我们借助于Docker在Iguazio构建的是原生云平台。使用到微服务、etcd、home-grown等Docker集群管理工具。 目前我们正在逐渐迁移到使用Kubernetes作为容器的编排引擎,因为这些已经变得越来越成熟,我们就可以利用其更先进的功能专注于提供独特的服务。
与其他很多原生云应用不同,我们更专注实时性。为了提高应用的性能,我们使用底层直接访问网络、存储、CPU和内存资源。对于容器和Kubernetes来说,这一点非常重要,而且需要使用一些独特并不常见的黑科技手段突破。
这篇文章是这个系列的第一弹,我主要分享下如何使用一些黑客的技巧学习Kubernetes和容器网络接口的内部构件,以及如何操作它们。后续的博文将会覆盖高性能存储、进程间通信(IPC)在容器中的使用技巧等。
容器使用的是Linux 中叫做Cgroups和Namespace的分区的功能来实现的。容器进程映射到网络、存储和其他的命名空间。每一个命名空间只能看到操作系统授权的那一部分,通过这种方式做到容器之间的隔离。
在网络方面,每一个命名空间都有自己的网络堆栈,包括网络接口、路由表、Socket 和 IPTABLE规则等。一个接口只能属于某一个网络的命名空间。使用多容器就意味者需要多接口。另外一个选择是生成伪接口,并将它们软连接到真实的接口(我们还可以将容器映射到主机网络的命名空间,如守护进程的使用)。
下面是创建并连接伪接口的几种选择:
-
虚拟桥:在容器的一侧创建虚拟接口对儿,另一方面再根命名空间中创建虚拟接口对儿,并使用Linux桥接器或者OpenvSwith(OVS)来实现容器和外部接口的连接。与直接方法相比,桥的引入会有一定的额外开销。
-
多路复用:多路复用可以包括一个暴露多个虚拟接口的中间网络设备,具有分组转发规则来控制每个数据包的接口。MACVLAN为每个虚拟的接口分配MAC(输出数据包应该用MAC标记,传入数据包根据目标MAC进行复用)。IPVLAN也一样,基于IP地址,使用单个MAC可以对虚拟机更友好。
-
硬件交换:当前大多数NIC都已经支持单节点 I/O虚拟化(SR-IOV),这也是创建虚拟设备的一种方式。每个虚拟的设备都将自己显示为单独的PCI设备。它可以拥有自己的VLAN和硬件强制的QoS关联。SR-IOV提供裸机性能,但通常再公共云中不可用。
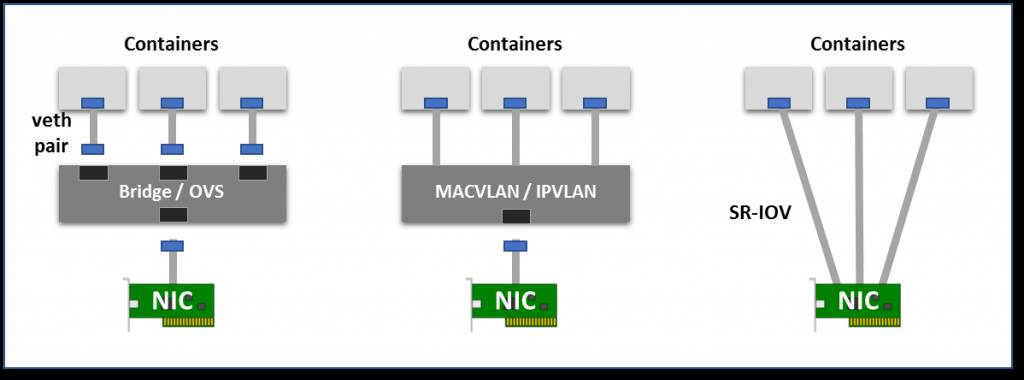
虚拟网络模式:虚拟桥、多路复用和 SR-IOV。
在很多场景下,用户希望可以创建跨越多个L2/3网段的逻辑网络子网。这需要覆盖封装协议(最常见的VXLAN,它将网路进一步包装成UDP的数据包)。VXLAN可能会引入更多的网络开销,而且由于控制中缺乏标准化,来自不同供应商的多个VXLAN网络通常不能互相操作。
Kubernetes还广泛使用IPTABLES和NAT来拦截流量,并将其路由到相应的物理目标。像Flannel,Calico和Weave使用Veth与桥接/路由器和覆盖或者路由/NAT的操作作为容器网络的解决方案。
有关各种Linux网络选项,请参与这个很好的实践教程和使用指南(http://suo.im/JGwKn)。
除了预期的数据包操作额外开销外,虚拟网络增加了隐藏的成本,可能会对CPU和内存并行行造成负面的影响,例如:
一些应用程序(如Iguazio的)使用了先进的NIC功能,如RDMA,DPDK快速网络处理库或加密来卸载消息传递,对CPU的并行性进行更严格的控制,减少中断或消除内存副本。这只能在使用直接网络接口或SR-IOV虚拟接口时使用。
没有简单的方法可以看到网络的命名空间,因为Kubernetes和Docker并没有注册它们(“ip netns”将不会与Kubernetes和Docker一起使用)。但是我们还是可以用一些黑科技从主机上查看、调试、管理和配置POD网络。
网络命名空间在/proc/
/ns/net 可以查看,所以我们需要从我们的POD中找到进程ID(PID)。首先,通过以下命令可以找到容器ID,注意只取前12个数字。
kubectl get po -o jsonpath='{.status.containerStatuses[0].containerID}' | cut -c 10-21
再次,我们使用Docker命令找到进程PID:
kubectl get po -o jsonpath='{.status.containerStatuses[0].containerID}' | cut -c 10-21
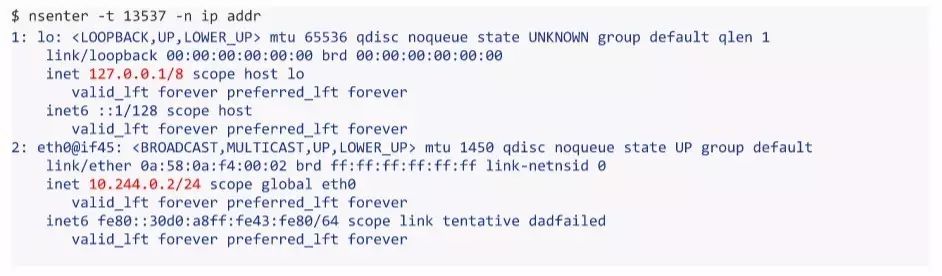
一旦获取PID,我们可以通过POD来监控和配置网络。在POD的命名空间中,使用nsenter工具来运行任意的命令,例如:
nsenter -t ${PID} -n ip addr
这样就可以显示所有的POD接口以及它们的IP地址。我们也可以使用其他的命令,例如ping或者crul来检验网络的连接性,可以使用特殊权限的操作或者在POD容器中安装容器的监控、调试或者配置该POD等(例如:ip route,nslookup)。
如果我们对每个POD的单个接口不满意,还可以从主机命名空间中获取或创建接口,并将它们分配给POD:
如果想还原,我们设置host即可:
nsenter -t ${PID} -n ip link set netns 1
Kubernetes使用CN1插件来组织网络。每次初始化或者删除一个POD时,将使用默认配置调用默认的CN1插件。该CN1插件创建一个伪接口,将其附加到相关的底层网络,设置IP和路由将其映射到POD命名空间。
不幸的是Kubernetes仍然只支持每个POD只有一个CN1接口,具有一个群集级层次的配置。这就非常有限了,因为我们可能想要配置每个POD的多个网络接口,潜在地使用具有不同策略(子网,安全性,Qos)的不同覆盖解决方案。
让我们看下我们是怎么绕过这个限制的。
当Kubelet Kubernetes本地代理配置POD网络时,它会在/etc/cni/net.d/目录路径中查找一个CNI json配置文件,并在/opt/cni/bin/中找到一个相关的插件二进制文件(基于type属性) 。 CNI插件可以调用辅助IP地址管理(IPAM)插件来设置每个接口的IP地址(例如主机本地或DHCP)。 也可以通过Kubelet命令选项使用其他路径:

Kubelet使用包含命令参数(CNI_ARGS,CNI_COMMAND,CNI_IFNAME,CNI_NETNS,CNI_CONTAINERID,CNI_PATH)的环境变量调用CNI插件,并通过stdin读写传输json.conf文件。 插件用json输出文本进行响应,描述结果和状态。 在这里查看更详细的解释和例子(http://suo.im/4Gaml7)。 如果您知道Go编程语言,开发自己的CNI插件是比较简单的,因为该框架可以做很多的魔法,您可以使用或扩展其中一个现有的插件(http://suo.im/3K9RYG)。
Kubelet将作为CNI_ARGS变量的一部分传递POD名称和命名空间(例如“K8S_POD_NAMESPACE = default; K8S_POD_NAME = mytests-1227152546-vq7kw;”)。 我们可以使用它来定制每个POD或POD命名空间的网络配置(例如,将每个命名空间放在不同的子网中)。 未来的Kubernetes版本会将网络视为平等的公民,并将网络配置作为POD或命名空间规范的一部分,就像内存,CPU和存储卷一样。 目前,我们可以使用注释来存储配置或记录POD网络数据/状态。
CNI插件一旦被调用就自动执行逻辑。 它还可以将多个网络接口连接到同一个POD,并绕过当前的限制,这里有一个警告:Kubernetes只会关注我们在报告中的结果(用于服务发现和路由)。 我最近偶然发现了一个很牛的英特尔开源CNI插件,称为Multus,它的功能正如以上所说的那样。 Linux程序员Doug Smith在最近的Slack聊天之后写了一个详细的Multus的从入门到提高(http://suo.im/4cs4u0)。





