

编译:张秋玥、罗然、云舟
细分客户群是向客户提供个性化体验的关键。它可以提供关于客户行为、习惯与偏好的相关信息,帮助企业提供量身定制的营销活动从而改善客户体验。在业界人们往往把他吹嘘成提高收入的万能药,但实际上这个操作并不复杂,本文就将带你用简单的代码实现这一项目。
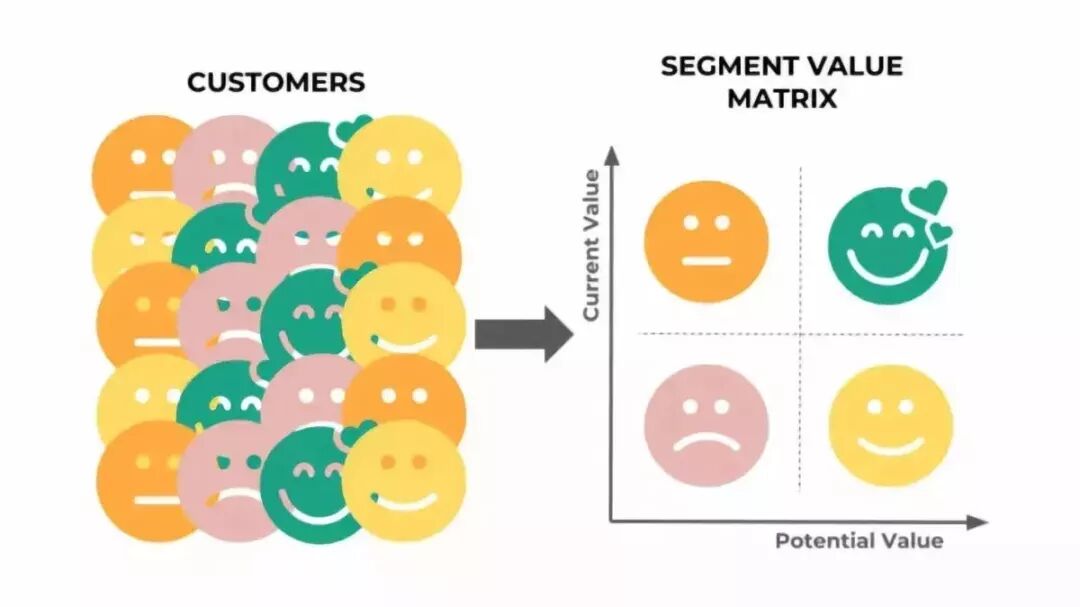
客户细分
我们需要创建什么?
通过使用消费交易数据,我们将会通过创建一个2 x 2的有价值属性的矩阵来得到4个客户群。每一个客户群将与其他群体有两大区别,即当前客户价值和潜在客户价值。
我们将使用什么技术?
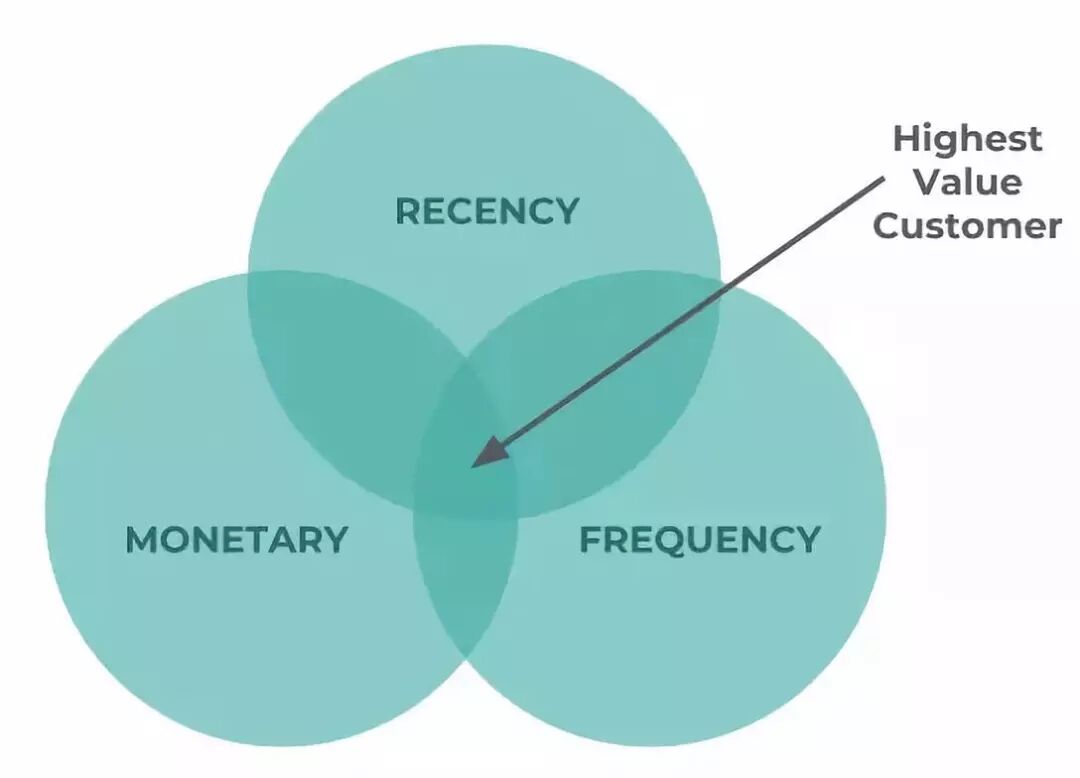
我们将使用RFM模型从消费交易数据中创建所需变量。RFM模型代表:
• 最近消费(Recency):他们最近一次消费是什么时候?
• 消费频率(Frequency):他们多久消费一次、一次消费多久?
• 消费金额(Monetary):他们消费了多少?
该模型通常被用于在三个属性交叉处寻找高价值客户。但在本例中,我们将仅适用R(最近消费)与M(消费金额)来创建二维矩阵。
RFM模型
我们使用什么数据?
我们将使用Tableau提供的消费数据样本——它也被称为“Global Superstore”。它通常被用于预测与时间序列分析。该数据集包含超过1500位不同客户4年的消费数据。既然我们做的是行为细分而非人口细分,我们将通过仅选择B2C领域的消费者以及美国区域的消费数据来去除潜在的人口偏差。
我们采取什么方法?
第0步:导入、筛选、清理、合并消费者层级数据。
第1步:为每一位消费者创建RFM变量。
第2步:为实现自动细分,我们将使用R与M变量的80%分位数;我们其实还可以用k均值聚类(K-mean Clustering)或者利用商业背景知识来进行群体区分——比如,全球超市企业用户将活跃客户定义为最近一次订单在100天内的客户。
第3步:计算RM分数,并对客户进行排序。
第4步:可视化价值矩阵,并对关键指标进行进一步分析。
Python实现:
第0步:导入、筛选、清理、合并消费者层级数据。
import matplotlib as plt
import numpy as np
%matplotlib inline
import warnings
warnings.filterwarnings(‘ignore’)
import pandas as pd
url = ‘https://github.com/tristanga/Data-Analysis/raw/master/Global%20Superstore.xls’
df = pd.read_excel(url)
df = df[(df.Segment == ‘Consumer’) & (df.Country == ‘United States’)]
df.head()
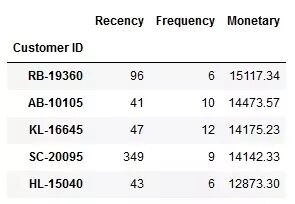
第1步:为每一位消费者创建RFM变量。
df_RFM = df.groupby(‘Customer ID’).agg({‘Order Date’: lambda y: (df[‘Order Date’].max().date() – y.max().date()).days,
‘Order ID’: lambda y: len(y.unique()),
‘Sales’: lambda y: round(y.sum(),2)})
df_RFM.columns = [‘Recency’, ‘Frequency’, ‘Monetary’]
df_RFM = df_RFM.sort_values(‘Monetary’, ascending=False)
df_RFM.head()
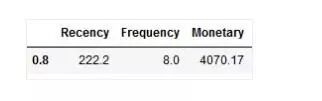
第2步:使用R与M变量的80%分位数实现自动细分。
# We will use the 80% quantile for each feature
quantiles = df_RFM.quantile(q=[0.8])
print(quantiles)
df_RFM[‘R’]=np.where(df_RFM[‘Recency’]<=int(quantiles.Recency.values), 2, 1)
df_RFM[‘F’]=np.where(df_RFM[‘Frequency’]>=int(quantiles.Frequency.values), 2, 1)
df_RFM[‘M’]=np.where(df_RFM[‘Monetary’]>=int(quantiles.Monetary.values), 2, 1)
df_RFM.head()
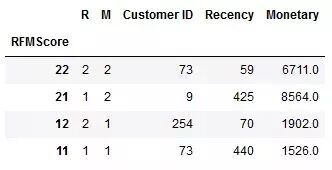
第3步:计算RM分数,并对客户进行排序。
# To do the 2 x 2 matrix we will only use Recency & Monetary
df_RFM[‘RMScore’] = df_RFM.M.map(str)+df_RFM.R.map(str)
df_RFM = df_RFM.reset_index()
df_RFM_SUM = df_RFM.groupby(‘RMScore’).agg({‘Customer ID’: lambda y: len(y.unique()),
‘Frequency’: lambda y: round(y.mean(),0),
‘Recency’: lambda y: round(y.mean(),0),
‘R’: lambda y: round(y.mean(),0),
‘M’: lambda y: round(y.mean(),0),
‘Monetary’: lambda y: round(y.mean(),0)})
df_RFM_SUM = df_RFM_SUM.sort_values(‘RMScore’, ascending=False)
df_RFM_SUM.head()
第4步:可视化价值矩阵,并对关键指标进行进一步分析。
# 1) Average Monetary Matrix
df_RFM_M = df_RFM_SUM.pivot(index=’M’, columns=’R’, values=’Monetary’)
df_RFM_M= df_RFM_M.reset_index().sort_values([‘M’], ascending = False).set_index([‘M’])
df_RFM_M
# 2) Number of Customer Matrix
df_RFM_C = df_RFM_SUM.pivot(index=’M’, columns=’R’, values=’Customer ID’)










