AI科技评论按:本文为近日召开的CoRL 2017大会上,MIT TR 35得主、UC Berkeley助理教授 Anca Dragan 所做的演讲整理,AI科技评论作为受邀媒体参加了CoRL大会,并与Anca Dragan进行了交流。

Anca Dragan现任UC Berkeley的电子工程与计算机科学助理教授及InterACT实验室主任。
为了令机器人更好地协同人类工作,Anca Dragan带领InterACT实验室开始专注于人机交互算法的研究,试图将复杂或模糊的人类行为转化为机器人能理解的简易数学模型,通过建立博弈理论和动力系统理论,聚焦于发现或学习人类行为模型,并计算连续状态和行动空间。
MIT科技评论给她评的奖项为“远见者”,称“她致力于确保机器人与人类可以和谐地共同生活”。在获奖报道中,Anca Dragan表示:
当人们试图与机器人共事时,许多冲突都来自于双方对彼此的不了解,如果机器人能够理解它可能对人类情绪造成的影响,就有望解决这一问题。
Anca Dragan认为,机器人与人工智能的正确观点应该是机器人试图优化人的目标函数。机器人不应该将任何客观的功能视为理所当然,而应该与人类一起去发现他们真正想要的是什么。该研究在短期之内最重要的应用莫过于帮助自动驾驶汽车与传统汽车预判对方可能的行为。
在演讲中,Anca Dragan也多次提到了这一点。以下即为AI科技评论整理的演讲内容摘要:

Anca Dragan的PPT题目为《人类进入机器人方程》。在传统的机器人路径规划问题中,机器人通常将人类视为和其他不能移动的物体一样的避障目标,而Anca希望将人类作为机器人决策的一个“变量”实现和人类的最优交互。
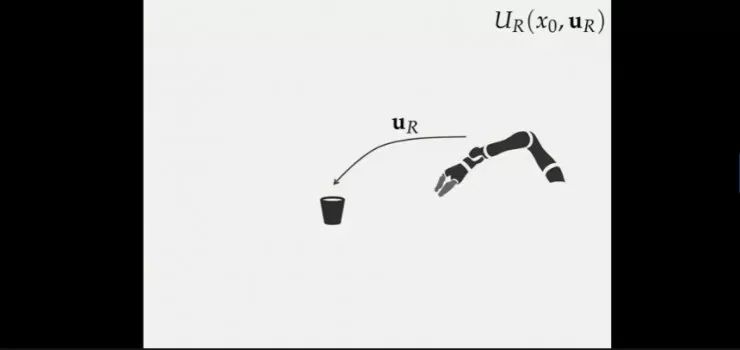
最简单的状态,只有机器人和交互的物体,则机器人的效用函数为UR,该效用函数包含的变量包括初始状态x0以及运动轨迹uR。

但现实中,机器人需要和三类不同的人打交道:在运行环境中的其他人、其使用者,以及其设计者。
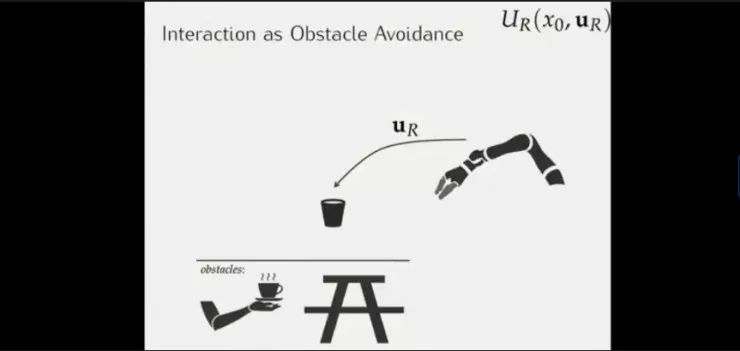
出于安全的考虑,以往通常将人视为机器人行动和路线规划中需要避让的“障碍物”;

但在人类交互当中往往存在某种博弈行为,如这个超车变道的例子,黑色小车意图超车,但银色卡车寸步不让。如果我们与他人的交互都像这个司机一样,则会造成许多冲突,但无人驾驶车不会像小汽车司机这样做,他们会感知到这里可能没有足够的超车空间,会选择减速在卡车后变道;

如果我们将人视为需要规避的障碍物进行建模,那意味着我们将人类视为这个例子中不会改变主意的卡车司机一样进行建模。

另一个Google Car无法顺利通过四面都有停车标志的十字路口的例子。在这个例子中,传感器会一直探测到有人类司机并进行避让,而人类司机可以通过一寸一寸向前挪动让Google无法行动。

漫画:“你先走还是我先走?”在图中,无人车让人类先走,但行人并不打算走而是挥舞手臂,则会让无人车困惑。
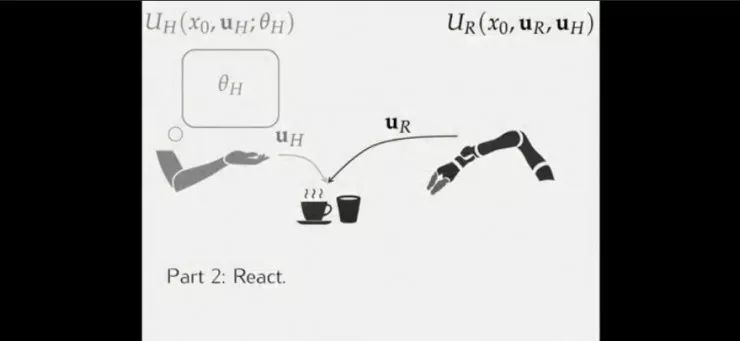
机器人与人类的互动。此时机器人的效用函数UR包含三个变量:初始状态x0、机器人运动轨迹uR以及人类运动轨迹uH,此时人类的效用函数UH也包含三个变量:初始状态x0、人类运动轨迹uH以及觉察到有机器人后的隐形影响因子θH;
我们现在在做的研究:人并不是障碍,而是将其视为需要通过自己效用函数进行优化的智能体,但我们并不知道其效用函数,参数是隐藏的;机器通过人的动作估计隐藏状态,估计其下一步行为,如果机器人对人的下一步动作有估计,那么机器人会将其加入到自己的效用函数中:如果这件事情发生,我应该怎么做才是最好的选择。
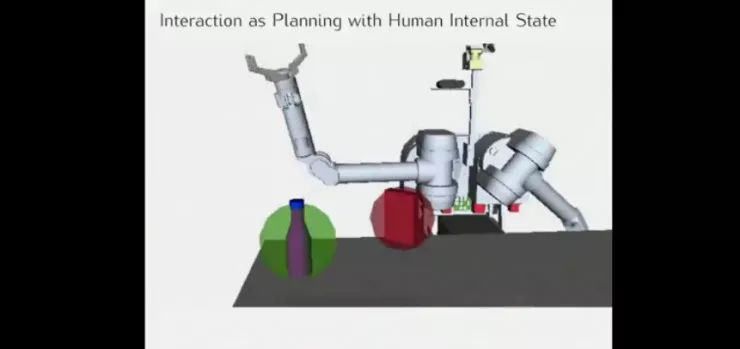
Anca 6年前做的研究,与人类内部状态的相互作用,机器预测我要做什么,并帮我更好实现目标。
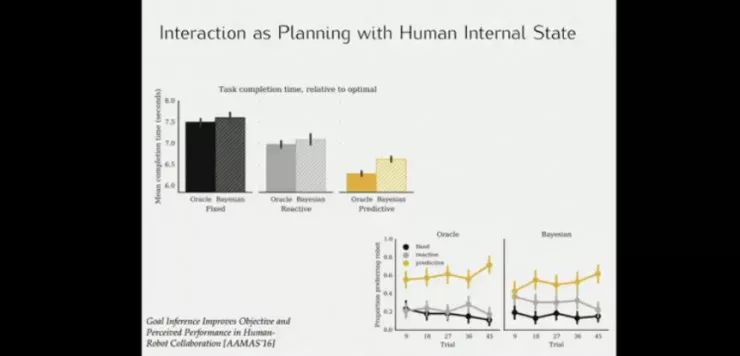
以及最近的Paper。
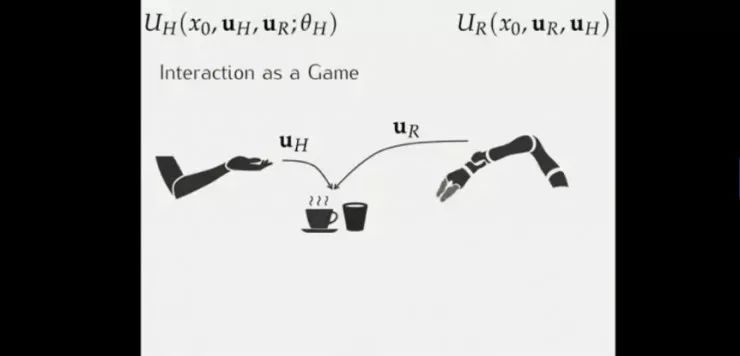
当人类也考虑机器人的行为来调整自己的行为时,其效用函数UH变为四个变量:初始状态x0、人类运动轨迹uH、机器人运动轨迹UR及觉察到有机器人后的隐形影响因子θH。有不少证据表明人们实际上并不一定去在博弈中实现均衡,因为人类是通过计算达到平衡的。

我们如何说明机器人对人类行为的影响?
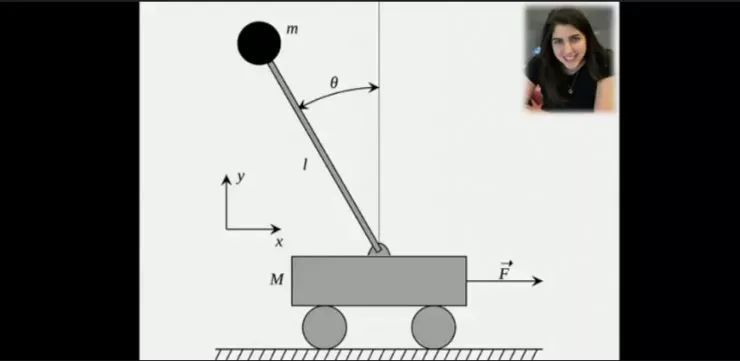
例如,在这个轨道车的例子中,你的效用函数和你如何动操作杆有关;
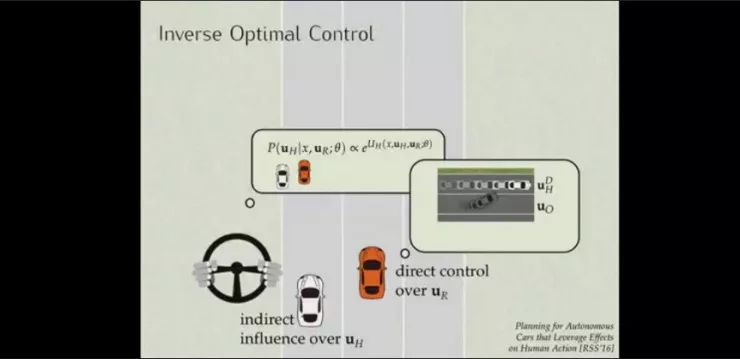
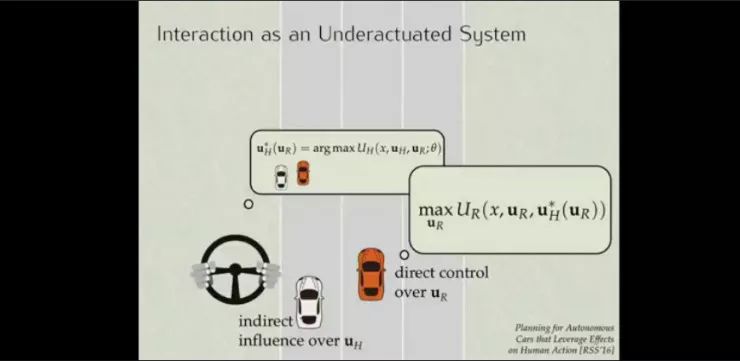
再看一个无人车与人类司机交互的例子。上图中的橙色汽车是无人驾驶车,UR是无人驾驶车轨迹,UH是人类驾驶轨迹,如果我们考虑的是在特定的UR下,UH应该如何达到最优,这样人类可以更好地响应机器人的行为。
在这个例子中,这是一个保证效率和安全的博弈。人类的参数是隐藏的,我们通过反向优化控制来猜测这些数据,机器人收集这些展示人们将如何与机器人互动的数据,设置一个最大似然观察,然后机器人去解决这个嵌套优化问题,即当人不可避免地受到我所做的事情的影响时,我该怎么做才能最大限度地将我的效用最大化?最终会达到人和机器人的和谐协作。
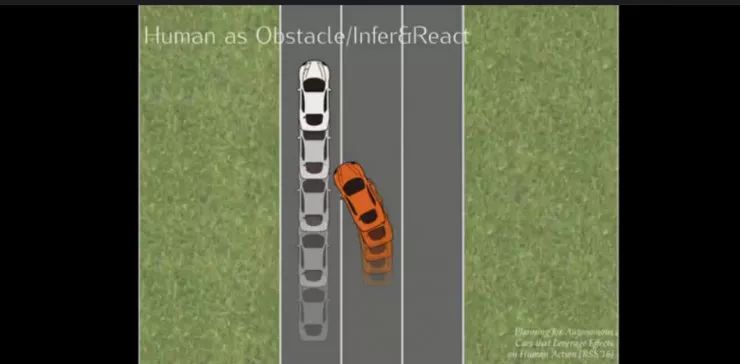

接下来Anca展示了一些简化后的例子。如果将人类车辆当做一个需要避障的目标并推断其行为,无人车通常在人类车辆后变道。
在少数情况下,人类车辆之前有充足的空间的时候,无人车会超车变道,因为在这个嵌套优化中,机器人知道,如果它按这一方式超车变道,那么人的反应就是放慢速度,让无人车进入。

在这一模式中,机器人不再处于被动状态,而是更好地和人进行互动。
Anca称她最喜欢的一个例子是,仍然是四面停止标志的十字路口,当处于僵持、没有乘客的无人车(橙色)需要表示“你先走”的时候,无人车会稍稍后退,在这个路口中,人类司机同样在进行效率和安全的博弈,而当无人车后退的时候,车辆相撞的几率变小,此时人类司机就会通过路口,达到人类车辆效用函数的最大化。
这是一个无人车影响人类效用函数的例子,同时也是很令人惊异的发现,因为人类司机从不会通过后退表示让对方先走。
同样在这个漫画的例子中,无人车也可以通过稍稍后退让行人先走打破僵局。
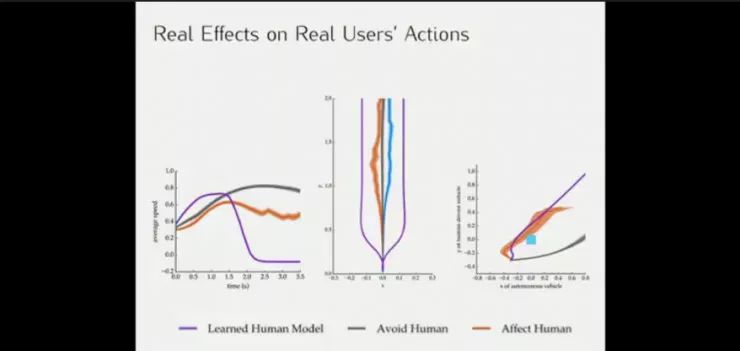
三种模型下,真实用户不同反应的影响。

这一模型仍然存在某些局限性,如效用局限于已知的Feature的线性组合,假设感知问题已经得到解决,对车辆运行进行了简化,等等。
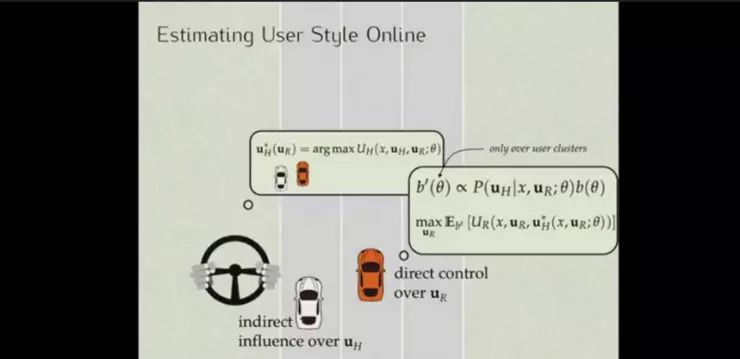 而且我们不能用一些线下训练的模型来用来套到实际的驾驶中,万一遇到之前那个不肯避让的二愣子卡车司机就麻烦了。所以需要对每个司机的行为进行具体的估计。
而且我们不能用一些线下训练的模型来用来套到实际的驾驶中,万一遇到之前那个不肯避让的二愣子卡车司机就麻烦了。所以需要对每个司机的行为进行具体的估计。
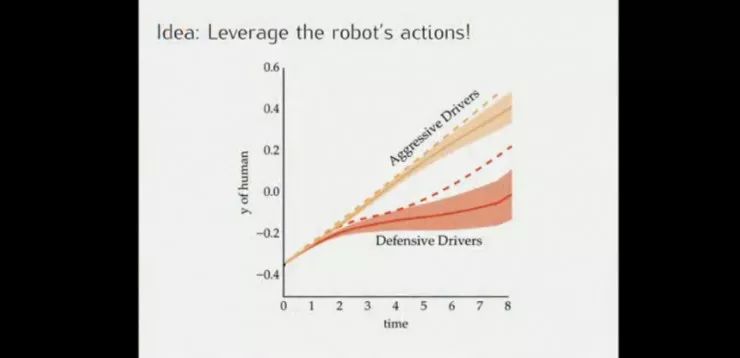
通过对人类司机驾驶轨迹的观察,可以推断出司机的驾驶风格:比较激进或者比较保守,并采取正确的策略,如判断对方是一个保守型的司机的时候,在其前面变道超车对方通常会避让。

像这种情况的激进型司机,无人车只能放弃变道。
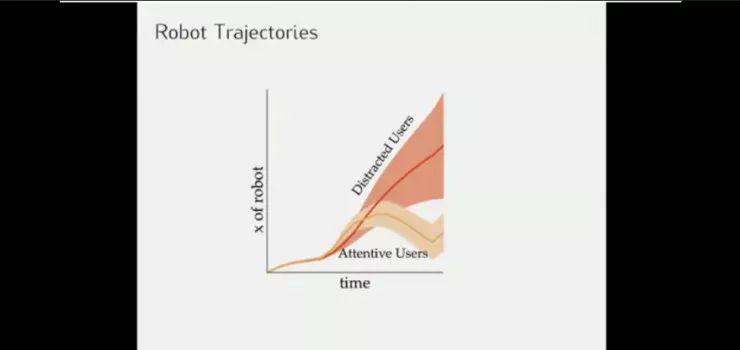
而在十字路口的例子中,无人车需要判断这个司机是否注意其他车辆的动作。

在优化之外的紧急场景的系统协调策略又是怎样的呢?
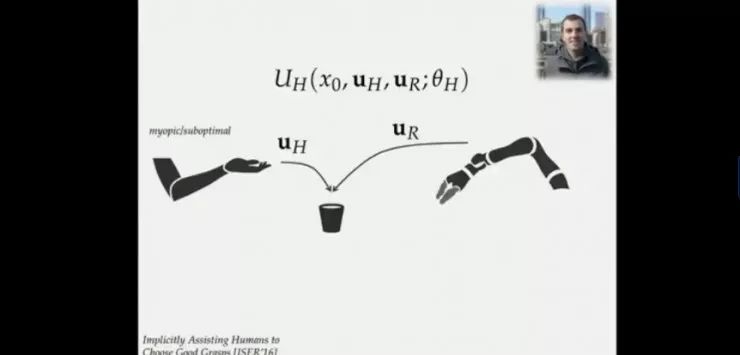

当仅和最终用户交互的时候,无需考虑两个效用函数,只需要和人类站一边考虑UH最大化即可。
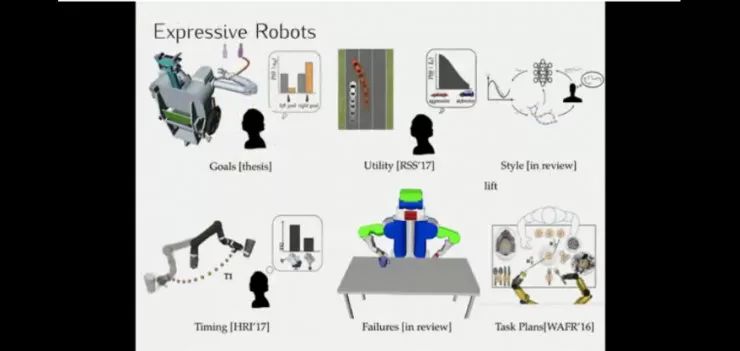
上述讨论的很多都是机器人如何估计人类隐藏参数的研究,另一种方式则是人如何思考与机器人互动中的参数的推断,这方面的研究一直在进行,而且需要机器人有更多的表现力。
对于不同人,机器人同样的动作也会产生不同的后果,即便人类无法正确推断机器人行为的时候,至少要让他们知道发生了什么事,你想做的是什么,为什么交互没有取得更好的结果等等。
机器人需要注意这个更微妙的影响,因为它决定了人们是否了解机器人正在做什么,是否有信心在执行任务等。

然而我们(设计者)在为机器人指定效用函数的时候做的不怎么样,机器人的奖励值通常具有不确定性,这往往会带来出人意料的结果。
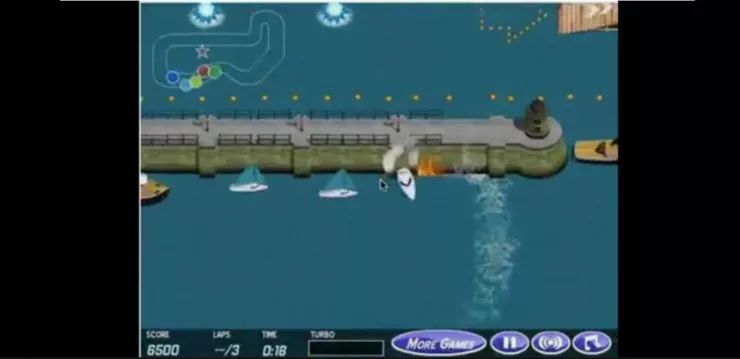
例如在OpenAI的一篇论文中,白色小船的目标是在游戏中获得尽可能多的分,但在这里白色小船却偏离了赛道打起圈子(因为能不断吃到宝箱)。
另一个例子,如果设定一个吸尘机器人的奖励函数是吸尽量多的灰尘,那么机器人会不会在吸完灰尘后把手机起来的灰尘倒出来,然后继续吸尘以达到最大的奖励值?

又或者,像迪士尼动画片米奇用魔法教一把扫把帮其挑水,最后这把扫把不断挑水(获得最大奖励值)把整个屋子给淹了一样;
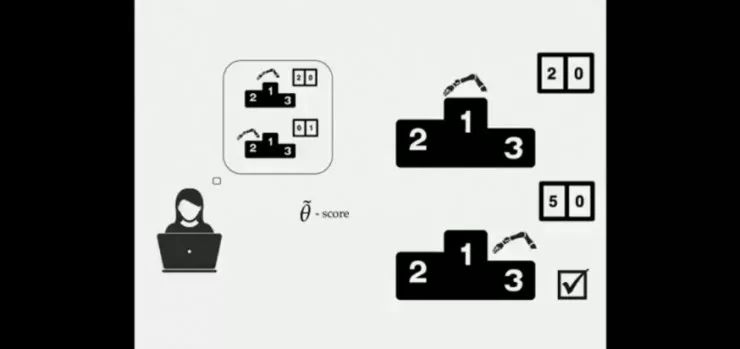
让我们来分析一下这是如何产生的。例如小船游戏的例子,当设置得分为奖励值,当机器发现有两个策略:1)排名第一但仅获得20分;2)排名靠后但能获得50分,机器人选择的是后者。
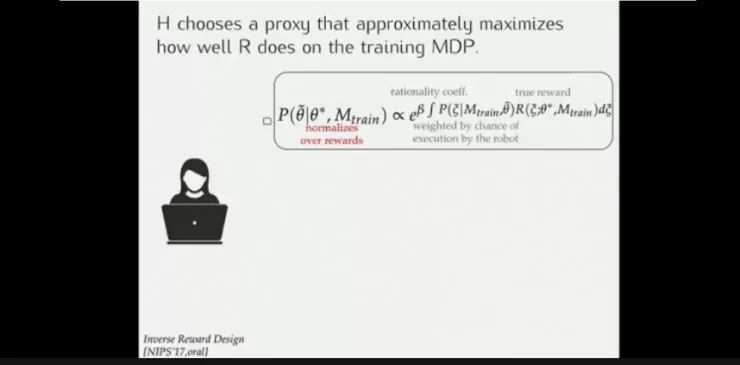
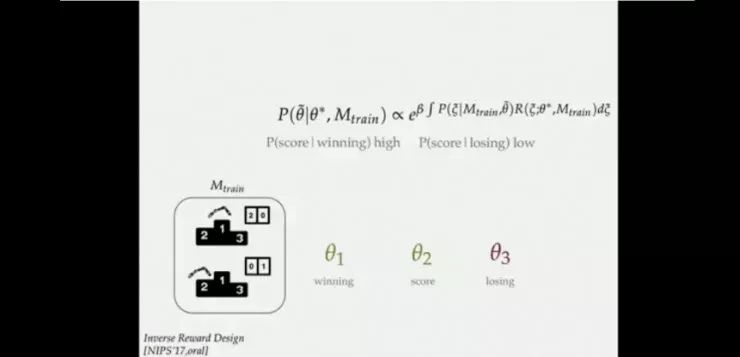
这样,设计者需要改变奖励值(找到真正的奖励值)以使得机器人按预定目标进行决策,或者让机器人能够推测到设计者的真正意图。但二者均有不足之处。
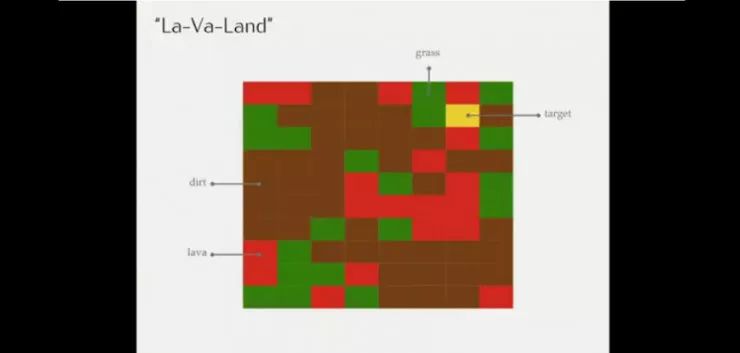
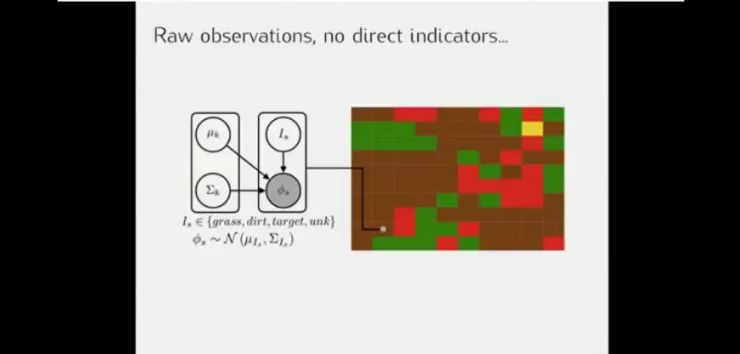
另一个包含草地、灰尘、熔岩和最终目标的导航场景的例子。
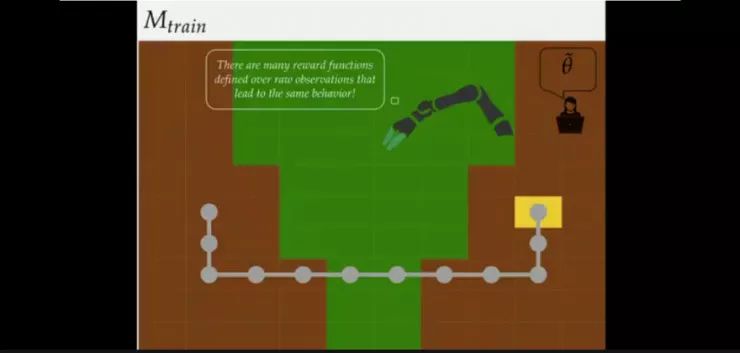
假设训练时的状态,奖励函数是尽可能少走草地得分越高的话,结果会如上图所示(此时没有出现熔岩)。

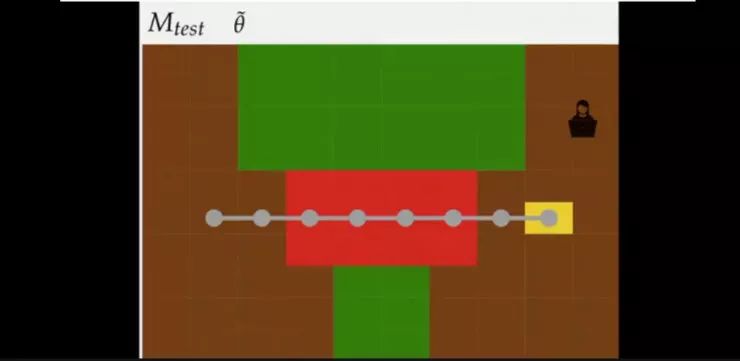
策略1:设计师有基于指标的指示器,并建立从原始观察值到指标的分类器,此时将训练的模型放到有岩浆的例子中时,机器人往往会越过岩浆到达终点(并非想要的结果)

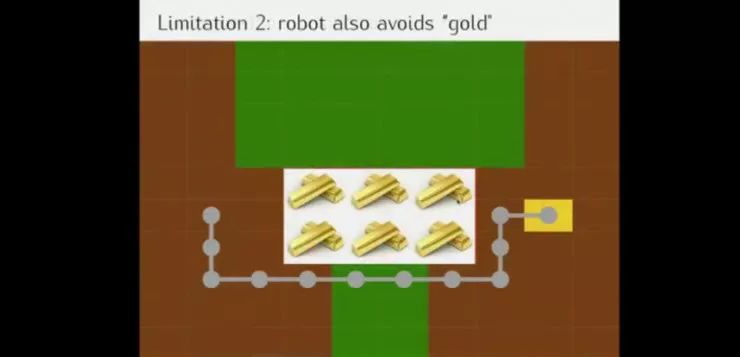
策略2:而如果设定反向激励,机器人会对训练时未出现的元素敬而远之,机器人不知道岩浆是好鸡还是怀,也可能如上图所示错过“金矿”。


通过以上例子,说明需要在训练环境的背景下对特定的奖励进行观察找到真正的奖励,而在执行中人类的指导则是找到真正奖励的关键(如迪士尼动画片中,米奇让扫把停止打水)。
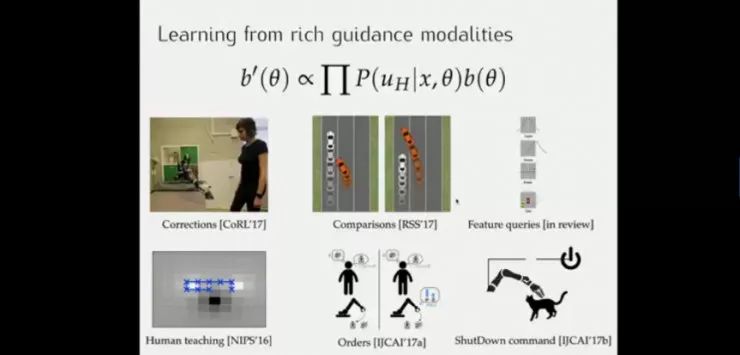
这样,机器人可以从从丰富的指导模式中学习。
简单来说,如果机器人能够理解它可能对人类情绪造成的影响,就可以更好地进行决策,并在更广泛的领域于人类更有效进行协作,给我们生活带来更多便利与惊喜。
————— AI 科技评论招人啦! —————
我们诚招学术编辑 N 枚(全职,坐标北京)、新媒体运营 N 枚(全职,坐标深圳)、学术兼职 N 枚。
欢迎发送简历到 [email protected]
————— 给爱学习的你的福利 —————
不要等到算法出现accuracy不好、loss很高、模型overfitting时,
才后悔没有掌握基础数学理论!
线性代数及矩阵论, 概率论与统计, 凸优化
AI慕课学院机器学习之数学基础课程即将上线!
扫码进入课程咨询群,组队享团购优惠!
详细了解点击文末阅读原文

————————————————————









