跨域数据融合全套PPT分章节全部公开(300MB+),算法结合案例,助力攻克数据挖掘和机器学习新难点,抢占大数据和人工智能制高点。
1. Overview
Traditional data mining usually deals with data from a single domain.
In the big data era, we face a diversity of datasets from different
sources in different domains. These datasets consist of multiple
modalities, each of which has a different representation, distribution,
scale, and density. How to unlock the power of knowledge from multiple
disparate (but potentially connected) datasets is paramount in big data
research, essentially distinguishing big data from traditional data
mining tasks. This calls for advanced techniques that can fuse the
knowledge from various datasets organically in a machine learning and
data mining task. These methods focus on knowledge fusion rather than
schema mapping and data merging, significantly distinguishing between
cross-domain data fusion and traditional data fusion studied in the
database community.
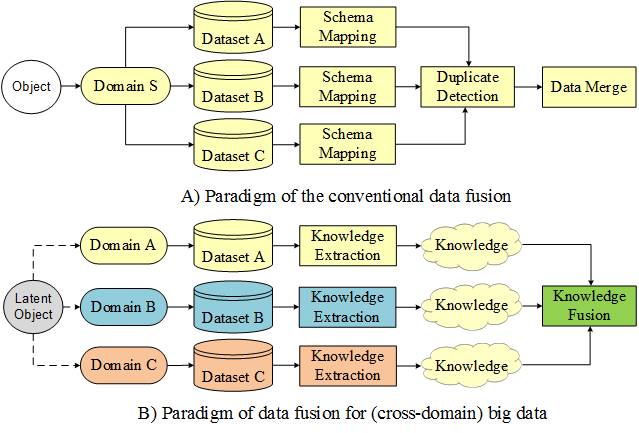
Figure 1. The difference between cross-domain data fusion and conventional data fusion
This tutorial summarizes the data fusion methodologies, classifying them into three categories: stage-based, feature level-based, and semantic meaning-based data fusion methods. The last category of data fusion methods is further divided into four groups: multi-view learning-based, similarity-based, probabilistic dependency-based, and transfer learning-based methods.
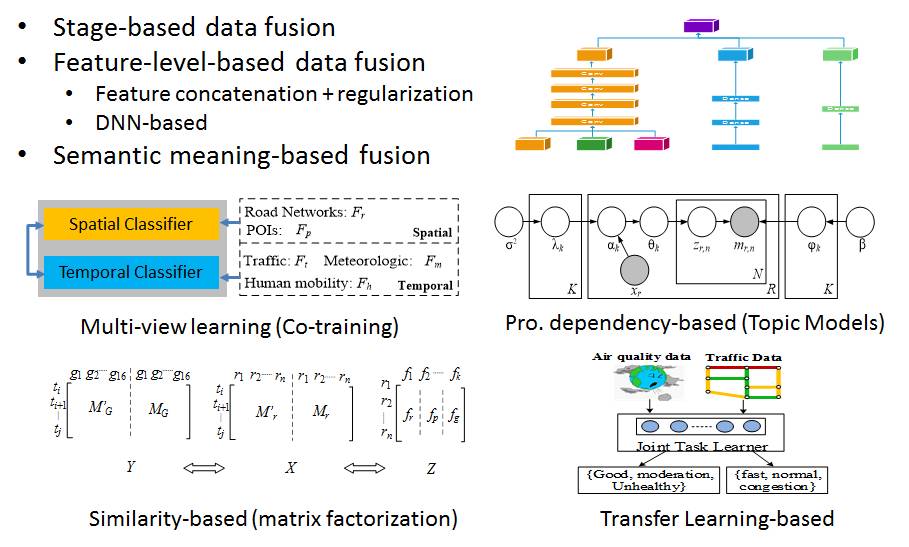
Figure 2 Categories of methods for cross-domain data fusion
This tutorial does not only introduce high-level principles of each
category of methods, but also give examples in which these techniques
are used to handle real big data problems. In addition, this tutorial
positions existing works in a framework, exploring the relationship and
difference between different data fusion methods. This tutorial will
help a wide range of communities find a solution for data fusion in big
data projects.
2. The Stage-Based Data Fusion Methods
This category of methods uses different datasets at the different
stages of a data mining task. So, different datasets are loosely
coupled, without any requirements on the consistency of their
modalities. the stage-based data fusion methods can be a meta-approach
used together with other data fusion methods. For example, Yuan et al.
[3] first use road network data and taxi trajectories to build a region
graph, and then propose a graphical model to fuse the information of
POIs and the knowledge of the region graph. In the second stage, a
probabilistic-graphical-model-based method is employed in the framework
of the stage-based method.
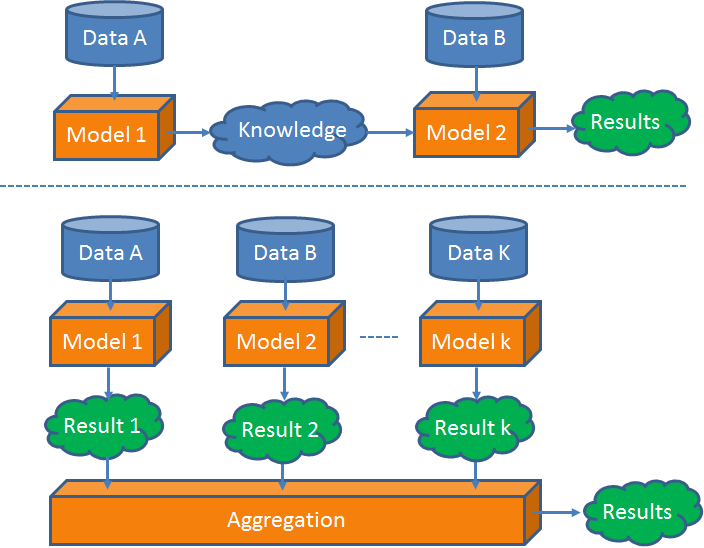
Figure 3. Illustration of the stage-based data fusion
Examples:
As illustrated in Fig. 3 A), Zheng et al. first partition a city into
regions by major roads using a map segmen-tation method. The GPS
trajectories of taxicabs are then mapped onto the regions to formulate a
region graph, as depicted in Fig. 3 B), where a node is a region and an
edge denotes the aggregation of commutes (by taxis in this case)
between two regions. The region graph actually blends knowledge from the
road net-work and taxi trajectories. By analyzing the region graph, a
body of research has been carried out to identi-fy the improper design
of a road network, detect and diagnose traffic anomalies as well as find
urban functional regions.
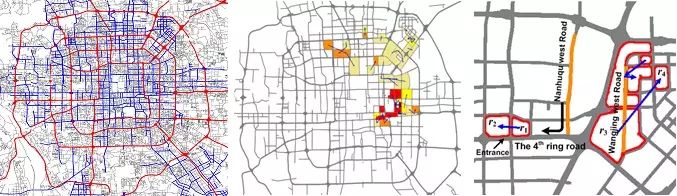
Figure 4. An example of using the stage-based method for data fusion
链接:
https://www.microsoft.com/en-us/research/project/cross-domain-data-fusion/
原文链接:
http://weibo.com/2073091511/EDGDDyWNU?ref=home&rid=7_0_202_2778227504193407143&type=comment