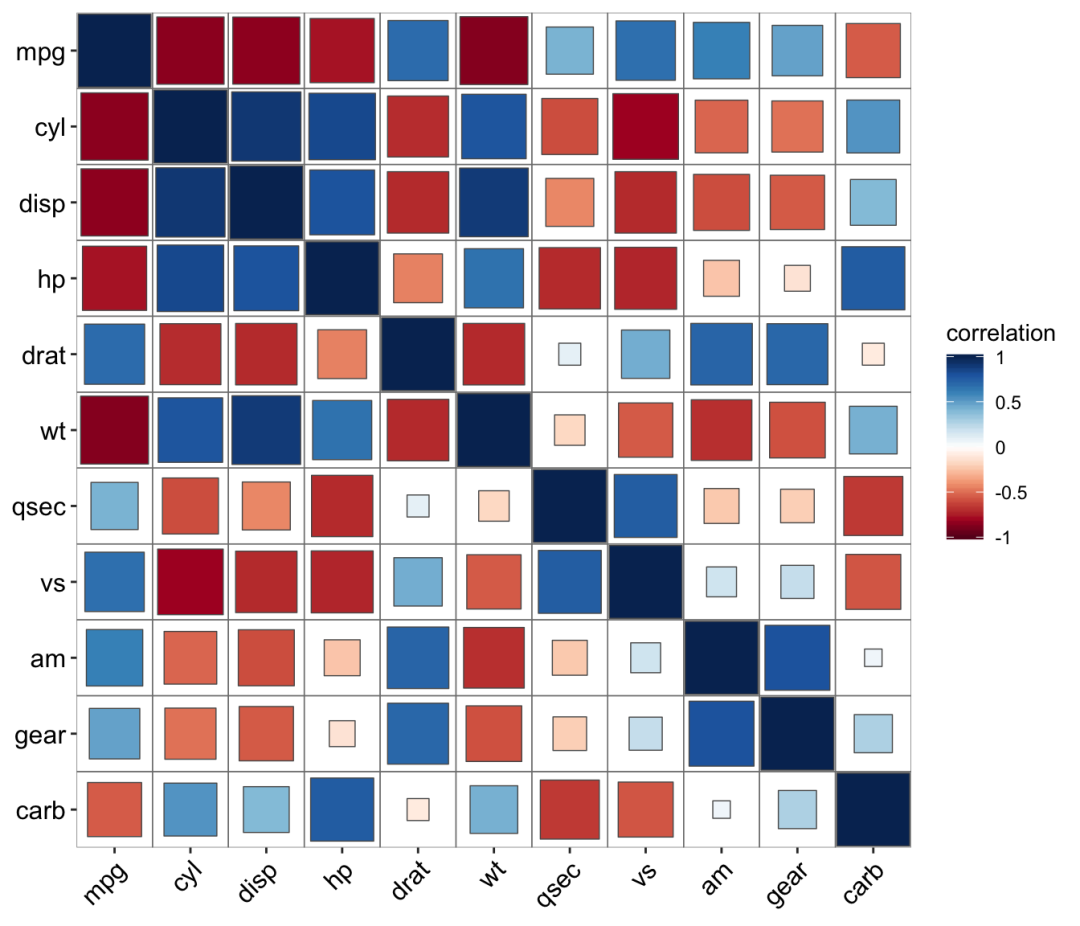
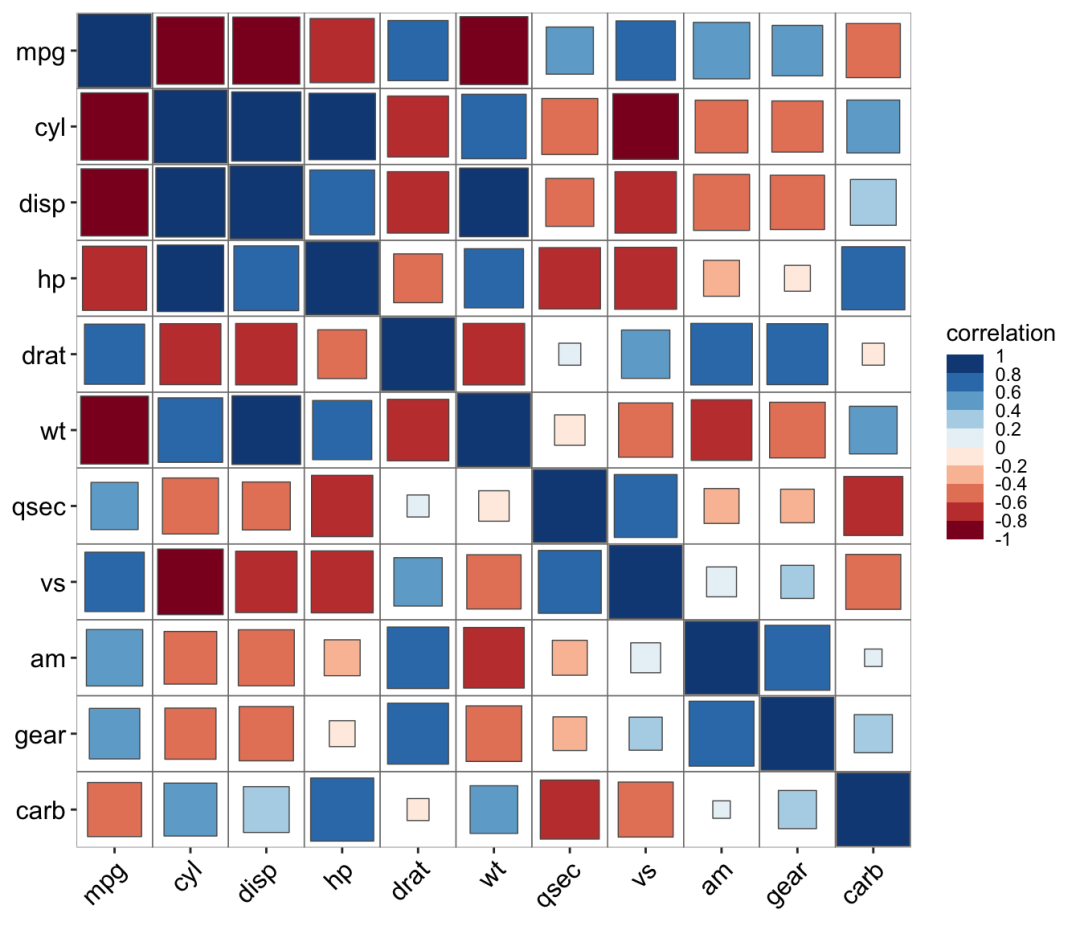
ggcor(mtcars, type = "upper") + geom_circle2()
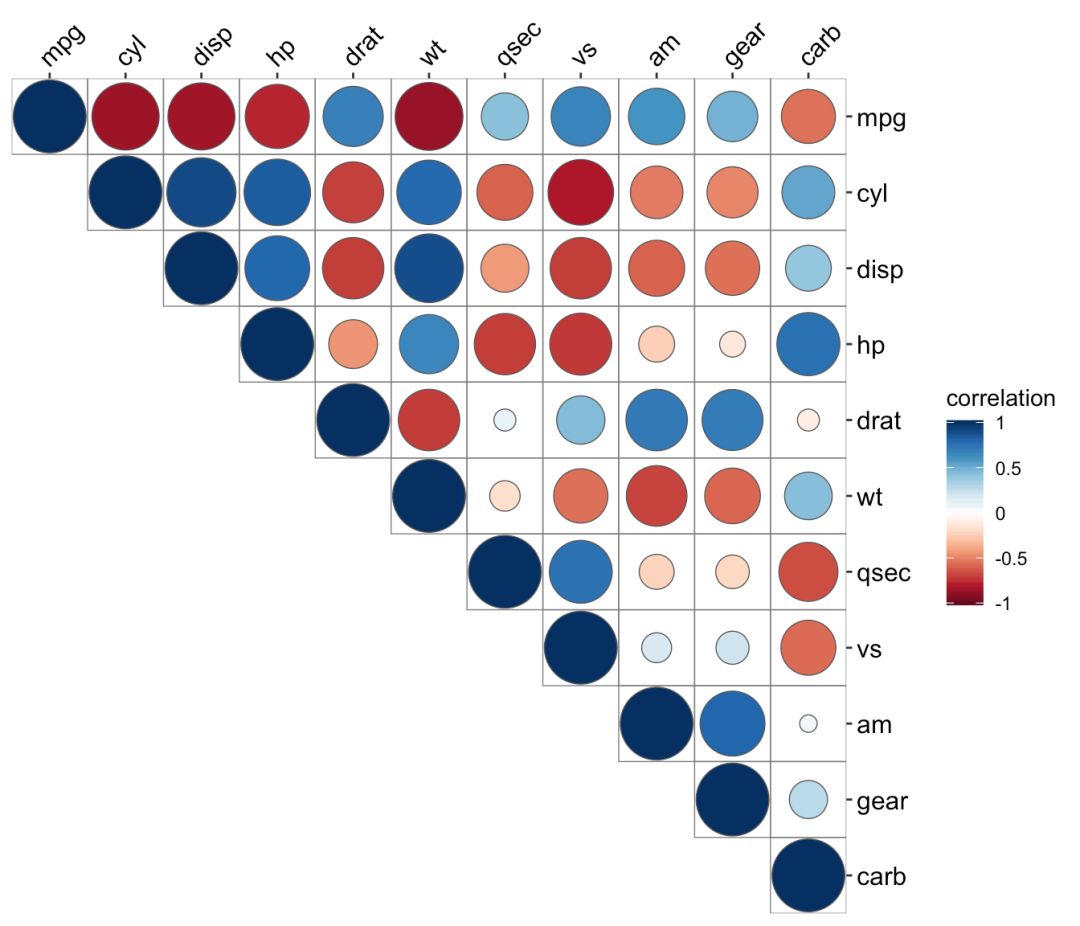
ggcor(mtcars, type = "lower", show.diag = TRUE) + geom_ellipse2()
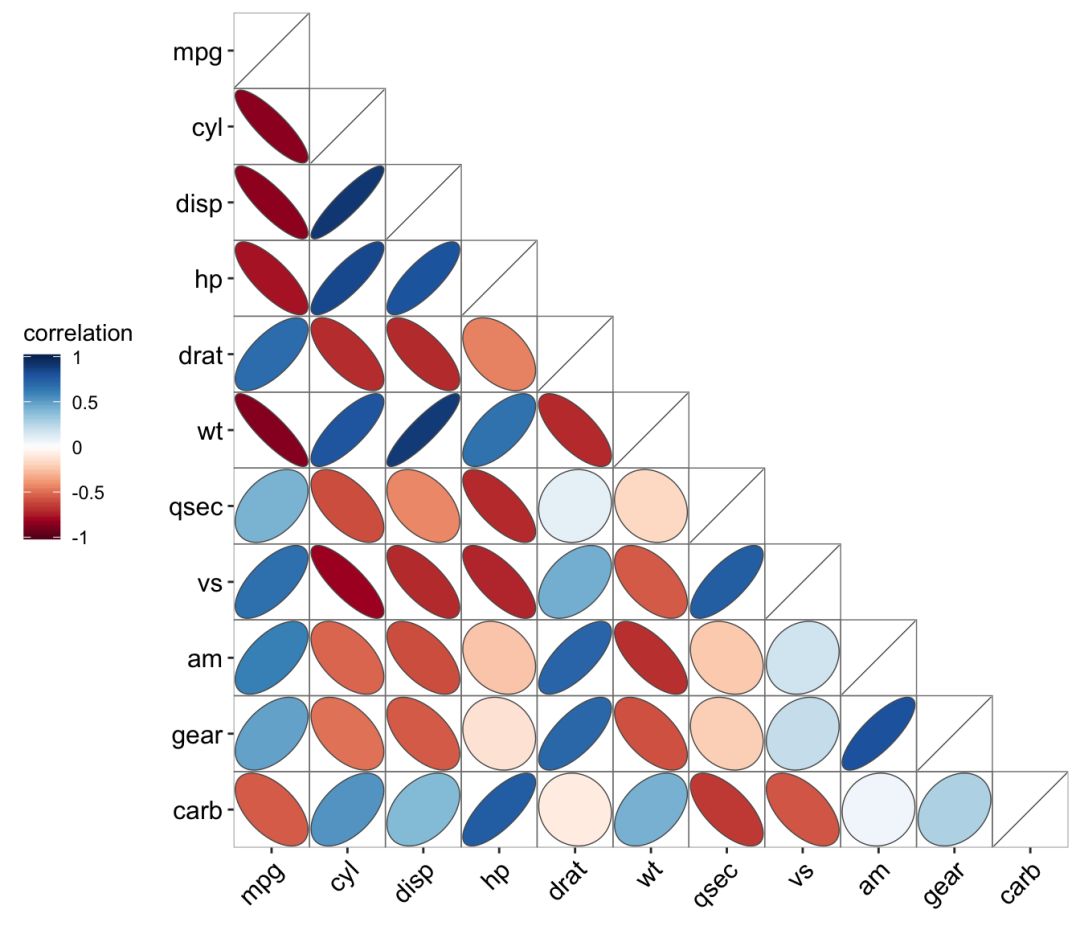
ggcor(mtcars, type = "full", cluster.type = "all") + geom_pie2()
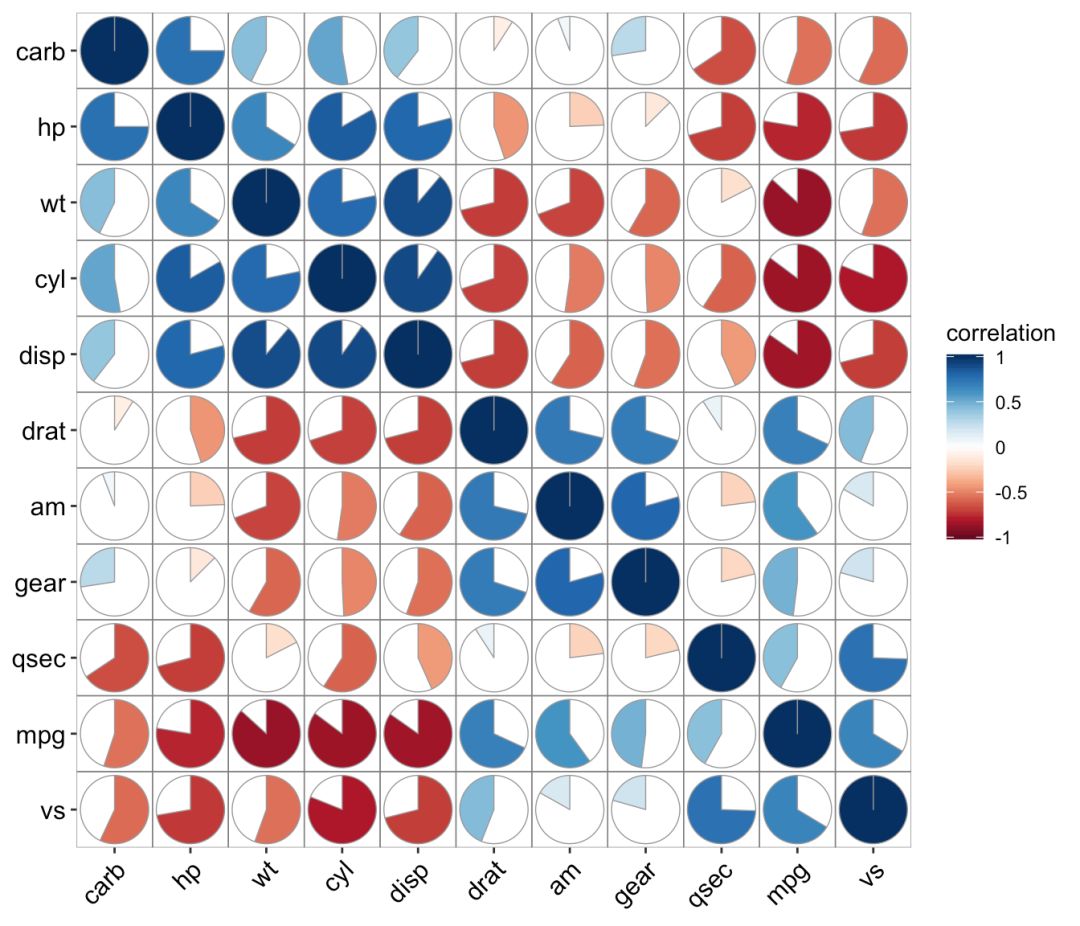
ggcor(mtcars, cluster.type = "all") +
geom_colour() +
geom_num(aes(num = r), colour = "grey90", size = 3.5)
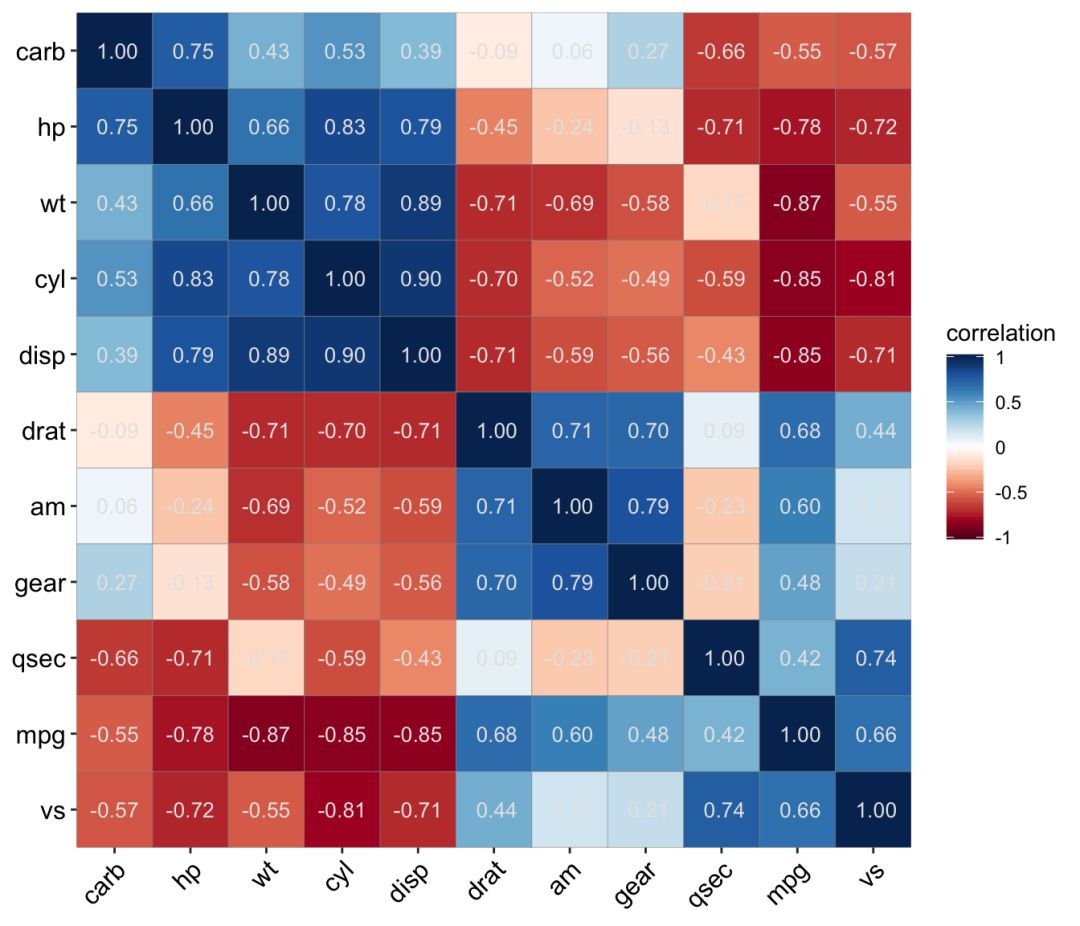
ggcor(mtcars, type = "full", cor.test = TRUE) + geom_confbox()
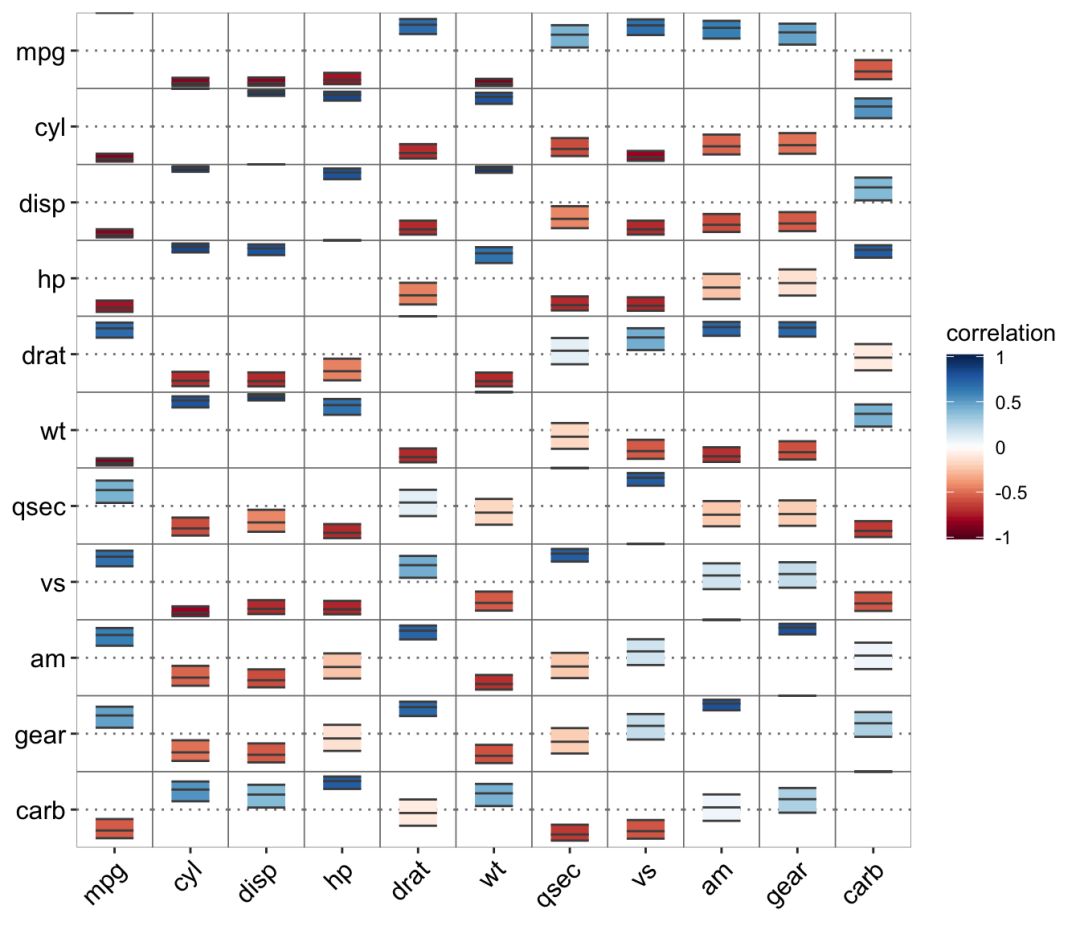
ggcor(mtcars, type = "full", cor.test = TRUE, cluster.type = "all") +
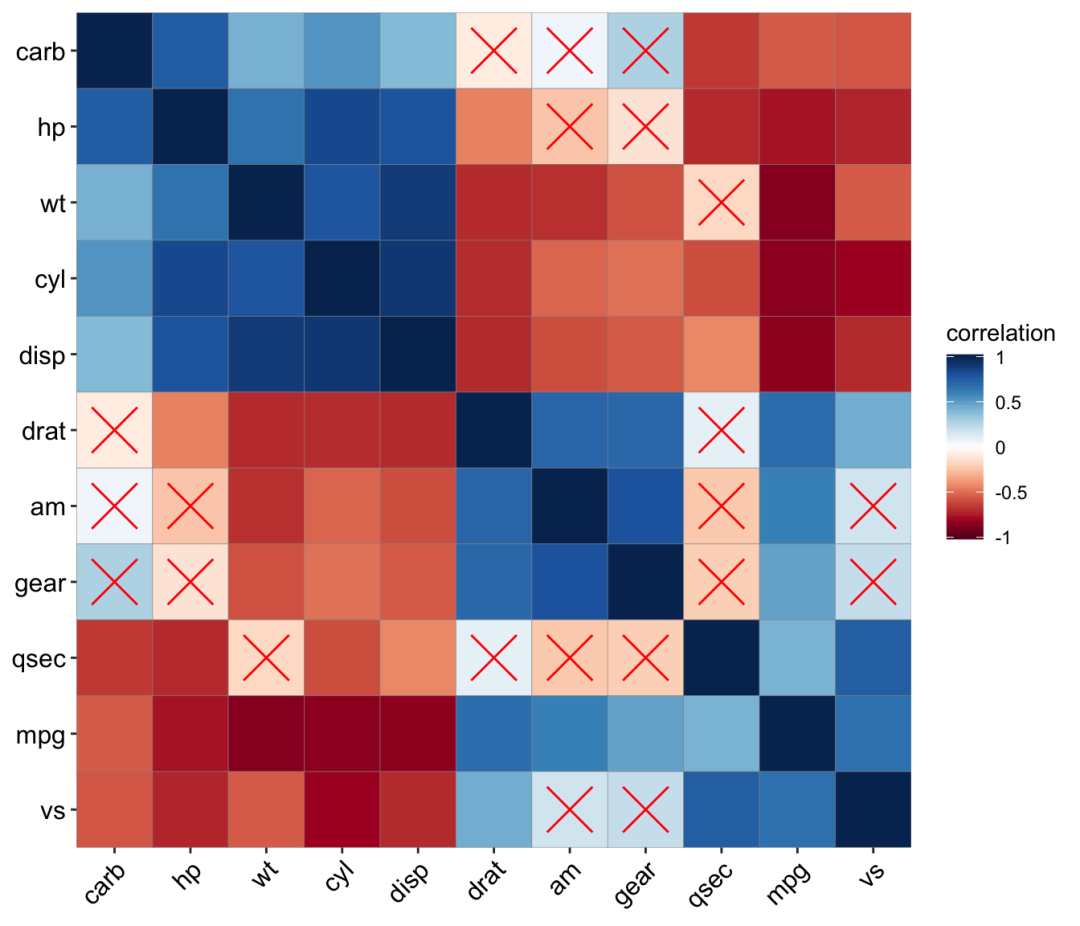
geom_colour() + geom_cross()
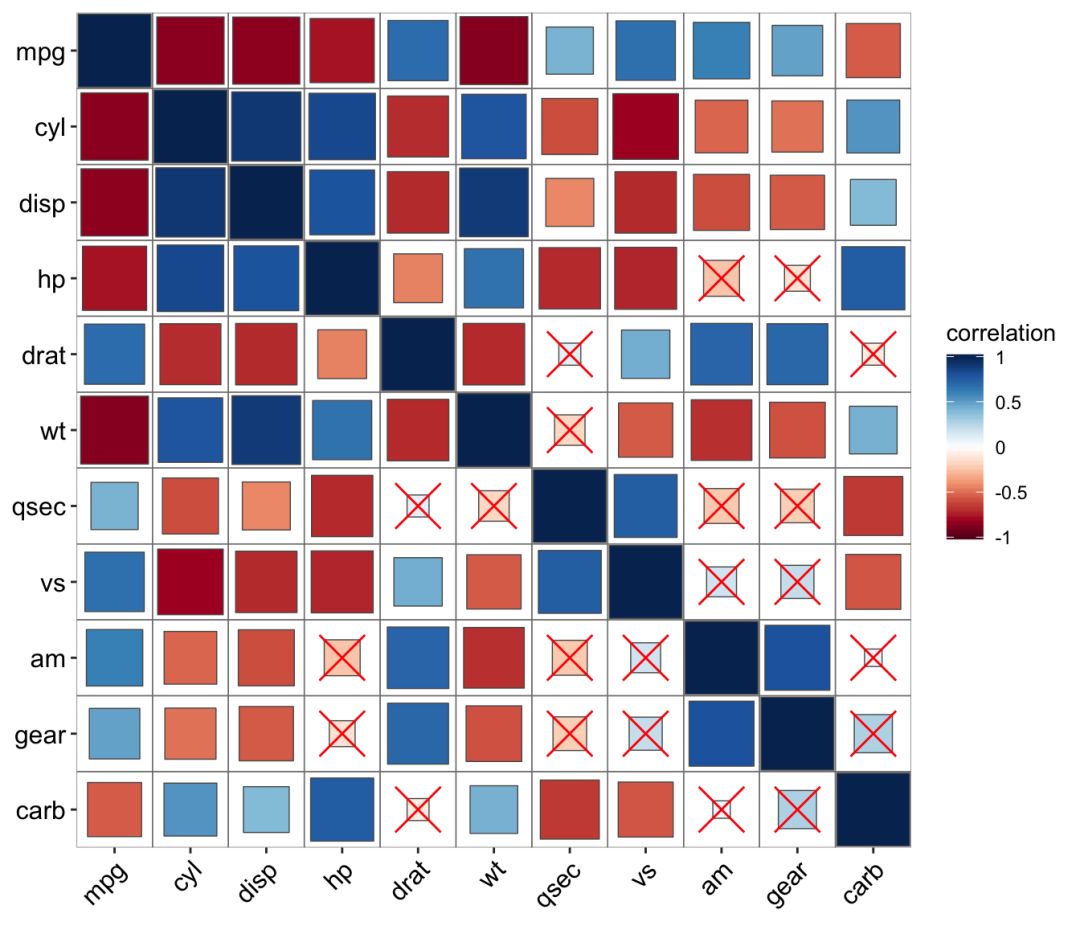
ggcor(mtcars, type = "full", cor.test = TRUE) +
geom_square() + geom_cross()
其它图层函数的使用都比较符合直觉,需要设置的地方也很少,而
geom_mark()
会涉及一些其它问题,这里拉出来说说。
很多时候,我们并不关心不具备统计显著性的相关系数,也不需要在图中显示,这时需要设置
sig.thres
,即要过滤的显著性临界值。
ggcor(mtcars, type = "full", cor.test = TRUE, cluster.type = "all") +
geom_raster() +
geom_mark(sig.thres = 0.05, size = 3, colour = "grey90")
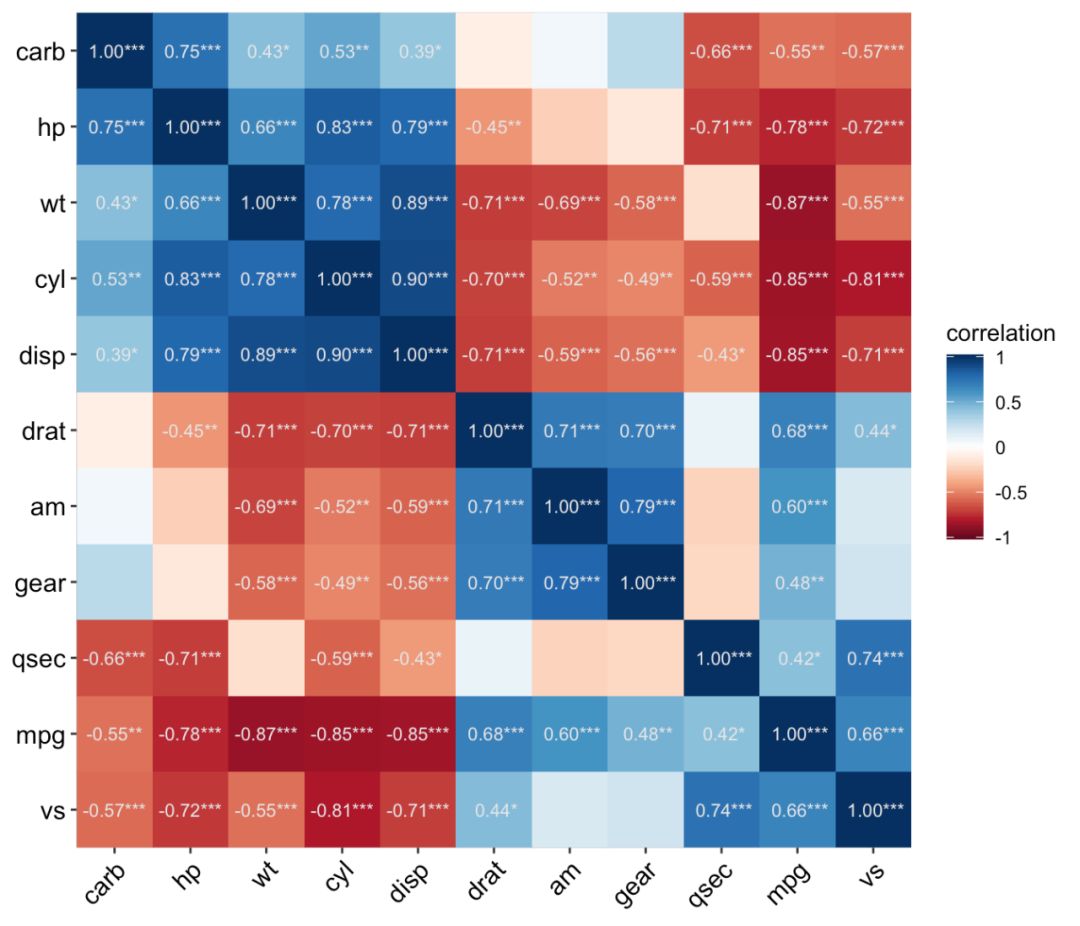
若是只要统计显著性标记的"*"号,不要系数怎么整?在
geom_mark()
中也很简单,直接设置
r
就好。
ggcor(mtcars, type = "full", cor.test = TRUE, cluster.type = "all") +
geom_raster() +
geom_mark(r = NA, sig.thres = 0.05, size = 5, colour = "grey90")
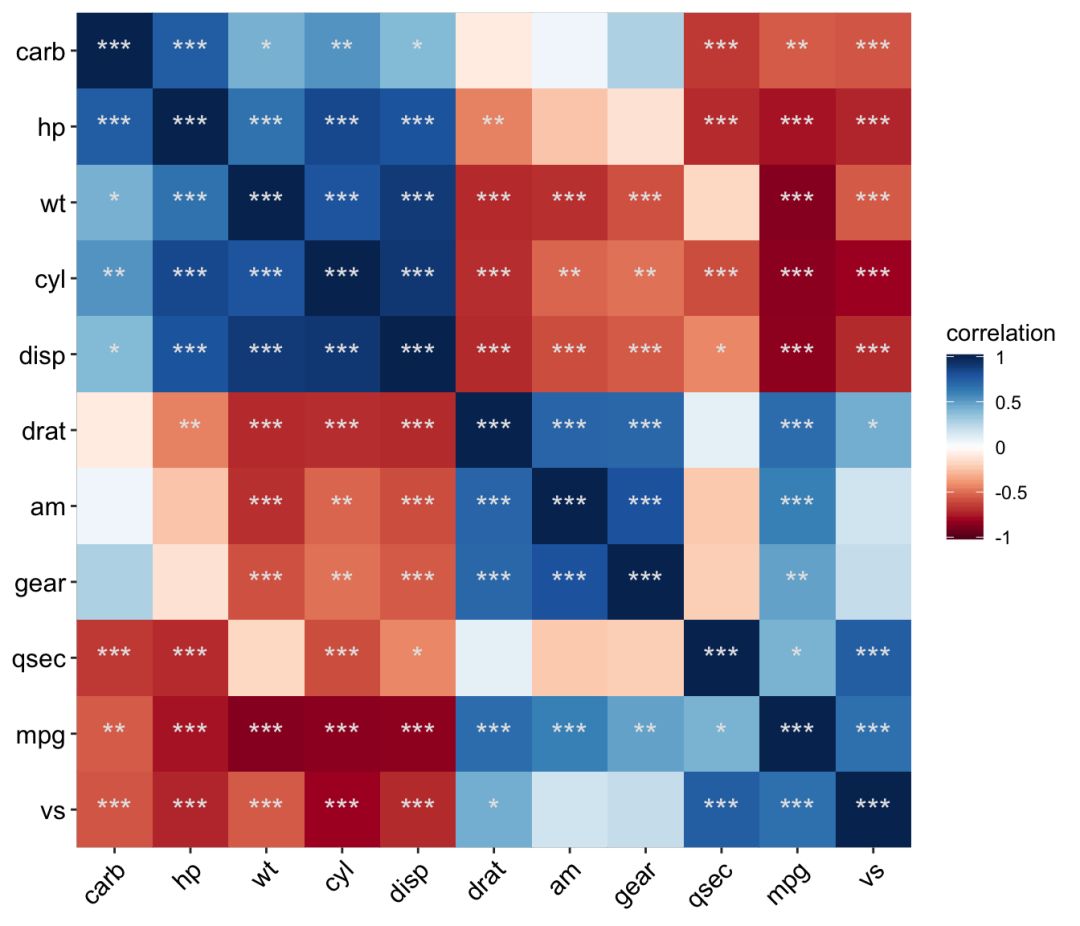
那要改变星号标记规则,只要小于0.05的标记一颗星,其它什么都不标记呢?
注意:因为星号在文本中显示在偏上的位置,若不设置
vjust
参数,看上去纵向会不居中。
ggcor(mtcars, type = "full", cor.test = TRUE, cluster.type = "all") +
geom_raster() +
geom_mark(r = NA, sig.level = 0.05, mark = "*", vjust = 0.65, size = 6, colour = "grey90")
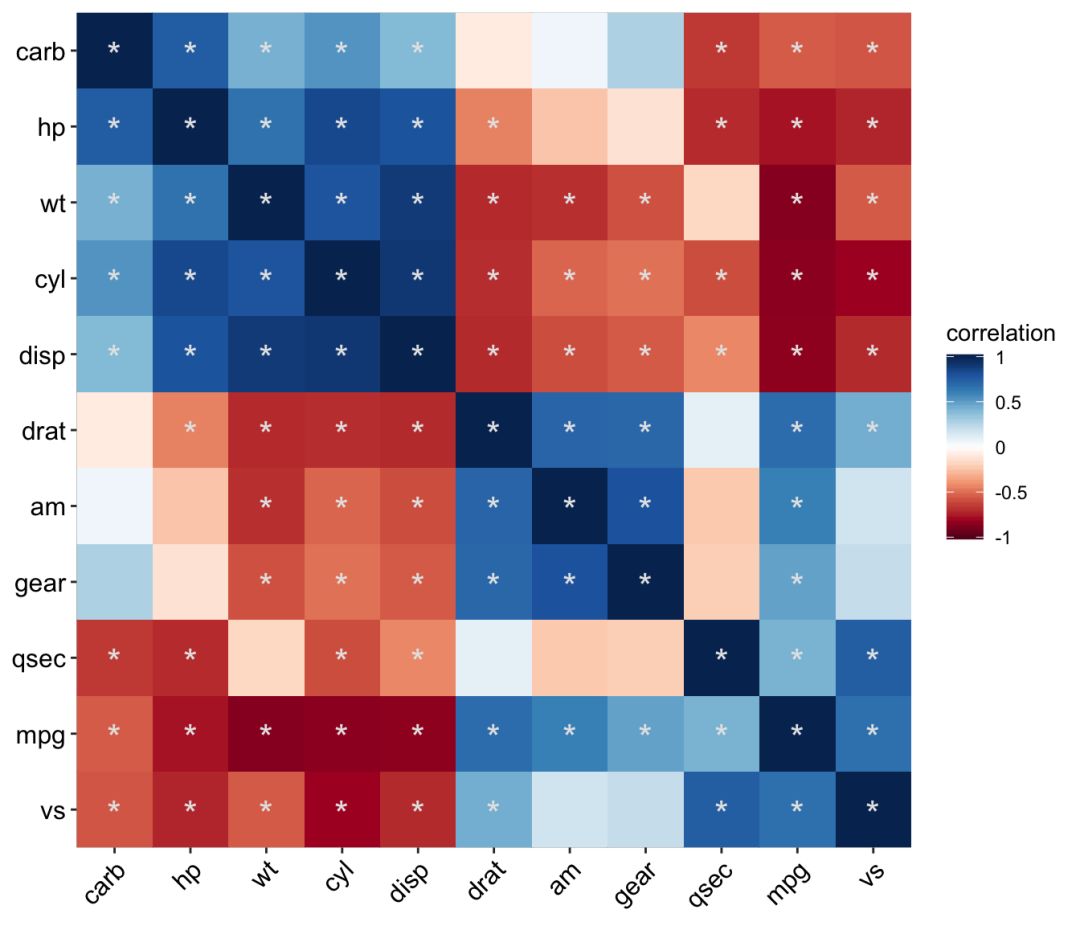
非对称相关系数矩阵
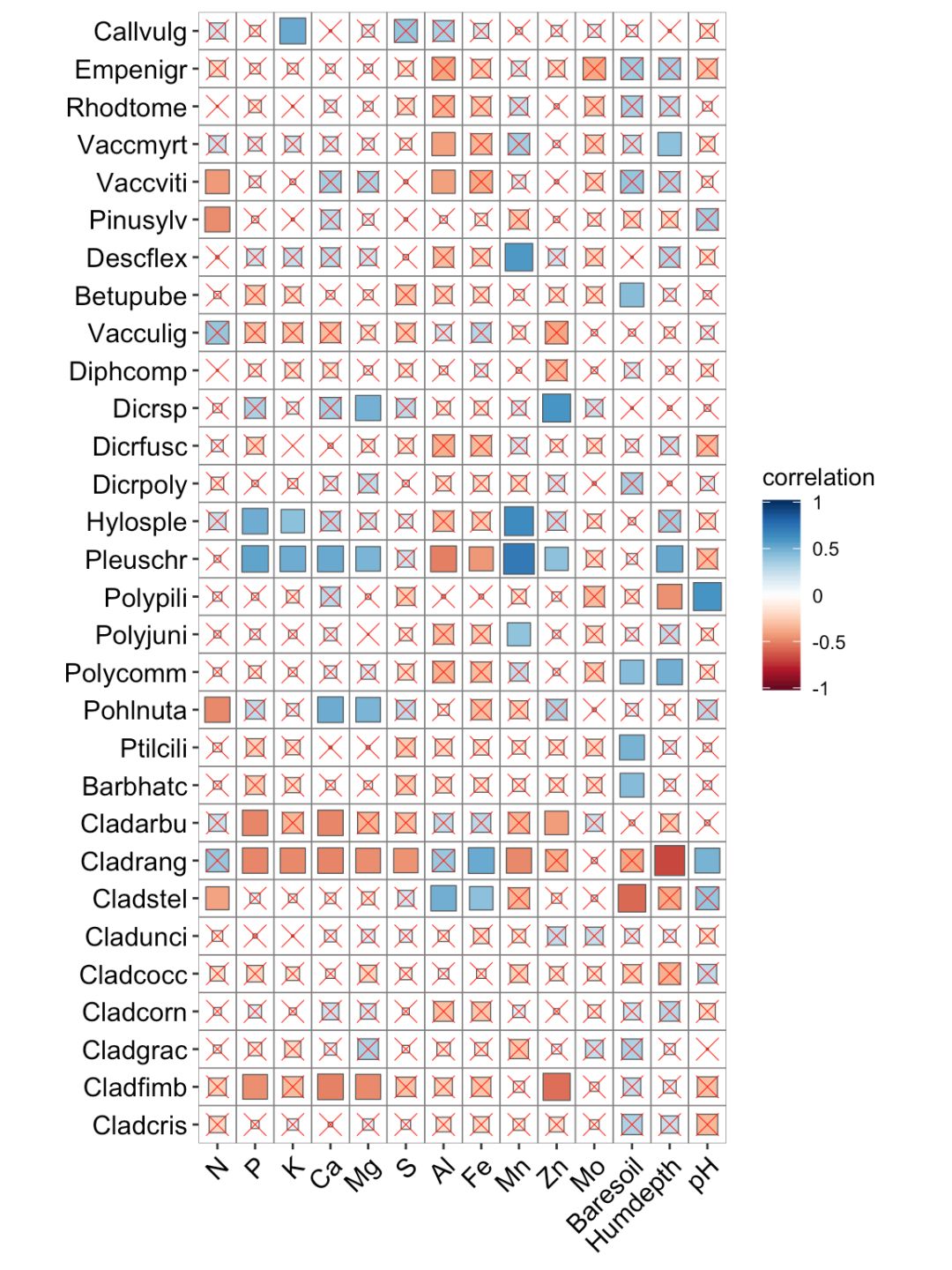
非对称相关系数矩阵和非对称矩阵是有细微的区别的,前者表示行列代表不同的变量集合,相互之间的顺序可以打乱。所以,有时候要分析两个表中每个变量之间的相关性,此时得到的结果就是非对称的相关系数矩阵。
library(vegan)
data(varechem)
data(varespec)
df03 1:30], cluster.type = "col")
ggcor(df03) + geom_colour()
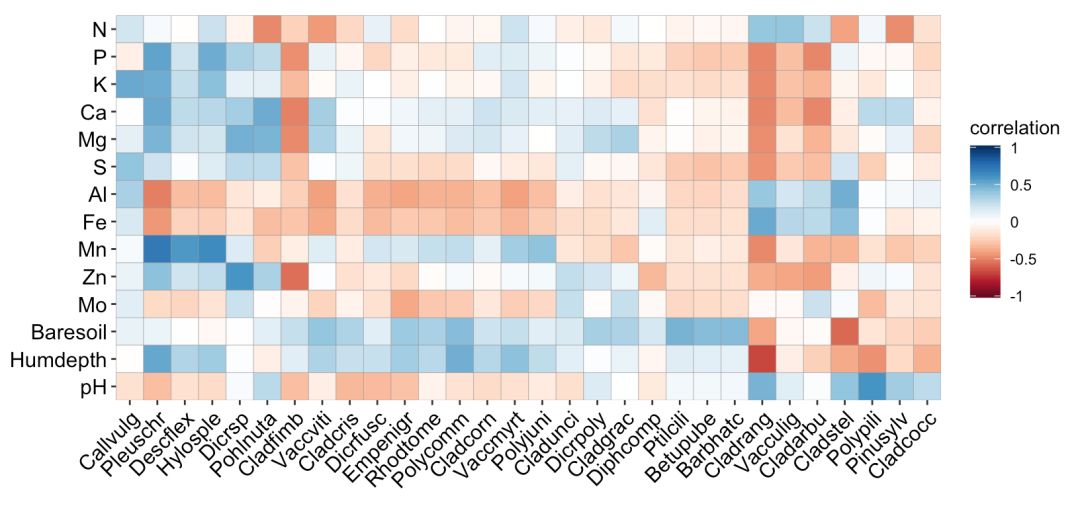
df04 1:30], y = varechem, cor.test = TRUE)
ggcor(df04) + geom_square() + geom_cross(size = 0.2)
上下三角不一样怎么画?
ggcor
提供了很多辅助函数来对
cor_tbl
数据进行过滤,函数命名规则上都以
get_*
开头。
-
get_lower_data()
—— 获取相关系数矩阵下三角所在行,仅支持对称的相关系数矩阵。
-
get_upper_data()
—— 获取相关系数矩阵上三角所在行,仅支持对称的相关系数矩阵。
-
get_diag_data()
—— 获取相关系数矩阵对角线所在行,仅支持对称的相关系数矩阵。
-
get_diag_tri()
—— 删除相关系数矩阵对角线所在行,仅支持对称的相关系数矩阵。
-
get_data()
—— 是以上四个函数的重新包装,主要在画图时使用,稍后通过例子详细说明。
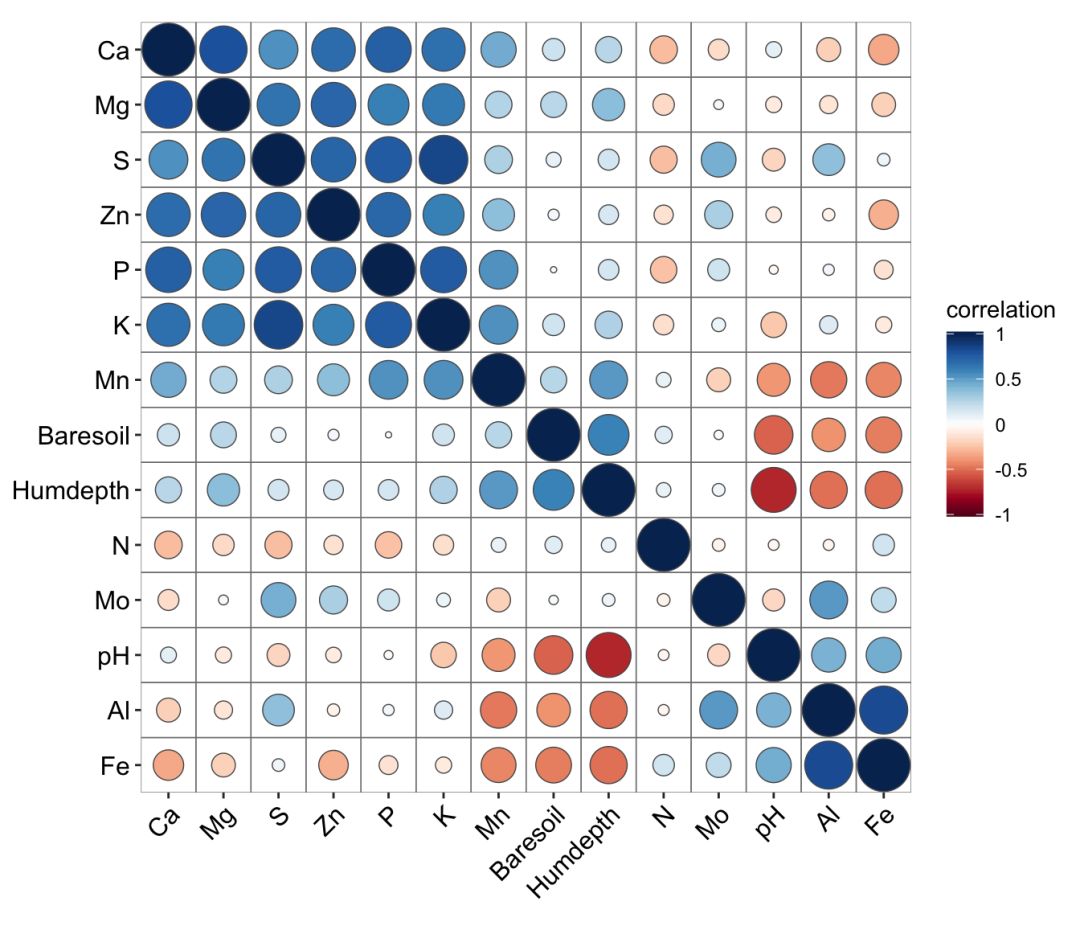
df05 TRUE, cluster.type = "all")
ggcor(df05) + geom_circle2()
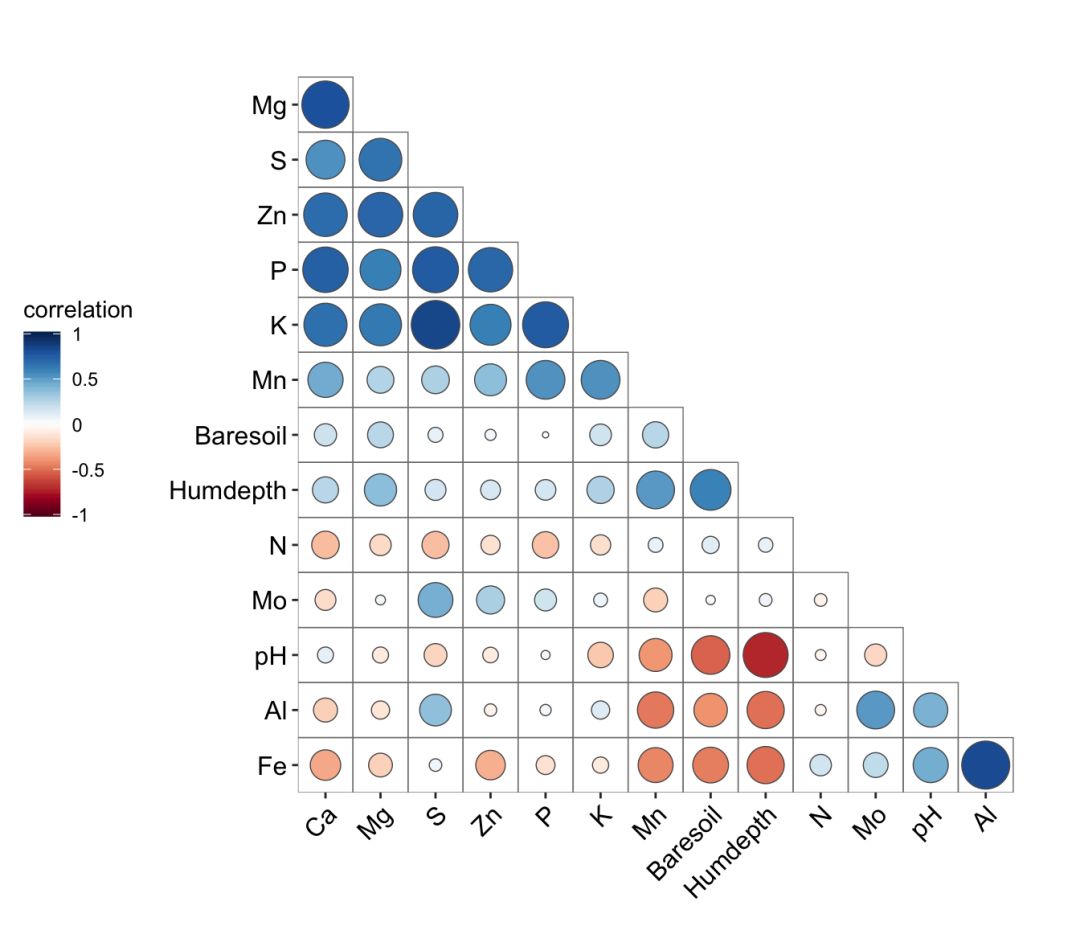
df05_lower FALSE)
ggcor(df05_lower) + geom_circle2()
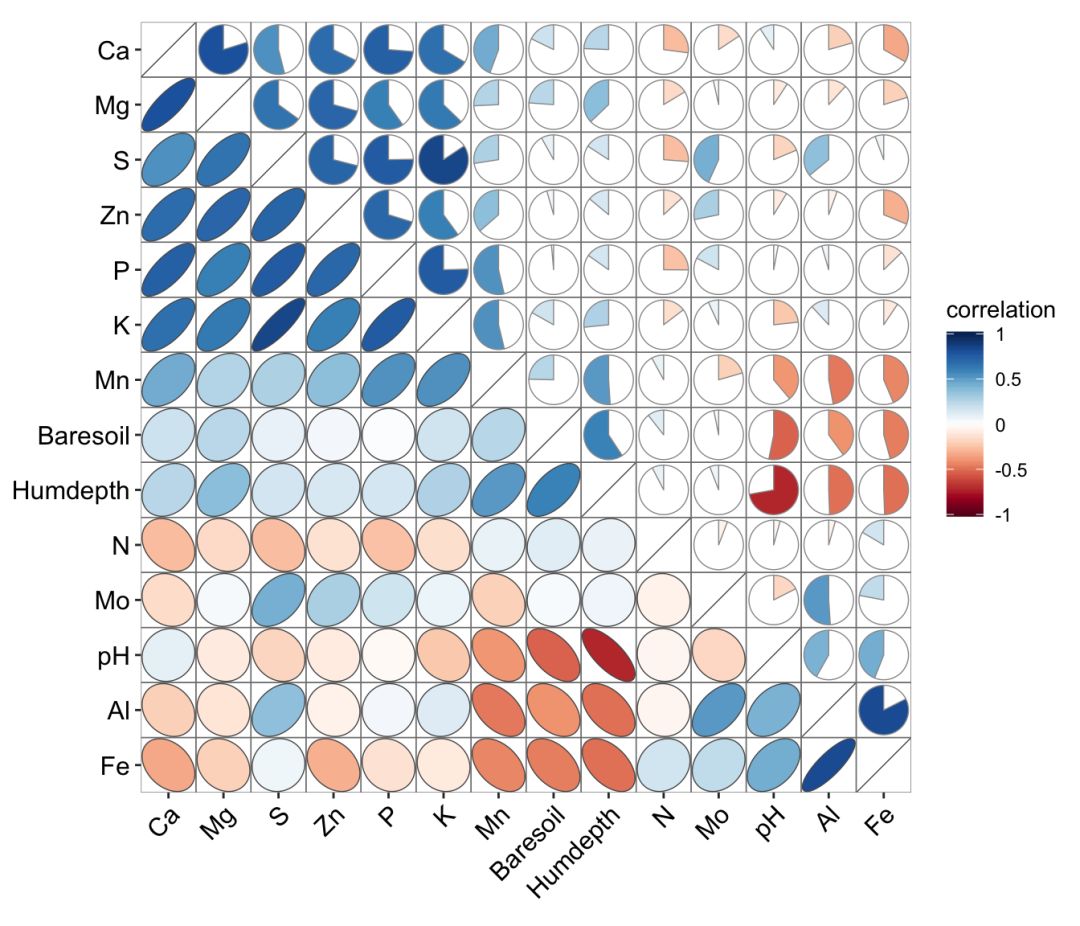
ggcor(df05) +
geom_pie2(data = get_data(type = "upper", show.diag = FALSE)) +
geom_ellipse2(data = get_data(type = "lower", show.diag = TRUE))
ggcor(df05) +
geom_segment(aes(x = x - 0.5, y = y + 0.5, xend = x + 0.5, yend = y - 0.5),
data = get_data(type = "diag"), size = 0.5, colour = "grey60") +
geom_colour(data = get_data(type = "upper", show.diag = FALSE)) +
geom_mark(data = get_data(type = "upper", show.diag = FALSE), size = 3) +
geom_circle2(data = get_data(r >= 0.5, type = "lower", show.diag = FALSE),
r = 0.8, fill = "#66C2A5") +
geom_num(aes(num = r), data = get_data(type = "lower",
show.diag = FALSE), size = 3)
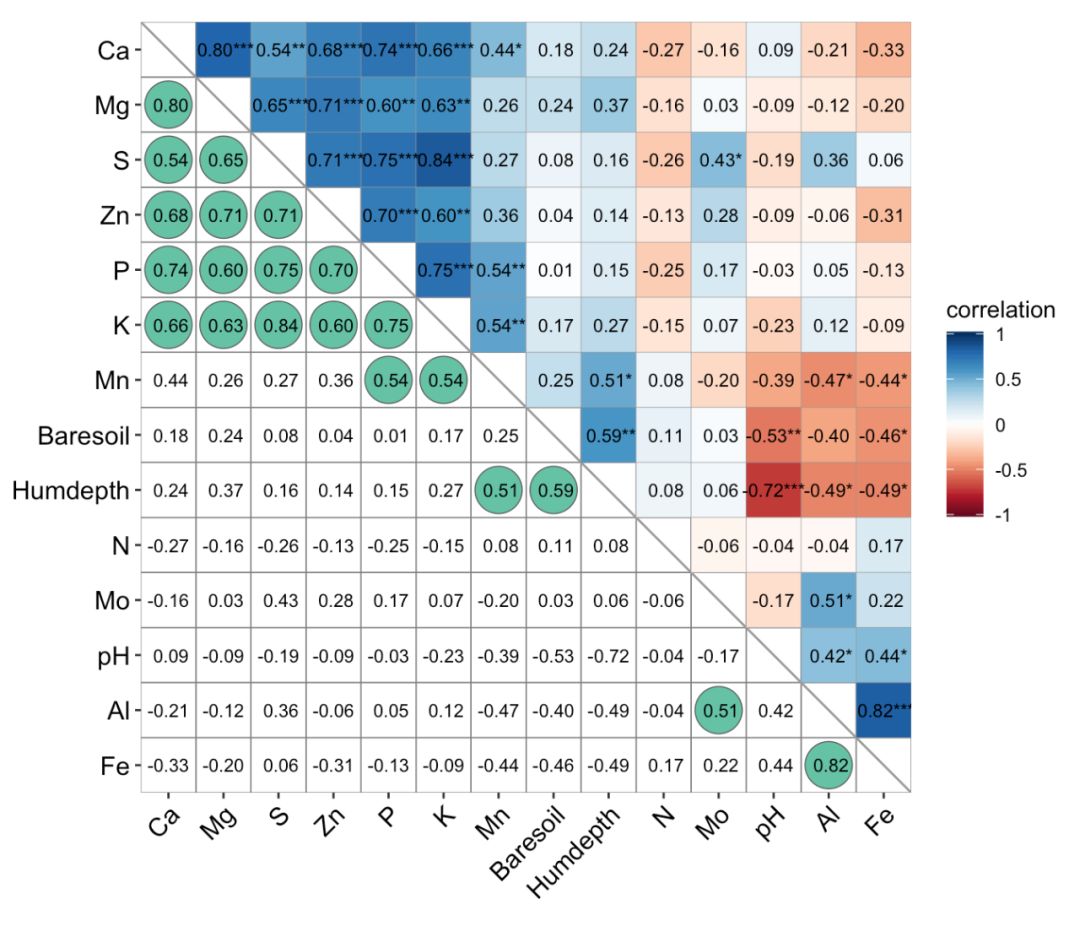
列名放在对角线?
ggcor(mtcars, cor.test = TRUE, cluster.type = "all") +
geom_confbox(data = get_data(type = "upper", show.diag = FALSE)) +
geom_num(aes(num = r), data = get_data(type = "lower", show.diag = FALSE), size = 3.5) +
add_diaglab(size = 4.56) + remove_axis()
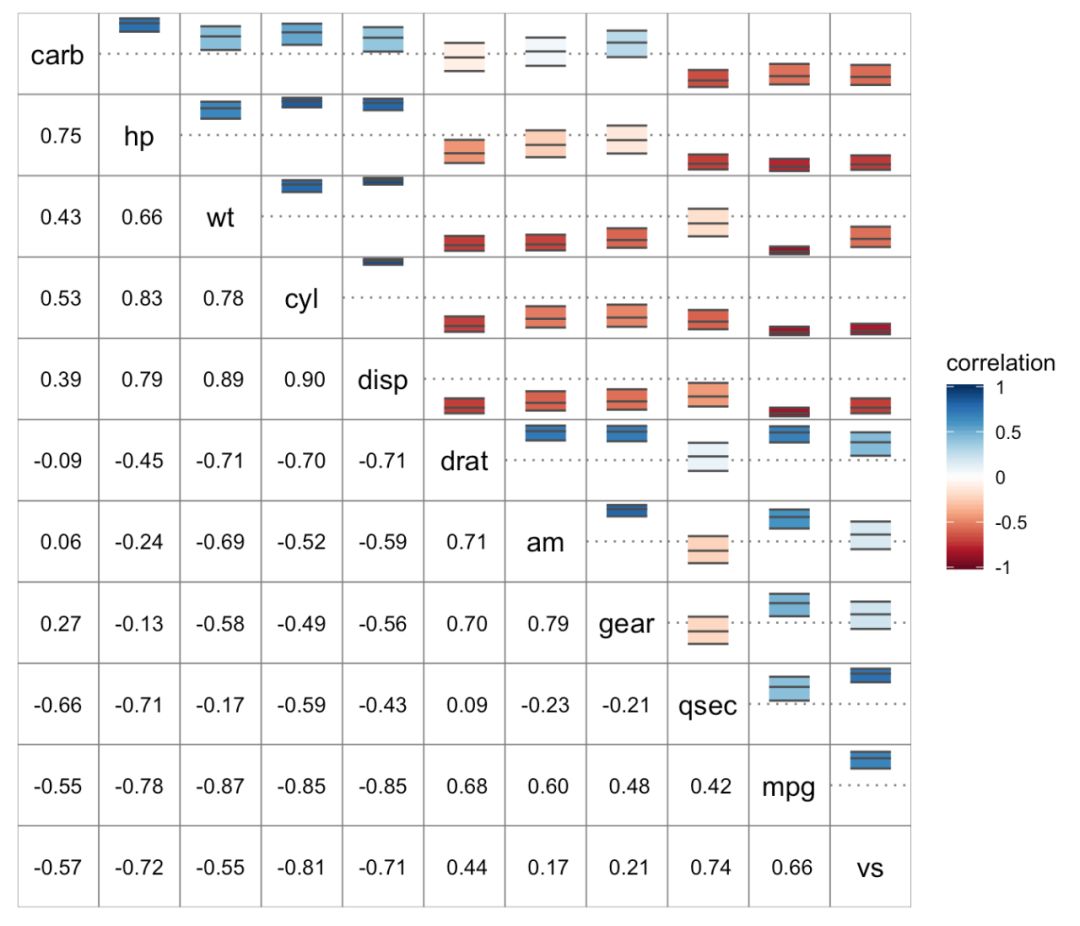
想对颜色分组?
很多情况下,连续性颜色棒并不是很好分区每个单元格对应的数值区间,这时根据相关系数大小对颜色进行分组可能更适合。说来非常巧合,一直头疼这个问题难以解决,就在前不久,
ggraph
包的作者Thomas Lin向
ggplot2
包提交了一组新的颜色映射函数(
scale_fill/colour_steps*()
),这个问题迎刃而解,非常幸运。
ggcor()
函数有参数
fill.binned
,默认为
FALSE
,设置为
TRUE
就会根据相关系数大小对颜色分组。若要控制分组的数量和区间,可以通过
legend.breaks
来设置。
ggcor(mtcars, fill.bin = TRUE) + geom_square()
ggcor(mtcars, fill.bin = TRUE, legend.breaks = seq(-1, 1, length.out = 11)) +
geom_square()
col col[6] "#F2F2F2"
ggcor(mtcars, cluster.type = "all", fill.colours = col, fill.bin = T,
legend.breaks = c(-1, -0.8, -0.5, 0.5, 0.8, 1)) +
geom_colour()
玩点花活
这部分内容要在线下载表情,很多时候会因为网络问题下载失败。不给图了。
library(ggimage)
emoji "1f004", "1f0cf", "1f170", "1f171", "1f17e",
"1f17f", "1f18e", "1f191", "1f192", "1f193",
"1f194", "1f195"
, "1f196", "1f197")
ggcor(df05) +
geom_pokemon(aes(image=ifelse(r > 0.5, 'pikachu', 'tauros')),
data = get_data(type = "lower", show.diag = FALSE)) +
geom_emoji(aes(image = ifelse(p <= 0.05, '1f600', '1f622')),
data = get_data(type = "upper", show.diag = FALSE)) +
geom_emoji(aes(image = emoji), data = get_data(type = "diag"))
ggcor(df05) +
geom_pokemon(aes(image=ifelse(r > 0.5, 'pikachu', 'tauros')),
data = get_data(type = "lower", show.diag = FALSE)) +
geom_colour(data = get_data(type = "upper", show.diag = FALSE)) +
geom_shade(data = get_data(type = "upper", show.diag = FALSE),
sign = -1, size = 0.1) +
geom_emoji(aes(image = emoji), data = get_data(type = "diag"))

mantel 检验组合图
mantel 检验(Mantel test 是对两个矩阵相关关系的检验)的组合图已经十分流行了,用各种工具做的都有。大概5月份的时候,我基于
corrplot
模拟重现了那幅图,直到现在每周都有人询问我相关实现的问题,我基本都是回答说等新方案,因为那个实现很复杂,没有基本的R知识,很难替换成自己的数据。8月底,我在
ggcorrr
(
ggcor
前身)开发了
gghpcc
,几乎可以满足可视化的要求,但是在优化
ggcor
的过程中,我才恍然大悟,mantel检验本质上也是相关性分析,何不统一整合进
ggcor
呢,就这样,
gghpcc
被干掉了。
进行案例展示之前,我先解释一个关键性问题,这个问题在目前框架下没有很好的办法去自动化解决方案,那就是坐标轴范围,需要手动设置。前文有提及,这里再重复一次
,
ggcor()
初始化的默认坐标范围是和correlation matrix的行列数相关的
,若行数为n,列数为m,x轴范围是c(0.5, m + 0.5),y轴的范围是c(0.5, n + 0.5)。
数据预处理函数
ggcor
提供了mantel检验的封装函数
fortify_mantel()
,支持
vegan
包中的
mantel()
、
mantel.partial()
和
ade4
包中的
mantel.randtest()
、
mantel.rtest()
函数,差别上说
mantel.partial()
是偏mantel检验(有控制变量),其它三个是mantel检验,当不使用并行计算时,
mantel.randtest()
速度最快(底层是C语言),
mantel.rtest()
最慢,纯粹R代码实现。
-
spec
是物种数据,支持列表(list,非data.frame)或者数据框(data.frame)。
-
-
若是数据框(最常见的情况),数据框中的每一列是一个物种(OTU),每行是一个样本,可以通过
spec.select
参数来指定哪些列构成一个群落。例如若
spec
中1-4列是spec01群落,5-12是spec02群落,
spec.select = list(spec01 = 1:4, spec02 = 5:12)
(当然,你也可以(最好不)不指定群落名称,这是名字自动命名)。还有一种情况(设置
spec.group
参数的情况)后面单独解释。
-
env
是环境数据,支持列表(list,非data.frame)或者数据框(data.frame),
env
中的每个元素对应一个环境变量(当然,若是列表,也可以支持多个环境变量组合成一个环境因素的情况)。还有一种情况(设置
env.group
参数的情况)后面单独解释。
-
env.ctrl
是环境控制变量,支持列表(list,非data.frame)或者数据框(data.frame)。需要注意,当
env.ctrl
非列表时,每次计算的控制环境是相同的,若需要分别设置不同的控制环境,需要通过列表手动设置。还有一种情况(设置
env.ctrl.group
参数的情况)后面单独解释。
-
mantel.fun
mantel函数,“mantel”、“mantel.randtest”、“mantel.rtest”和“mantel.partial”。
-
spec.dist.fun
物种距离函数,
vegdist
或者
dist
。
-
env.dist.fun
环境距离函数,
vegdist
或者
dist
。注意,当前的情况下,控制环境使用环境距离函数。
-
spec.dist.method
物种距离计算方法,参数默认是“bray”。
-
env.dist.method
环境距离计算方法,参数默认是“euclidean”。
-
...
其他传递给
mantel.fun
的参数。
group相关的参数是为了处理需要根据样本进行分组的情况,比如我A、B、C三个不同的样本分组,物种、环境和控制环境(均必须为数据框)同样如此,可以通过向量索引(和样本量等长)来指定分组。这时,每个样本组的物种只和对应样本组的环境列表的每个元素进行mantel测试。注意:以上情况均需要设置
is.pair = TRUE
。








