参考资料来源:The Economist
翻译:刘小芹 弗格森
【新智元导读】游戏,更准确地说,模拟场景对于人工智能的研发来说是一个非常理想的场所,对于人工智能技术走向实际应用有着不容忽视的推动作用。目前,DeepMind、微软、Facebook、OpenAI 等都在研究通过游戏场景训练AI。本文结合《经济学人》的文章《AI研究者为什么喜欢游戏》,全面梳理了用游戏训练AI的几大开源平台,对这一方向的领导者DeepMind的路径进行分析。文章提到了“具身认知”的理论,认为智能应该完全从经验进行学习。可以肯定的是,机器“眼中”的游戏和人类所理解的游戏是不一样的,在这种虚拟与现实之间,“智能”会真正发生。

游戏,更准确地说,模拟场景对于人工智能的研发来是一个非常理想的场所。对于人工智能技术走向实际应用有着不容忽视的推动作用。目前,DeepMind、微软、Facebook和阿里巴巴都在研究用 AI 来玩游戏,希望能增强 AI 智能体的通用能力,让AI 更像人。
《经济学人》最近发表了一篇题为《AI研究者为什么喜欢游戏》的报道,通过讲述一个计算机科学家在游戏场景中训练AI,计算机系统可以更好地识别交通信号的故事,分析了视频游戏对于训练人工智能的关键作用。
《经济学人》的文章讲述了一个神经科学家用游戏场景来教计算机理解交通信号的故事:
去年,普林斯顿大学的一名计算机科学家Arthur Filippwicz遇到了一个“交通标志难题”。Filipowicz 正在教汽车如何“看见”和“理解”世界,让汽车拥有一个在不需要人类协助的情况下能自己驾驶的视野。其中需要的一种能力便是识别交通信号。为了达到这一目的,他曾多次尝试,希望能训练一个合适的算法。这样的训练指的是,向这一算法(更准确地说,是向运行这一算法的计算机)展示在不同的情况下大量交通信号的图片:包括新的和旧的、干净的和脏的、部分被建筑物遮挡的、强光照射下的、雨中的、雾中的、白天的、黄昏的和夜里的等等。
要想从图像数据库中拿到所有这些种类的图片并不容易。而要派人去拍下这些所有类型的图像,又太耗费人力了。所以,Filipowicz 博士选择了游戏“Grand Theft Auto V " (侠盗猎车手 V),这是一个最近很火的视频游戏。“侠盗猎车手 V” 因为包含了大量的犯罪和暴力而饱受争议,但是,在Filipowicz 看来,这款游戏很完美,因为它同样描绘了现实世界中的交通信号。通过修补游戏软件,他从游戏中拿到了数千张关于这些信号的照片,关于几乎各个场景,来让他的算法进行消化。
Filipowicz 博士的交通信号标志很好地说明了人工智能研究者对视频游戏的喜爱。其中有几个原因:一些人,例如 Filipowicz 博士,使用视频游戏作为训练场,用来代替真实世界。也有人观察到,不同的游戏要求具备不同的认知技能,他们认为,游戏可以帮助他们理解如何将智能分解为更小的、更加可以管理的细块。还有一些人,基于以上两个观察,认为游戏能帮助他们建立更加正确的人工智能(或者,甚至是自然智能)理论。
Open AI、DeepMind 和微软的开源AI游戏训练平台
显然,对于机器和人来说,“玩”游戏并不是同一回事。在上文提到的所有这些情况下,这些游戏需要先被调整解构,以便它们能被另一个计算机程序直接播放,而不是一般情况的人用屏幕来播放观看。例如,利用一个叫做“Deep Drive”的软件,“侠盗猎车手V”可以由一个有很多道路标志图像的图片源转变为一个自动驾驶汽车的驾驶模拟器。这样,这些车辆的驾驶和导航程序就可以控制了,这比让它们在真实的道路上测试更便宜,也更安全。
游戏公司也开始明白这一点。例如,2015年5月,微软启动了 Malmo 项目,这是基于一个流行游戏“Minecraft”的 AI 开发平台。2016年11月,“星际争霸II”的所有者暴雪公司与 DeepMind 宣布了类似的合作。12月,OpenAI 开源了 Universe 平台,免费供所有人使用,其中包含数百个游戏,可以通过适当的程序直接播放。Universe 提供的游戏从畅销的大型游戏如“传送门2”(一个基于物理的解谜游戏),到低成本的娱乐网游,如“小海马泡泡龙”和“太空斑马”,应有尽有。
1. 微软Malmo

微软的 Malmo 项目的目的之一就是教会 AI 软件与人类合作。为此,该项目的负责人 Katja Hofman 试图利用“我的世界”游戏创建一个智能的私人助理。她的目标是,这个软件能够预测它的人类操作者想要的东西,并帮助他实现。“我的世界”游戏里的世界虽然比现实世界简单,但仍然很复杂,吸引了研究者们的兴趣,可以说是完美的测试地。Hofman 博士和她的同事们使用这个游戏来试图教计算机与人类玩家合作,在游戏里捕捉一只虚拟的猪。由于机器无法理解书面的指示,因此,必须通过观察游戏中人类伙伴的动作来学习如何合作。
2. DeepMind Lab
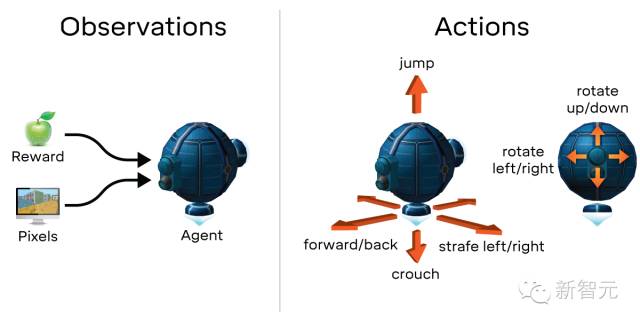
DeepMind的DeepMind Lab 是一个专为基于智能体的 AI 研究设计的,完全像 3D 游戏般的平台。它从自己的视角,通过模拟智能体的眼睛进行观察。场景呈现的视觉效果是科幻风格。可用的操作能让智能体环顾四周,并且以3D的形式移动。智能体的“身体”是一个悬浮的球体,通过激活与期望运动方向相反的推动器实现悬浮和移动,并且具有围绕其主体运动的,能够观察其旋转时动作的摄像头。示例任务包括收集水果、走迷宫、穿越危险的通道且要避免从悬崖上坠落、使用发射台在平台间穿越、玩激光笔、以及快速学习并记住随机生成的环境。下面是智能体在 DeepMind Lab 中如何感知并与世界交互的图示。
3. OpenAI Universe
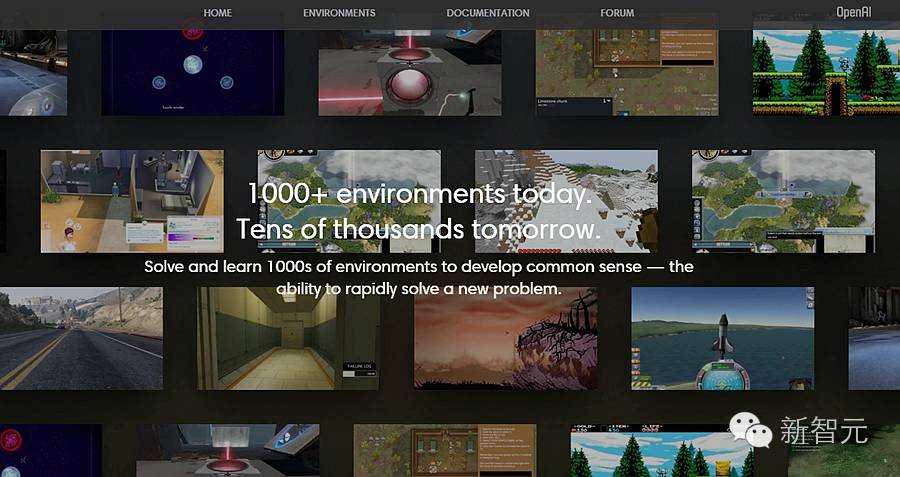
OpenAI Universe, 根据其官方博客的介绍,这是一个能在几乎所有环境中衡量和训练 AI 通用智能水平的开源平台,当下的目标是让 AI 智能体能像人一样使用计算机。目前,Universe 已经有1000种训练环境,由微软、英伟达等公司参与建设。研究人员介绍说,Universe 从李飞飞等人创立的 ImageNet 上获得启发,希望把 ImageNet 在降低图像识别错误率上的成功经验引入到通用人工智能的研究上来,取得实质进展。
DeepMind的启示:对神经网络来说,为数据中心降低能耗的任务与游戏无异
不过,视频游戏对 AI 的作用并非只是作为现实世界的模拟。不同的游戏需要不同的技能这一事实有助于研究人员理解智能问题。2015年 DeepMind 发表了一篇论文,描述研究人员如何训练人工神经网络去玩 Atari 公司在70年代~80年代间发行的数十种不同的游戏。
在这个研究里,有些游戏被证明相比其他游戏更难让神经网络掌握。“Breakout”是个有点像单人网球的游戏,这个对神经网络来说很简单。目标是通过用弹跳球去打击漂浮的积木组。玩家可以选的有两个动作:将“球拍”向左或向右移动。一旦失败,立即会受到惩罚(一旦失球,则输掉游戏)。类似地,如果成功会立即得到奖励(被打掉的每个积木会增加得分)。这种简单动作,而且即时得到反馈的组合适用于 DeepMind 的神经网络,该神经网络玩“Breakout”的成绩是专业人类玩家能达到的最好成绩的十倍以上。
其他游戏就不那么简单了。在“蒙特祖玛的复仇”游戏中,目标是找到埋在充满危险机关的金字塔里的宝藏。要达到目标,玩家必须达成许多个次级的小目标,例如找到打开门的钥匙。这个游戏的反馈也不像“Breakout”那么即时,例如,在一个地方找到的钥匙可能能打开另一个地方的门。最终找到宝藏的奖励是之前的数千次动作的结果。这意味着网络很难将原因和结果联系起来。与“Breakout”游戏的突出表现相反,神经网络在“蒙特祖玛的复仇”游戏中几乎没有任何进展。
后来,DeepMind 的研究人员调优了算法,通过给探索和实验提供更大的奖励,让系统对事物更加好奇。这使得神经网络更常去做那些虽然没有立即得到结果,但后来被证明是好的策略的动作。这种方法不局限于在虚拟世界中掌握技能——也可以应用于真实世界。例如,DeepMind 的算法已被用于 Google 的数据中心,得以将数据中心的能耗降低 40%。实际上,对神经网络来说,为数据中心降低能耗的任务与游戏无差,网络可以根据能耗情况来调整冷却液泵的设置和荷载分布。让能耗“得分”越低,它的表现就越好。
重新利用一个玩游戏的程序去运行数据中心的能源预算,实际上就像重头开始教程序去玩一个新的游戏一样。那是因为 DeepMind 的原始神经网络只能一次玩一个游戏。例如,为了玩“Breakout”,必须要忘掉玩“Space Invaders”时学会的所有知识。这种遗忘是人工神经网络本身的性质,也是人工神经网络与真正的人类大脑相区别的性质。它们通过在全系统调整组成它们的虚拟神经元之间的连接的强度来学习。一旦改变了要学习的任务,旧的网络连接就会逐渐被重写。但是现在,正如 DeepMind 在3月份发表的一篇论文所描述的那样,DeepMind 的程序员已经解决了如何克服“遗忘”的问题,让网络就像真正的人类大脑一样,能一次掌握许多个游戏。这是迁移学习——在一个上下文中使用从另一个上下文学会的行为模式的能力——这是 AI 研究中的一个热门话题。
就像好奇心和延迟奖励一样,将学习从一个任务转移到另一个任务是人类毫不费力就可以做到的,但机器却很难做到。再一次,游戏在这方面的研究起了重要的作用。例如,纽约大学的 Julian Togelius 组织了一个叫做“通用视频游戏AI大赛”的挑战赛,参赛者需要创建一个单一的程序,该程序要能玩10个不同的视频游戏,而且都是它之前没有遇到过的游戏。这需要软件能够掌握多种技能,例如计划,探索,决策等等,并将这些技能应用于以前从未遇过的问题。
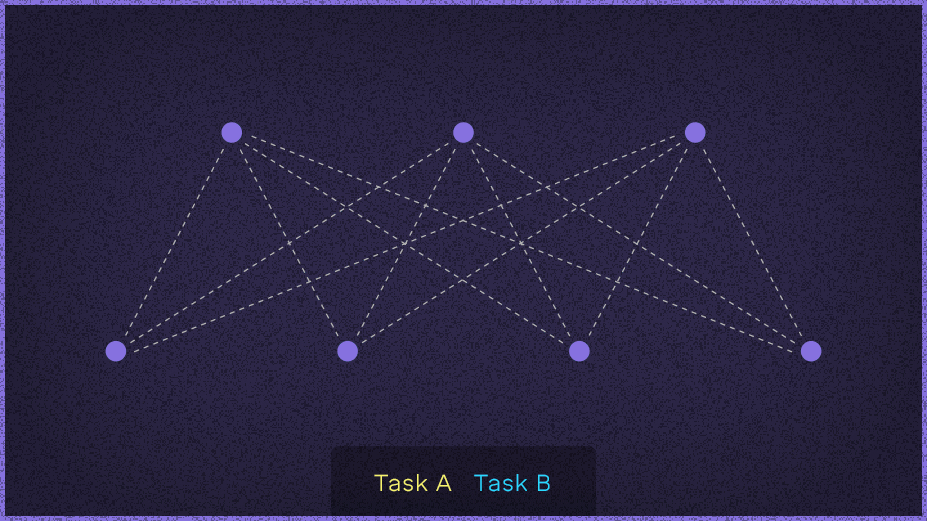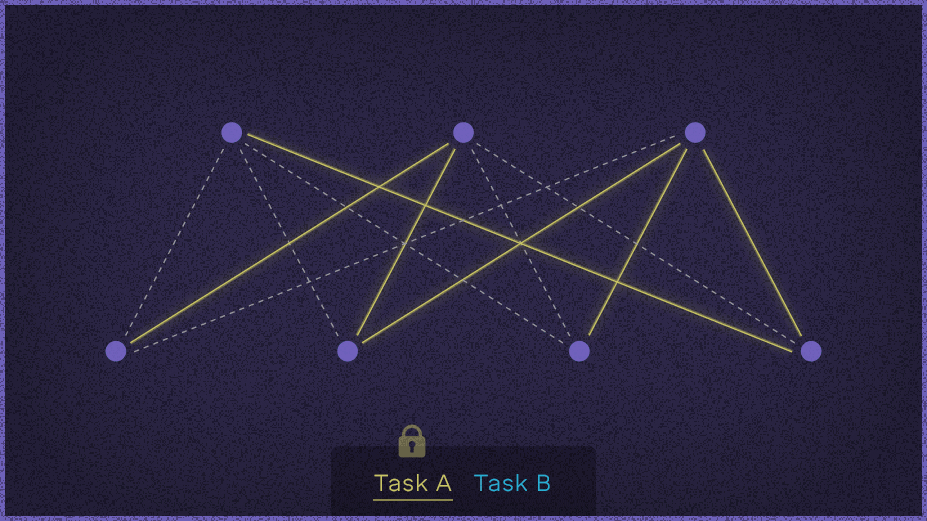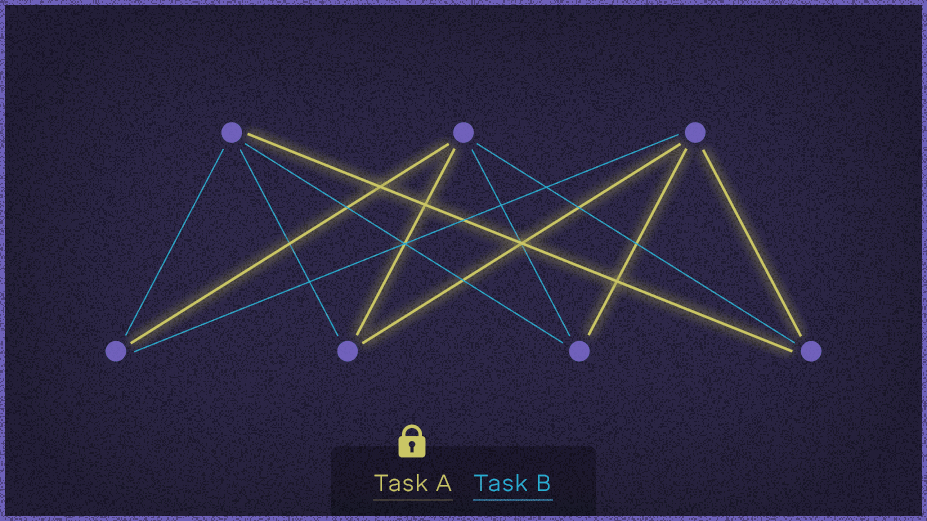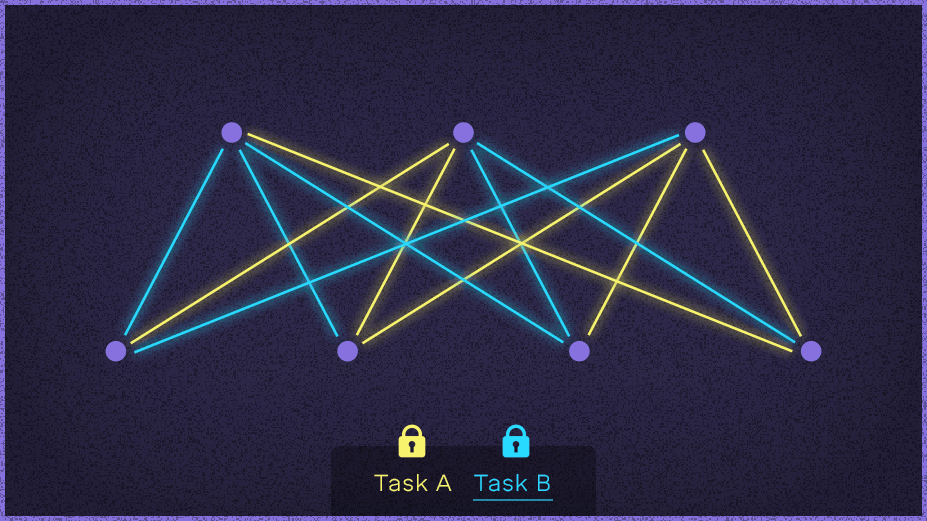
学习两项任务过程的示意图:使用EWC算法的深层神经网络能够学习玩一个游戏,然后转移它学到的玩一个全新的游戏。

论文摘要
以顺序方式学习任务的能力对发展人工智能至关重要。直到现在,神经网络还不具备这种能力,业界也广泛认为灾难性遗忘是连接主义模型的必然特征。我们的工作表明,这个局限是可以克服的,我们能够训练网络,让它们将专业知识保留很长一段时间。我们的方法记住以往任务的方法是,选择性地减慢学习一些权重的速度,这些权重是对完成任务很重要的权重。通过识别手写数字数据集和学习一系列 Atari 2600 游戏,我们证明我们的方法是有效并且可扩展的。
但即便掌握了迁移学习,构建可以用的人工智能仍然是一些零散的活动。研究人员真正希望得到的是如何系统地进行这些活动的一种基本的理论。这种理论的一个候选,被称为具身认知(embodied cognition)的理论认为,智能应该完全从经验中学习,而不是试图将智能从头开始设计到一个程序里。
Hofman 博士尤其支持这种方法。她认为视频游戏是探索这种理论的一个完美平台。20世纪80年代进行的实验“具身认知”的尝试是将传感器装到机器人身上,让他们通过到处跑,到处磕磕碰碰来学习现实世界是如何运作的。当时的研究人员用这种方法取得了一些成果,但在扩大实验规模方面遇到了问题。正如 DeepMind 的研究员 David Silver 所说:“机器人有很多齿轮,轮子和电机,以及各种各样的器件,你最后不得不花很多时间做维修工作。”
视频游戏可以简化这个过程。在虚拟世界里的虚拟机器人是没有重量的,也没有各种部件,因此不需要维护。要改变它的技术参数也不需要拆开它,敲几下键盘就可以了。
它的环境也可以轻松改变。改变一个迷宫的格局不需要再重新焊接一遍金属片或者重新粘一遍塑料墙壁。一台计算机一次就可以运行数千个这样的模拟,让大量虚拟机器人一次又一次地尝试任务,每次尝试都是在学习。这是一种大规模的测试,而且允许学习过程被监视和理解,根本就不使用真实的机器。
DeepMind 的创始人 Demis Hassabis 认为,重要的事情是得确保虚拟机器人不会作弊。它只能使用虚拟的传感器可以收集到的信息进行导航。如果一个机器人要在“蒙特祖玛的复仇”或者“侠盗猎车手”游戏中学习度过重重危险,它必须得自己弄明白自己在游戏环境里的位置,处理当时“看到”的事情,而不能问运行游戏的计算机它在那个坐标。这是 DeepMind 教程序学习玩游戏采用的方式。
以这种方式研究“具身认知”是 AI 玩游戏方法的一个合理的结论。或者说,看起来是合理的。你可以看看任何聪明的生物在年幼时的学习方式,从小狗到人类婴孩,你会看到他们在玩游戏中建立起一些知识,非常像“具身认知”的方式。生物的进化在达到这个过程时并没有计算机的帮助。但是,不管在人工的世界还是自然的世界,这种活动的基本点就是为最大的一个游戏做准备——现实世界。
原文:http://www.economist.com/news/science-and-technology/21721890-games-help-them-understand-reality-why-ai-researchers-video-games










