1
、为什么要起这个话题?
运维性要在架构设计时就要统筹考虑,从一开始就得考虑进去,而不是到了运维这个环节再去考虑,否则就会出现很多的问题。
但实际情况,很多技术团队在这一点上做得并不够,而是将全部的精力放到如何进行服务化或微服务的拆分上,放到分布式架构如分布式服务、分布式消息、分布式DB和缓存等设计上,这些更多的是做了一些纵向的架构分解和技术钻研工作,但是架构的横向延伸和拉通考虑得明显不足。
这样恰恰是忽略了整个软件生命周期中最长尾的运维环节,也反映出了很多公司对于运维这件事情的重视程度和理解深度不够。
2
、出现的问题
从我个人经历的过程以及观察的情况看,通常有这样几个现象:
(1)应用这个概念,在资源申请、域名申请、VIP申请、服务注册、发布部署、策略下发、监控等这些环节不统一,各自独立一套;这个就是最典型的架构设计时,只考虑开发一个环节,没有将架构上拆分后的概念延伸贯穿到整个软件生命周期的问题。这个也将导致下面一系列的问题产生;
(2)上面做不到,没有统一的标准和概念,各个平台之间就很难集成和打通,所谓的持续集成、持续发布、持续部署、持续交付等这些环节仍然靠大量的人肉动作去做,还谈不上持续,效率自然上不去;
(3)稳定性保障无从下手,大量的服务化应用,错综复杂的调用依赖,海量链路日志,问题排查困难,一个请求下来,到底跑到哪个应用去了都不知道;故障持续时间长,出现流量激增或基础部件故障,无法快速隔离、降级和恢复;
(4)效率跟不上,还经常出问题,进而团队协作效率降低,相互信任下降,就开始经常听到下面的言论:
开发抱怨:“运维做得不到位,申请个机器老半天,发布效率也提不上去,代码都写好了,上线咋这么费劲,严重降低了我们的工作效率,再有,出了问题还得我们上去定位,运维什么都帮不上……”
运维抱怨:“开发的架构这么烂,配置五花八门,还得手工维护,我咋知道这些配置干嘛的,配错一个就出故障,让我怎么自动化发布;日志放哪儿也不知道,一会这里,一会那里,出问题你说我咋定位……”
(5)好了,出了问题,就开始撕逼扯皮、相互推诿了,背了责任的一方又开始甩出背锅言论,感觉没有被公平对待。团队的氛围也开始出现bad smell。
3
、问题出在哪儿了呢?
其实从开发和运维
单独
的角度来看,双方的表达都没有问题,做的事情也都没有问题。但是双方都是只站在了自己的角度表达问题和情绪,恰恰都忽略了很重要的一点:运维和开发不是相互割裂的两个组织,运维的技术体系和全站整体的技术体系更是不可分割的,越是把它们割裂开看,越是站在各自的角度看问题,上面说的这些情况就越是无解,整个团队也会限于这种没完没了的、毫无意义的纠缠中,从长期看对团队和个人的发展都是很不利的。
所以,根本原因在于将开发和运维在技术和管理两个层面给割裂开了,详细描述如下:
-
运维阶段要面临的问题没想清楚,从一开始架构设计上就没有考虑清后续的运维阶段要面临的问题和事情,比如这么多应用,资源应该如何分配、发布的效率如何保障等,而都是在考虑开发自身的需求和问题。不考虑运维面临的问题,这样实际就是把运维割裂在整个架构设计之外了。(这个责任在谁呢?)
-
运维团队的职责定位不清晰,整个技术架构朝着服务化的方向演进后,整个组织架构对于运维团队的定义也是模糊的,也就是运维到底要做什么,要承担什么样的职责,因为一个合理的架构落地,必然要有合理的组织架构去对应支撑才可以。运维定位不清晰,就相当于将运维团队给割裂在研发团队之外了。
第一部分提到一个问题,运维架构和技术架构的脱节这个问题到底出在哪了?到底谁应该承担这个责任?
一开始,我个人第一反应,承担这个责任的或许应该是架构师这样的角色吧,毕竟这不是个单纯的技术问题。
但仔细考虑过后,我觉得这样也会有问题。
因为从服务化之后,整个架构就已经是去中心化的了,我们可以看一下自己的周边,现在架构师的角色已经更多的往垂直领域发展了,如业务架构师(交易、支付、商品、营销、类目等),或者某个技术领域的专家,如分布式服务、消息、缓存和DB,更大的方向上如大数据、搜索等方面。我想这也是去中心化之后的必然结果,大家都是朝着某个更加聚焦、更加专业的方向发展。因为每个专业方向的特点又不相同,这时就很难再出现能把全站的架构讲清楚的人了。
所以,我们如果只是想当然的认为应该是xxx角色要承担责任,这样难免会片面。
1
、怎么解决呢?
现实情况下,既然靠单个人或角色解决不了的问题,那就靠团队,靠良好的组织协作、靠共同遵守的架构契约来完成。这里我是从运维的角度来考虑架构契约,可能更多的还有前后端架构契约、接口设计契约等,这个更偏向开发内部自行遵守,就不班门弄斧了。
2
、架构契约中的运维部分—架构标准化
上面提到的团队和团队协作,这不多说了,组织定期的例会讨论,多参加彼此技术方案会议,随时随地的交流,这个只要保持开放的心态和合作模式都是可以做到的。
还是想再说一下,千万不要出现,开发说这个应该是运维考虑的事情,跟我们无关,运维说这个应该是开发的事情,开发想不清楚让我们怎么办?如果都是这种心态就完蛋了,建议双方都往前走一步,大家要有共赢的心态才可以。
但是沟通讨论及会议只是形式,最关键和重要的是各方要能制定出共同遵守的架构契约来。简单来说,就是要遵循统一的标准,并使其横向延伸到运维阶段的平台中去,一脉相承,比如发布系统、监控、稳定性等平台系统,从而使得运维的体系能够更好地支持业务架构体系。而不是我们之前所说的,每个运维的平台都是一个个孤岛,无法形成体系。
重点谈谈关于架构标准化,之前提到的标准,更多的还是偏运维层面的标准,比如硬件资源标准、应用标准、部署标准等。但是架构标准就很少有提到了,直观看上去这一点跟运维并没有很大的关系。
但事实正好相反,我们可以一起分析下。按照我们自己的经验,在做业务服务化的早期,我们也没有意识去关注架构标准,结果就会出现以下几个场景:
(1)分布式服务化框架
,虽然绝大部分团队用Java,但因为有的团队对PHP特别熟悉,所以就用PHP去做服务化,后面遇到的问题就是Java的服务化接口和PHP的服务化接口该怎么相互调用,所以到了后来我们的服务化框架还要提供PHP-Proxy来适配PHP的服务化接口;
(2)分布式DB中间件
,有的团队觉得我们自研的分布式DB框架不好用,对分库分表的支持不够友好,就去自研一套出来,或者去引入其它的开源的框架进来。平时使用没问题,但是到了后期要做一些统一的策略就很难搞,比如DB访问策略、账号密码管控、路由策略优化、慢SQL统计和优化等;
(3)分布式的缓存
,有的直接使用Redis,Redis可能还会有主备或者Cluster,有的搞个开源的Codis方案等;
(4)接入层上,
有的期望用Nginx直接做7层负载,版本上有期望用TEngine,有的期望用Openresty,还有的期望用LVS有个VIP就够了;
(5)稳定性上
,比如全链路,如果要做统一的Trace打点,本来在一套框架上就可以实现的,结果要再多个框架上实现。对于开关、限流、降级这些策略也一样,很难统一。实际上为后续的体系建设增加了很多额外的工作;
(6)上线后的日志采集
,因为跟其它团队使用的框架不一样,自己在搞一套日志采集的系统,说白了都是ELK,但是因为太个性化不统一,只能自己搞个;
(7)……
以上还不包括之前提到的类似于Java版本、启停方式、
web容器类型、各种部署目录等。所以到了运维阶段,不统一不标准,压根就没法玩下去了。这时我们就不难理解,架构的标准对于运维阶段的建设其实是有决定性的意义的。
可能有的人会说我们做得low,管理上有问题,我不否认,现在回过头来看,当时确实是low了,管理上确实无意识没经验。不过在当时的情况下,特别是在初期,除非团队中能有一个技能和经验非常全面的角色,端到端hold住全局,否则只能是靠摸爬滚打摸索出来。
现实情况,我之前经历的多个项目,包括在华为的大型的电信和互联网项目,以及当前我接触到的很多的队也仍然还是这种玩法,必然得走很长一段分久必合的道路才能走到正道上来,而且这种能力超群的牛人,我不敢说没有,但是我能遇到的真的凤毛麟角。
根本上,还是经验意识上的缺失,而且在这一块,架构的资料中貌似很少有涉及到这一部分的内容。当然,最终期望这样的经验能够给到业界一些帮助和指导。
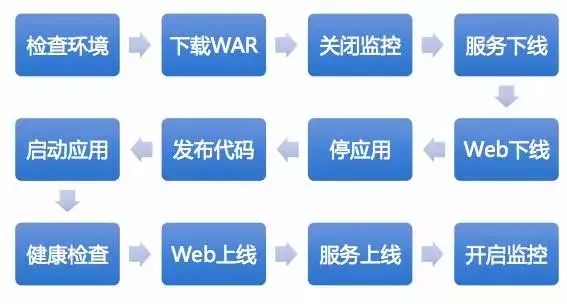
所以这时,运维必须要有意识参与进去制定架构标准,并强势地约束,所谓的约束是要体现在技术平台上的,比如在发布系统和安装部署上做约束,以Java举例,只支持固定1-2个Java版本,目录都约定好,容器约定好,服务化的框架约定好,这些约定好之后,如果线上要做变更,做发布,必须接入这套体系,否则坚决不让你上线,而且到了后面随着集群规模的增大,开发想绕都绕不开,因为完全靠手工已经是不可能的事情了,比如下图,是一个应用单机的发布部署过程,如果这个应用有100台机器怎么办?
再比如,稳定性上,我们做全链路,我们只针对标准的分布式框架做打点(当然精力有限,也不可能支持所有的框架),如果你选择的不是标准框架,而是自研或自己引入的,抱歉,打点只能自己做。这时遇到性能瓶颈或链路上的异常,如果使用的是标准框架,有全链路根据平台的支持,日志采集、分析和报表呈现就很方便,问题定位过程相对高效一些,如果不是,抱歉,只能手工地去定位了,一个请求分布那个应用的那台机器上去了,在这样一个分布式的环境中,效率可想而知。同样的,开关、限流、降级策略下发等,一样会有相同的问题。
作为线上资源的控制者,稳定性的Owner,运维,你有权利Say No!
当然,历史原因造成的架构标准不统一的问题,是需要Dev和Ops共同合作去改造的,而不是很强势、单纯地去提要求,这个涉及双方合作方式的问题,后面再单独写篇文章。
1
、架构实施和架构运维
我们制定或约定了架构标准,接下来就是架构的实施过程,架构实施应该怎么理解呢?我大致列一下过程应该就比较清晰了:
(1)业务分析过程中,职责明确的业务模块从整体中拆分出来,比如用户、商品、交易、支付等业务逻辑;
(2)从服务化的角度拆分,这样一个大的业务逻辑可以拆分出更细的服务化模块,以商品为例,会有商品详情、库存、评价、价格、标签等,如果继续细分可能还会有各种读写逻辑的功能化服务拆出来,拆分的原则我们这里不细说,这个基本取决于业务架构师的判断标准;
这个阶段拆出来的一个个模块,就是我们所说的应用了,这时就要开始应用名的定义,至此,一个应用的生命周期开始启动。
(3)应用生命周期启动后,应用相关的信息就需要在运维系统内生成了,也就是我们所说的CMDB和应用配置管理相关的信息。重要的跟运维相关的如应用对应的Gitlab地址、基础软件模板和配置、以及对应的开发、测试和线上的资源需求;
(4)根据上面拆分出来的应用,开发同学就要根据我们之前约定的架构标准,开始选择标准化的框架了,比如分布式服务化、消息、缓存、DB中间件、稳定性和一些第三方的SDK包等;
熟悉开发的同学都很清楚,上面这些框架选定好之后,按照Spring Boot的模式,可以自动生成整套的代码框架,就省去了手工引入各种二方包、三方包和一些固定的配置,也就是Spring Boot的“约定大于配置”的思路。这个也是目前绝大部分团队的选择的微服务的应用模式。
这样开发同学可以把更多的精力放到业务逻辑的实现上,而不是各种各样的框架引入和配置上面。所以,不仅仅是运维自动化,代码开发也一样在朝着更加自动化的方向发展。(再进一步,Spring Cloud的体系则更加完善)
(5)启动业务代码开发后,就该进入到持续交付阶段了,不过前提是得先有持续交付的体系;
(6)业务上线后,就进入持续运维和反馈阶段,如监控数据的分析、稳定性保障、核心应用和链路的容量评估、应急预案的制定和演练、强弱依赖的分析,以及从用户提交角度的数据分析和保障措施等;





