本文为1月17日MIT计算机科学和人工智能实验室的四年级在读博士生周博磊同学关于“理解和利用CNN的内部表征 ”直播分享中的材料.
提纲
随着深度学习架构的成功,特别是卷积神经网络在视觉处理以及百万级标定图片数据库上达到的成就,计算机视觉的前沿技术突飞猛进。这种持续的进步的一个重要因素是理解这些深度学习架构中内部隐层所学到的数据表示。
在这个工作里,我们首先对比分析了用ImageNet训练的用于物体识别的CNN的内部表示和用Places数据库训练的用于场景识别的CNN。由于场景是有物体构成的,我们发现用于场景分类的CNN可以自动的学习并发现有意义的物体检测器。基于这个发现,我们的工作展现了同一个神经网络,在不需要显示的学习物体标识和定位的条件下,可以在一个前馈过程同时做到场景识别和物体定位。
这个分享主要基于我在ICLR’15、CVPR’16发表的工作以及一些还在进行的工作。




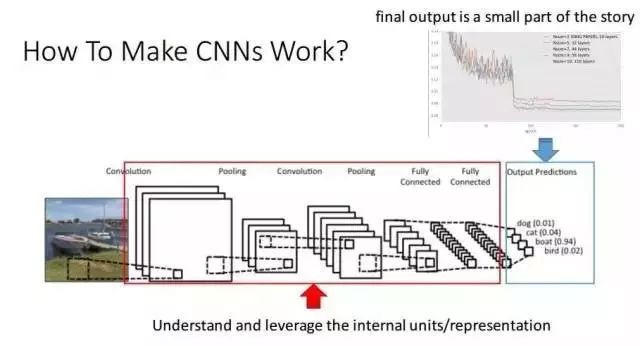

点击“阅读原文”即可获取讲座完整ppt和视频。
原文链接:
https://mp.weixin.qq.com/s?__biz=MzAxMzc2NDAxOQ==&mid=2650360900&idx=2&sn=f8c05077de45a065a119b9408d23dd5b&chksm=83907898b4e7f18e668e7d195598b432175cb7a188cea339e98464dd25f9110ff11827c23331&mpshare=1&scene=1&srcid=0118DVURvzvwjtPFb54GAayf&pass_ticket=sOQDUcwvQXF1ebHKP0%2BfMRd%2Fefn3q7UWj1IfpDCo5Js%3D#rd




