今天这篇是R语言 with Python系列的第三篇,主要跟大家分享数据处理过程中的数据塑型与长宽转换。
其实这个系列算是我对于之前学习的R语言系列的一个总结,再加上刚好最近入门Python,这样在总结R语言的同时,对比R语言与Pyhton在数据处理中常用解决方案的差异,每一个小节只讲一个小知识点,但是这些知识点都是日常数据处理与清洗过程中非常高频的需求。
不会跟大家啰嗦太多每一个函数的详细参数,只列出那些参数中的必要设定,总体以简单实用为原则。如若需要详细了解每一个函数的内部参数,还是需要自己查阅官方文档。
数据长宽转换是很常用的需求,特别是当是从Excel中导入的
汇总表时
,常常需要转换成一维表(长数据)才能提供给图表函数或者模型使用。
在R语言中,提供数据长宽转换的包主要有两个:
reshape2::melt/dcast
tidyr::gather/spread
library("reshape2")
library("tidyr")
mydata
Name = c("苹果","谷歌","脸书","亚马逊","腾讯"),
Conpany = c("Apple","Google","Facebook","Amozon","Tencent"),
Sale2013 = c(5000,3500,2300,2100,3100),
Sale2014 = c(5050,3800,2900,2500,3300),
Sale2015 = c(5050,3800,2900,2500,3300),
Sale2016 = c(5050,3800,2900,2500,3300)
)
数据重塑(宽转长):
melt函数是reshape2包中的数据宽转长的函数
mydata
mydata, #待转换的数据集名称
id.vars=c("Conpany","Name"), #要保留的主字段
variable.name="Year", #转换后的分类字段名称(维度)
value.name="Sale" #转换后的度量值名称
)

转换之后,长数据结构保留了原始宽数据中的Name、Conpany字段,同时将剩余的年度指标进行堆栈,转换为一个代表年度的类别维度和对应年度的指标。(即转换后,所有年度字段被降维化了)。
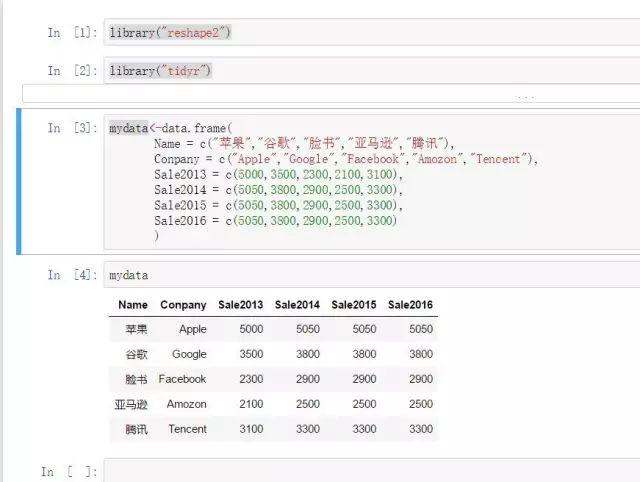
在tidyr包中的gather也可以非常快捷的完成宽转长的任务:
data1
data=mydata, #待转换的数据集名称
key="Year", #转换后的分类字段名称(维度)
value="Sale" , #转换后的度量值名称
Sale2013:Sale2016 #选择将要被拉长的字段组合
) #(可以使用x:y的格式选择连续列,也可以以-z的格式排除主字段)
而相对于数据宽转长而言,数据长转宽就显得不是很常用,因为长转宽是数据透视,这种透视过程可以通过汇总函数或者类数据透视表函数来完成。
但是既然数据长宽转换是成对的需求,自然有对应的长转宽函数。
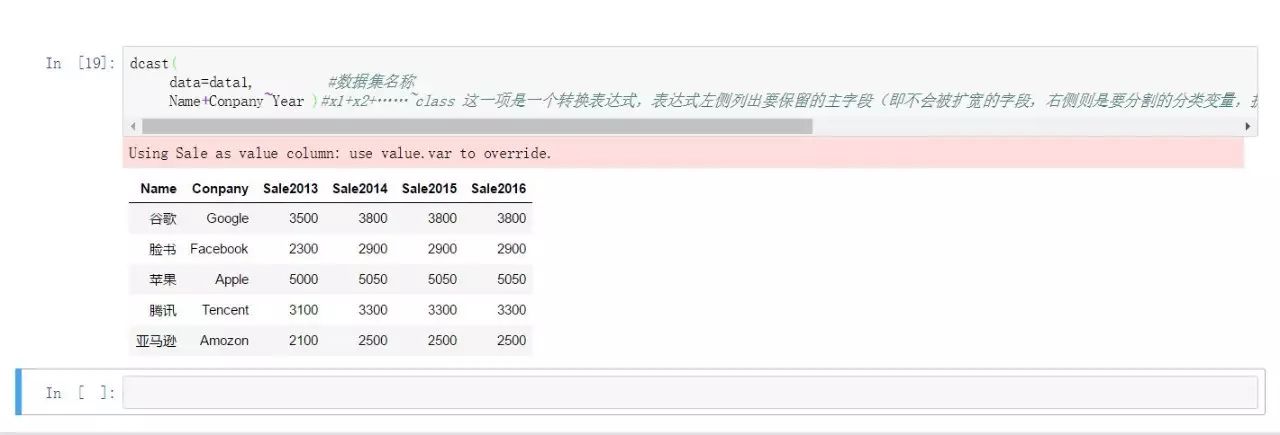
reshape2中的dcast函数可以完成数据长转宽的需求:
dcast(
data=data1, #数据集名称
Name+Conpany~Year #x1+x2+……~class
#这一项是一个转换表达式,表达式左侧列
#出要保留的主字段(即不会被扩宽的字段,右侧则是要分割的分类变量,扩展之后的
#宽数据会增加若干列度量值,列数等于表达式右侧分类变量的类别个数
)
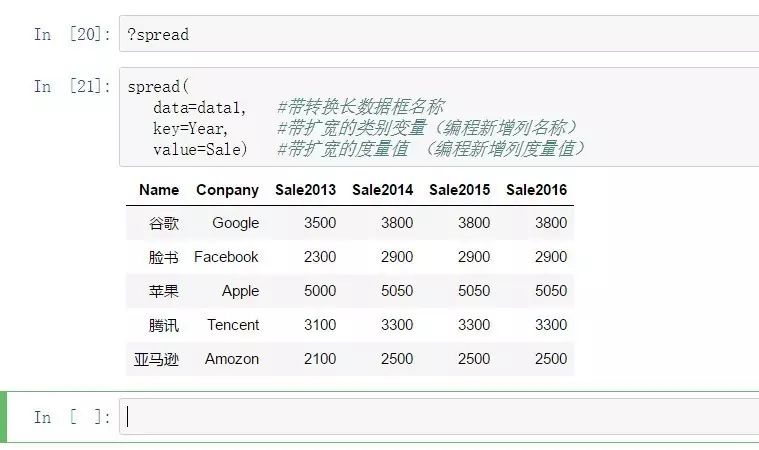
除此之外,tidyr包中的spread函数在解决数据长转宽方面也是很好的一个选择。
spread:
spread(
data=data1, #带转换长数据框名称
key=Year, #带扩宽的类别变量(编程新增列名称)
value=Sale) #带扩宽的度量值 (编程新增列度量值)
从以上代码的复杂度来看,reshape2内的两个函数melt\dcast和tidyr内的两个函数gather\spread相比,gather\spread这一对函数完胜,不愧是哈神的最新力作,tidyr内的两个函数所需参数少,逻辑上更好理解,自始至终都围绕着data,key、value三个参数来进行设定,而相对老旧的包reshape2内的melt\dcast函数在参数配置上就显得不是很友好,他是围绕着一直不变的主字段来进行设定的,tidyr包则围绕着转换过程中会变形的维度和度量来设定的。
接下来是Python中的数据塑性与长宽转换。
Python中我只讲两个函数:
-
melt #数据宽转长
-
pivot_table #数据长转宽
Python中的Pandas包提供了与R语言中reshape2包内几乎同名的melt函数来对数据进行塑型(宽转长)操作,甚至连内部参数都保持了一致的风格。
import pandas as pd
import numpy as np
mydata=pd.DataFrame({
"Name":["苹果","谷歌","脸书","亚马逊","腾讯"],
"Conpany":["Apple","Google","Facebook","Amozon","Tencent"],
"Sale2013":[5000,3500,2300,2100,3100],
"Sale2014":[5050,3800,2900,2500,3300],
"Sale2015":[5050,3800,2900,2500,3300],
"Sale2016":[5050,3800,2900,2500,3300]
})
mydata1=mydata.melt(
id_vars=["Name","Conpany"], #要保留的主字段
var_name="Year", #拉长的分类变量
value_name="Sale" #拉长的度量值名称
)
除此之外,我了解到还可以通过stack、wide_to_long函数来进行宽转长,但是个人觉得melt函数比较直观一些,也与R语言中的数据宽转长用法一致,推荐使用。
奇怪的是我好像没有在pandas中找到对应melt的数据长转宽函数(R语言中都是成对出现的)。还在Python中提供了非常便捷的数据透视表操作函数,刚开始就已经说过是,长数据转宽数据就是数据透视的过程(自然宽转长就可以被称为逆透视咯,PowerBI也是这么称呼的)。
pandas中的数据透视表函数提供如同Excel原生透视表一样的使用体验,即行标签、列标签、度量值等操作,根据使用规则,行列主要操作维度指标,值主要操作度量指标。
那么以上长数据mydata1就可以通过这种方式实现透视。








