本文根据姜伟华博士在数果智能新产品发布会“智能时代大数据实时分析技术 DaTalk”上的演讲整理而来。实时大数据分析是指对规模巨大的数据进行分析,利用大数据技术高效的快速完成分析,达到近似实时的效果,更及时的反映数据的价值和意义。
所有人都能理解数据的时效性对于数据的价值至关重要。以唯品会为例,唯品会已经有一整套非常成熟的离线数据仓库系统。这套系统对于业务有非常大的指导意义,但目前碰到的问题是如何将各种计算、报表加速,从原来天级别、小时级别,加速到近实时来。
这是我们开始实时离线融合这个项目的缘由。该工作我们是从 2016 年下半年开始的,到目前为止它仍然只是一个半成品,因此这里面包含的很多内容并不是最终的结论,在多数情况下,它仅仅是以唯品会的特点为基础,而不一定能无缝地适用于其他公司产品。我们希望抛砖引玉,对大家有所俾益。
第一个问题是:什么是实时(real-time)? 什么是离线(offline)?很多时候,我们会当然的把实时等同于流处理(stream processing),等同于 Storm、Spark Streaming。但其实所谓实时和离线的区别其实是从时延(latency)的角度出发,如果时延短的就是实时,时延长的就是离线。
而时延就是从数据产生到计算出结果的时间差,时延是从端到端的,不仅仅是 Query 的执行时间。采用简单的式子表示即为:时延 = 数据准备时间 + 查询计算时间。
实时、近实时 (near realtime)、离线一般是以时延的时间长短为区分标准。实时表示毫秒、秒级时延;近实时主要是分钟级时延;而离线是时延超过十分钟。

而何为批处理、流处理?批处理,也常被称为“离线”,即数据以一个完整的数据集被处理可以重复计算,数据在落盘之后定时或者按需启动计算。一般情况下,批处理一次处理的数据量大,延迟较大,经常需要全量计算。流处理,也常被称为“实时”,即数据以流式的方式(增量)被处理,它与批处理的特点完成相反。

然而实时计算并不等同于流式计算,即使大多数实时计算是流式计算,但很多也可以采用批处理来实现。同时,虽然在流式计算中实时或者准实时计算结果占了较大比例,流式计算也完全可能需要较长时间才能出结果,比如说 30 分钟的 window,window 结束才输出结果等。
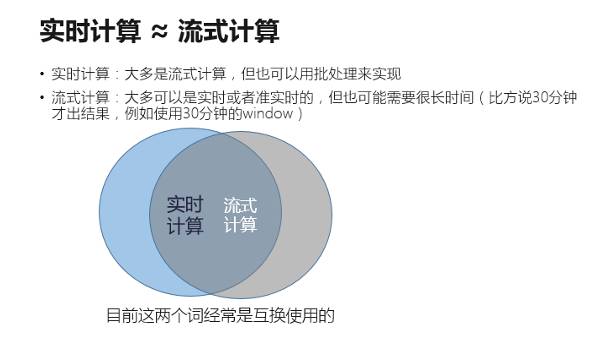
所以说,实时计算并不等同于流式计算。业务的实时化并不一定要借助于流式计算来实现。下面我们来看看目前数据处理中之所以实时化要流式计算的瓶颈在何处。
唯品会是电子商务网站,数据可以分成两大类: 行为埋点数据和交易类数据。下图是交易类数据的一条典型处理链路,行为类数据的处理与之非常类似。
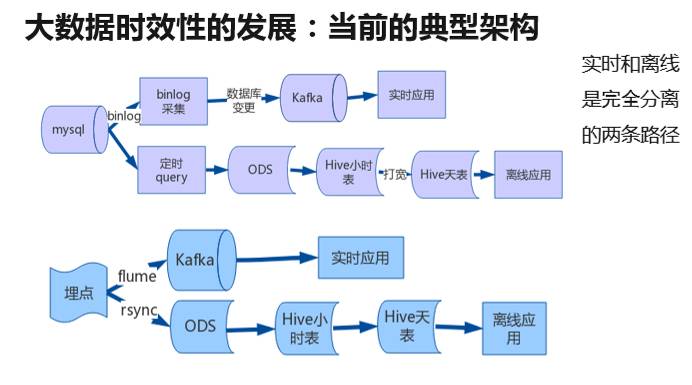
这张图其实代表了当前大数据处理的一种典型架构。对于实时和离线而言,这两条路径是从源头开始就完全分离的。
对于离线 / 批处理而言,数据层层加工。用户可以简易地使用 SQL,使用门槛低,并且其工具、理论、系统完备。然而它的延迟性高,并且不可控制(特别是在大促时)。
对于流式 / 实时计算而言,一切以时效性为目标,链路短,数据无层次,大量的应用直接处理 raw data。所以它的唯一优处在于它的时效性。但是它的开发难度高,逻辑复杂,资源需求很大,并且很难保证其数据质量。同时,需要为每个应用单独去开发其应用逻辑,无法通用化。
对于实时应用(特别是报表)来说,对数是最痛苦的一件事情。典型场景是利用实时报表提供结果,但仍需要定时和离线报表去比对其正确性。一般普遍认为离线应用的精度要高于实时应用,但实时和离线的处理方法是完全不同的,其开发方式、方法,处理逻辑、数据来源都不一致,导致对数非常困难。而这其中最根本的是因为实时和离线从最本源开始就是两条计算路径。要在这完全不同的两条路径上对数,难度就非常非常大了。
我们也一直在反思怎么样才能更好的支持业务的实时化。因为业务方总是会在抱怨数据不准,和离线对不上,口径没更新,开发效率低下,周期时间长等状况,明明我们也在努力加班,努力满足业务方要求,却发现总是不能满足业务的需求。
目前的实时化方法真的是正确的打开方式吗? 对于这个问题,我们的理解是:
业务需要的是近实时。绝大部分业务只需要时延在分钟、甚至 5~10 分钟级别就可以了。并不需要秒级的时延。所以用 Storm/Spark Streaming 这样的流式计算去实现,其实是一种杀鸡用牛刀的行为。
业务方需要近实时,但目前只有实时团队才有能力实时化。这个的原因是流式计算的开发门槛太高。但其实业务方是希望以他们容易掌控的方式实现近实时,而不是交给实时团队去排期开发。
基于上面的理解,我们开展了实时离线融合这个项目。这个项目的目的就是:
让业务方以他们熟悉的批处理方法来实现近实时的计算。
让实时团队专注于系统和平台,而不是业务。
时延 = 数据准备时间 + 查询时间。目前之所以无法用批处理方法实现近实时的计算就是因为这两个步骤各自花的时间太长了。如果数据准备速度足够快,并且计算速度也足够敏捷,那么批处理也可以达到近实时的时延。
对于批处理而言,数据准备时间 = 定时调度时间 + 数据准备计算时间。只有在两者都很小的情况下,数据准备时间才能大幅度地缩短。所以对于数据准备来说,使用流式处理来实现数据的实时准备是非常合理的想法。同时,因为这种数据准备的一般是基础数据,和业务逻辑关系不大,所以也是很适合用流式的方法来实现的。
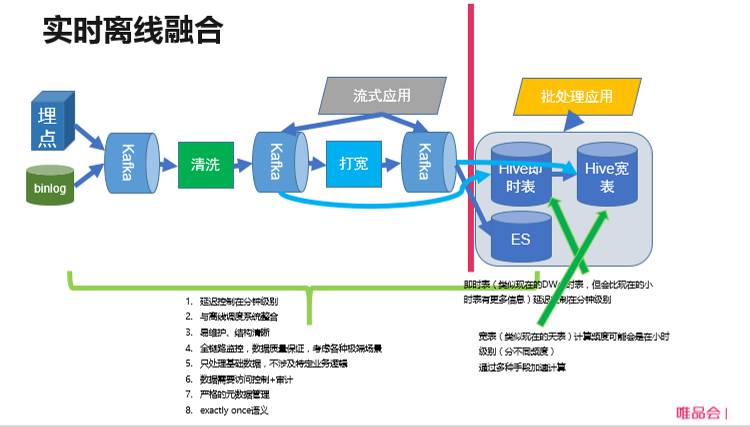
实时离线融合链路图
在这个链路中,流式计算、批处理共享相同的数据准备步骤(清洗、打宽)。这些步骤保证数据是在毫秒级别就能处理完成的。处理完成的数据会落地到 Hive 中去(时延控制在分钟级别)。这样,Hive 中就有了近实时的已经准备好的基础数据。需要近实时的应用就可以去访问这些数据了。
实时数据落地 Hive, 即将大批量数据实时处理之后存入 Hive 中,提供给后端业务系统进行处理。目前我们的做法是每 5 分钟一个 Hive 分区,数据按照 event time 落到相应的 Hive 分区,等待一定时间后关闭这个分区(这里我们借鉴了流处理中的 watermark 概念)。同时为了与现有的 Hive 分区保持兼容(即对于一个已关闭分区的两次查询应该得到相同的结果),也为了保证分区能及时关闭,规定若其数据在分区关闭后才到达,那么该数据将会落地到下一个分区。
对于那些不关心分区是否已关闭,而时效性要求高的应用,其可以在分钟级访问到数据(未关闭的分区);而对于大部分应用而言,可以选择分区关闭后再查询(数据准备的时延就在 5~6 分钟左右)。
这种数据高频落地也是存在着一些问题的。
第一,小文件过多(为了保证落地时延,必须增加并发),会导致查询变慢。
第二,以普通磁盘为主的 HDFS(Hadoop 分布式文件系统)时延不稳定(每个分区的数据快的几秒就完成,慢的需要几分钟)。这就对数据落地的 Spark Streaming 任务带来了挑战。
为了改善这些情况,我们对历史分区 compact 以减少其文件数; 将普通磁盘为主的 HDFS 替换为 Alluxio 和以 SSD 为主的 HDFS 以减少其落地波动。数据放在高速文件系统中,不仅对落地波动情况有所改善,也可提高读取速率。
对于和离线系统的无缝对接,我们目前的做法是在每个分区关闭后,向离线调度系统发信号说这个分区数据准备完成了,这样离线调度系统就可以正常调度依赖这个分区的下游任务了。

当数据准备实时化了后,如何缩短离线查询时间呢?查询时间 = 定时调度时间 + 查询计算时间。要达到近实时,必须减少其调度时间与查询计算时间来提高离线应用。那么我们需要将高频调度定时为五分钟甚至小于五分钟,并且合理地控制资源使用量,在查询计算时,保证其中间结果不落地,使用 Spark SQL、Presto 替代 Hive,并且使用 ElasticSearch、Druid、Kylin 等做预计算,从而减少计算量,加速查询计算。
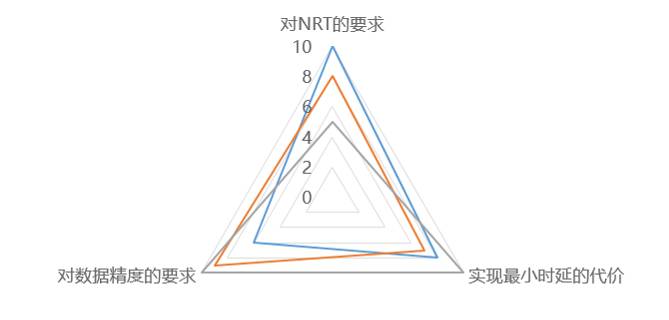
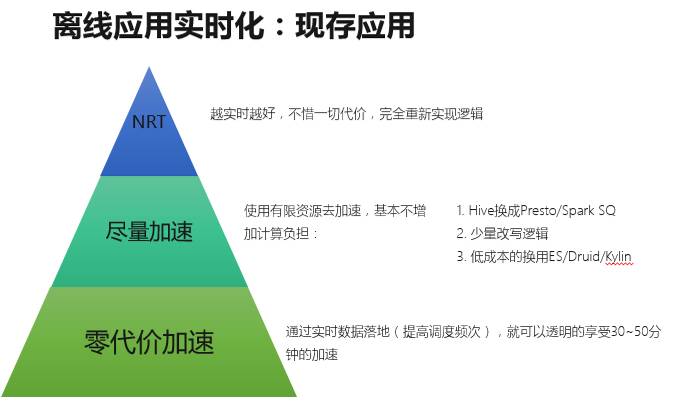
如上图所示。离线应用的三个维度,分别是对 NRT 的要求(业务自身的属性),实现最小时延的代价(人力资源、机器资源),对数据精度的要求。每个应用在实时化都要考虑如何在 3 者之间取得一个平衡。
这种平衡就决定了存在着三种模式。
第一种是零代价加速,通过实时数据落地,可以透明地享受 30-50 分钟的加速;
第二种追求极致的近实时,应用越实时越好,不惜一切代价,投入大量人力物力完全地重新实现逻辑;
第三种介于两者之间,追求在资源有限情况下去加速,但尽量不增加其计算负担。
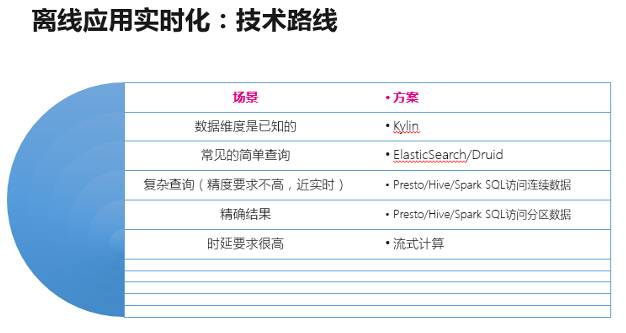
在实时离线融合的场景下,ES、Druid、Kylin 等的作用会越来越重要。因为如果应用能够使用这些带预计算的存储来实现的话,那么查询计算时间就可以基本忽略不计。同时,因为这些存储并没有 Hive 那样的分区概念,所以清洗打宽完的数据其实是可以流式的落到这些存储中去的(秒级)。那么,用户就可以以类似离线 SQL 的方式实现秒级的数据查询。
实时离线融合并不是免费的午餐。它也带来了一系列新的问题和挑战。
对于实时 / 流式计算而言,它变成了所有大数据处理的一个前置。这就要求其作为平台具有很高的稳定性、可靠性、可管理性、数据质量、SLA 保证。特别是现有的在流处理系统(Storm、Spark Streaming、Flink)在理论上还没有完全实现 end-to-end exactly once 的情况下。一般认为批处理系统(Hive、Spark)是非常可靠的,且支持 exactly once 语义。将基础数据准备从批处理系统替换为流处理系统,怎么保证其可靠性不降低是一个非常大的挑战。
如何确保 Hive 中数据的质量,目前我们的做法是多方着手:
1. 全链路监控,保证数据质量;
2. 考虑各种极端场景的处理方法;
3. 发现问题时,如何重写整个 Hive 分区;
4. 保留目前的离线小时抽数逻辑用于对数。
5. 改造目前的流框架来提供更好的处理语义保证。
对于离线(Hive、Spark)来说,应用要实时化,就必须高频调度。这也带来了一系列挑战。如何提高调度效率?如何处理在上一次调度没执行完情况下下一个批次的调度问题(数据积压)?如何防止过度占用系统资源?这需要对于调度系统和应用都进行改造。另外,我们需要区分热数据和冷数据。热数据使用单独的 SSD 或者 Alluxio 集群,而冷数据存储在普通的 HDFS 中。
实时离线融合我们目前也只是完成了很多基础数据的实时化,目前已经能够比较明显的看到效果。但这个任务是长期的。因为用户一般更加喜欢使用天表等很宽的表,而目前实时化的更多是小时表等基础表,如何实时化(或者加速)天表等宽表是我们目前在推进的一项工作。只有等这部分工作完成后,我们才能说实时离线融合真正成功了。
作者介绍
姜伟华 博士,国内最早的 Hadoop 发行版:IDH 的产品开发经理。主要研究方向集中于对大数据开发,从事大数据开源工作,曾经在 Intel 期间 2 年之内团队培养出 10 位 committer,创建了上海大数据流处理 Meetup,创建 2 个新的 Apache 项目。目前在唯品会负责实时平台。










