自2014年Ian Goodfellow提出
生成对抗网络(GAN)
的概念后,生成对抗网络变成为了学术界的一个火热的研究热点,Yann LeCun更是称之为”过去十年间机器学习领域最让人激动的点子”。生成对抗网络的简单介绍如下,训练一个生成器(Generator,简称G),从随机噪声或者潜在变量(Latent Variable)中生成逼真的的样本,同时训练一个鉴别器(Discriminator,简称D)来鉴别真实数据和生成数据,两者同时训练,直到达到一个纳什均衡,生成器生成的数据与真实样本无差别,鉴别器也无法正确的区分生成数据和真实数据。GAN的结构如图1所示。
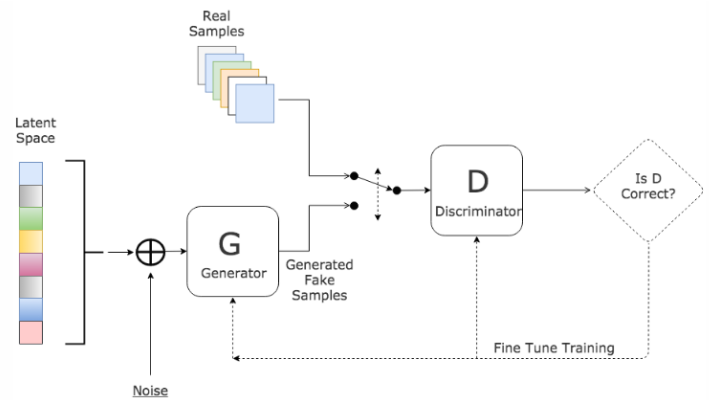
图1 生成对抗网络的基本架构
近两年来学术界相继提出了条件生成对抗网络(CGAN),信息生成对抗网络(InfoGAN)以及深度卷积生成对抗网络(DCGAN)等众多GAN的变种,图2来自去年一篇论文:
Image-to-Image Translation with Conditional Adversarial Nets
,我们可以看到GAN已经被引入到了各种以往深度神经网络的任务中,例如从分割图像恢复原图像(左上角第一对),给黑白图片上色(右上角第一对),根据纹理图上色(右下角第一对),另外,GAN还可以做图像超分辨率,动态场景生成等,关于GAN的更多应用请见另一篇博客
深度学习在计算机视觉领域的前沿进展
。

图2 Image to image图像翻译
仔细想来,这些任务,其实都是传统的深度神经网络可以做的,例如自编码器(AutoEncodor)和卷积反卷积架构可以做到的,我们不禁要想,GAN相比传统的深度神经网络,它的优势在哪里?前段时间,我也一直比较迷惑,中文能查到的资料,就是Ian Goodfellow在
生成对抗网络(GAN)
论文最后总结的几点,如下:
优点
缺点
-
可解释性差,生成模型的分布 Pg(G)没有显式的表达。
-
比较难训练,D与G之间需要很好的同步,例如D更新k次而G更新一次。
上面只是一个比较简单的解释,很幸运,我在Quora上查到了两个类似问题,
GAN与其他生成模型相比有什么优势
,这个问题只有一个人回答,很幸运的是,他就是Ian Goodfellow,GAN的发明人,他在Quora上的签名就是“I invented generative adversarial networks”。而另一个问题是
GANs的优缺点是什么?
良心大神Goodfellow也做了回答。我把他的两个回答翻译如下:
原问题1:What is the advantage of generative adversarial networks compared with other generative models?
生成对抗网络相比其他生成模型的优点?
相比其他所有模型,我认为:
-
从实际结果来看,GAN看起来能产生更好的生成样本。
-
GAN框架可以训练任何生成网络(在理论实践中,很难使用增强学习去训练有离散输出的生成器),大多数其他架构需要生成器有一些特定的函数形式,就像输出层必须是高斯化的。另外所有其他框架需要生成器整个都是非零权值(put non-zero mass everywhere),然而,GANs可以学习到一个只在靠近真实数据的地方(神经网络层)产生样本点的模型(GANs can learn models that generate points only on a thin manifold that goes near the data)。
-
没有必要遵循任何种类的因子分解去设计模型,所有的生成器和鉴别器都可以正常工作。
-
相比PixelRNN,GAN生成采样的运行时间更短,GANs一次产生一个样本,然而PixelRNNs需要一个像素一个像素的去产生样本。
-
相比VAE,GANs没有变分下界,如果鉴别器训练良好,那么生成器可以完美的学习到训练样本的分布。换句话说,GANs是渐进一致的,但是VAE是有偏差的。
相比深度玻尔兹曼机,GANs没有变分下界,也没有棘手的配分函数,样本是一次生成的,而不是重复的应用马尔科夫链来生成的。
-
相比GSNs,GANs产生的样本是一次生成的,而不是重复的应用马尔科夫链来生成的。
-
相比NICE和Real NVE,GANs没有对潜在变量(生成器的输入值)的大小进行限制;说实话,我认为其他的方法也都是很了不起的,他们相比GANs也有相应的优势。
原问题2:What are the pros and cons of using generative adversarial networks (a type of neural network)?
生成对抗网络(一种神经网络)的优缺点是什么?
It is known that facebook has developed a means of generating realistic-looking images via a neural network. They used “GAN” aka “generative adversarial networks”. Could this be applied generation of other things, such as audio waveform via RNN? Why or why not?
facebook基于神经网络开发了一种可以生成现实图片的方法,他们使用GAN,又叫做生成对抗网络,它能应用到其他事物的生成吗,例如通过RNN生成音频波形,可以吗?为什么?
优势
-
GANs是一种以半监督方式训练分类器的方法,可以参考我们的
NIPS paper
和相应代码。在你没有很多带标签的训练集的时候,你可以不做任何修改的直接使用我们的代码,通常这是因为你没有太多标记样本。我最近也成功地使用这份代码与谷歌大脑部门在
深度学习的隐私方面
合写了
一篇论文
。
-
GANs可以比完全明显的信念网络(NADE,PixelRNN,WaveNet等)更快的产生样本,因为它不需要在采样序列生成不同的数据。
-
GANs不需要蒙特卡洛估计来训练网络,人们经常抱怨GANs训练不稳定,很难训练,但是他们比训练依赖于蒙特卡洛估计和对数配分函数的玻尔兹曼机简单多了。因为蒙特卡洛方法在高维空间中效果不好,玻尔兹曼机从来没有拓展到像ImgeNet任务中。GANs起码在ImageNet上训练后可以学习去画一些以假乱真的狗。









