来源:arXiv
作者:闻菲
【新智元导读】
pix2pix 又有更新:悉尼大学的 Chaoyue Wang 等人受生成对抗网络(GAN)启发,在已有的感知损失基础上,提出了感知对抗网络(
Perceptual Adversarial Network,
PAN),能够持续地自动发现输出与真实图像间的差异,进一步提高图像转换的性能。在几种不同的图像转变任务中,PAN 的性能都超越了当前最优模型。

近来,卷积神经网络的发展,结合对抗生成网络(GAN)等崭新的方法,为图像转换任务带来了很大的提升,包括图像超分辨率、去噪、语义分割,还有“自动补全”,都有亮眼的表现。
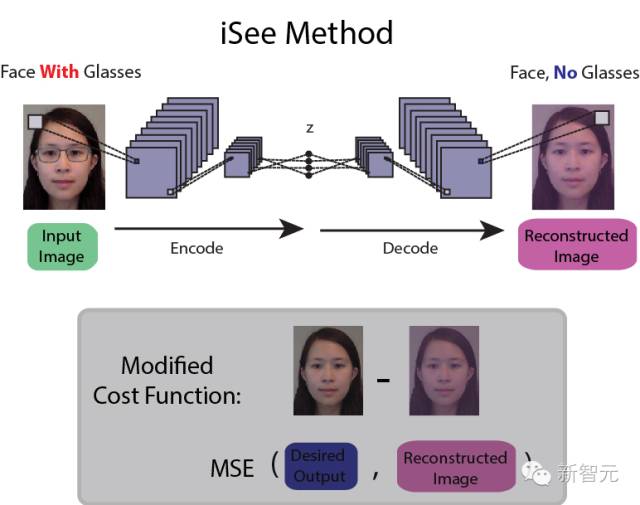
例如,新智元此前介绍过的使用神经网络去除照片中的眼镜,
i
See:深度学习“摘眼镜”,用集成数据训练神经网络识别抽象物体
。
还有
神经网络学会自动“脑补”
:

对于给定的一张带有孔洞(256×256)的图像(512×512),神经补丁合成算法可以合成出更清晰连贯的孔洞内容(d)。
神经补丁合成的
结果可以与用Context Encoders(b)、PatchMatch(c)这两种方法产生的结果进行比较。
以及前一阵子很火的“画猫”项目:勾勒出物体边缘,神经网络就能自动补完生成对应的照片。

所有这些都很好。
那么,如果现在出现了一种框架,能够胜任上述所有图像转换任务,并且实现效果比每种单独的模型都要好呢?
还真的出现了,那就是我们今天要介绍的感知对抗网络 PAN。先来看看 PAN 在几种不同的图像转换任务上的表现:



以上分别是去除图中雨水痕迹(类似去除眼镜)、补全图像空白,以及根据边缘生成对应物体照片的实现效果。
如何?PAN 是不错的 pix2pix 更新吧。
感知对抗网络 PAN,持续寻找并缩小输出与真实图像间的差异
我们知道,生成对抗损失有助于计算机自动生成更加逼真的图像。此前有工作将像素损失和生成对抗损失整合为一种新的联合损失函数,训练图像转换模型产生分辨率更清的结果。
还有一种评估输出图像和真实图像之间差异的标准,那就是感知损失(perceptual loss)。这种情况更多见于图像的风格化,一般使用训练好的图像分类网络,提取输出图像和真实图像的高级特征(比如内容、纹理)。通过缩小这些高级特征之间的差异,训练模型将输入图像转变为与真实图像拥有相同高级特征的输出。
一般来说,结合使用多种损失(函数)的效果通常比单独使用一种要好。事实上,通过整合像素损失、感知损失和生成对抗损失,研究人员在图像超高分辨率和去除雨水痕迹上取得了当前最好的结果。
但是,现有方法将输出图像和真实图像之间所有可能存在的差异都惩罚了吗?换句话说,
我们能不能找到一种全新的损失,进一步缩小输出图像与真实图像之间差异呢?
为了回答这个问题,悉尼大学的 Chaoyue Wang 等人提出了感知对抗网络(perceptual adversarial network,PAN)用于图像转换。
作者写道,他们的论文作了如下贡献:
-
提出了一种感知对抗损失,利用判别网络的隐藏层,通过对抗训练过评估输出和真实图像之间的差异。
-
结合感知对抗损失和生成对抗损失,提出了感知对抗网络 PAN 这一框架,处理图像转换任务。
-
评估 PAN 在多项图像转换任务中的性能。实验表明,PAN 具有很好的图像转换性能。
感知损失+GAN,在图像转换网络与判别网络间做对抗训练
感知对抗网络受生成对抗网络(GAN)的启发,包含一个图像转换网络
T
和一个图像判别网络
D
。
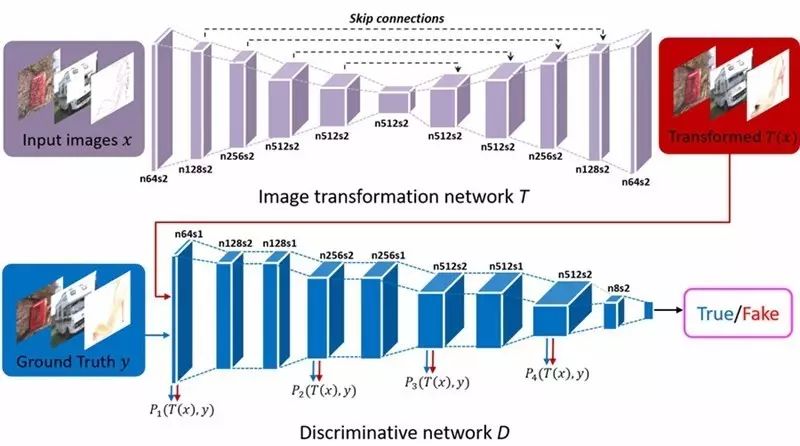
PAN 框架示意图。PAN 由图像变换网络
T
和判别网络
D
组成。图像转变网络
T
经过训练,负责合成给定输入图像的变换图像。判别网络
D
的隐藏层用于评估感知对抗损失,
D
的输出用于区分转变后的图像和真实图像间的差异。
作者使用生成对抗损失和感知对抗损失的结合来训练 PAN。首先,与 GAN 一样,生成对抗损失负责评估输出图像的分布。然后,判别网络
D
隐藏层的表征作为感知对抗损失,当输出和真实图像间存在差异时,会实施惩罚,训练转换网络
T
生成与真实图像拥有相同高级特征的输出。
感知对抗损失在图像转换网络和判别网络之间进行对抗训练,能够持续地自动发现输出与真实图像间那些尚未被缩小的差异。
因此,当前高维空间上测量到的差异很小时,判别网络
D
的隐藏层仍然会更新,持续寻找新的、在输出和真实图像之间仍然存在差异的高维空间。
作者表示,感知对抗损失提供了一种新的策略,从尽可能多的角度来惩罚(缩小)输出和真实图像之间的差异。
下面是去除雨水痕迹、生成语义标记和画线生成照片的实验,由图可知 PAN 不仅同时胜任了这几种不同的任务,且单项的效果比几种当前性能最优的方法还要好。




摘要
在本文中,我们提出了一种用于图像转换任务的原理感知对抗网络(Perceptual Adversarial Network,PAN)。与现有算法不同——现有算法都是针对具体应用的,PAN 提供了一个学习成对图像间映射关系的通用框架(图1),例如将下雨的图像映射到相应的去除雨水后的图像,将勾勒物体边缘的白描映射到相应物体的照片,以及将语义标签映射到场景图像。
本文提出的 PAN 由两个前馈卷积神经网络(CNN)、一个图像转换网络
T
和一个判别网络
D
组成。通过结合生成对抗损失和我们提出的感知对抗损失,我们训练这两个网络交替处理图像转换任务。其中,我们升级了判别网络
D
的隐藏层和输出结果,使其能够持续地自动发现转换后图像与相应的真实图像之间的差异。
同时,我们训练图像转换网络
T
,将判别网络
D
发现的差异最小化。经过对抗训练,图像转换网络
T
将不断缩小转换后图像与真实图像之间的差距。我们评估了几项到图像转换任务(比如去除图像中的雨水痕迹、图像修复等)实验。结果表明,我们提出的 PAN 的性能比许多当前最先进的相关方法都要好。
论文地址:https://arxiv.org/pdf/1706.09138.pdf

点击阅读原文查看新智元招聘信息





