1 前言
GC
中文直译垃圾回收,是一种回收内存空间避免内存泄漏的机制。当
JVM
内存紧张,通过执行
GC
有效回收内存,转而分配给新对象从而实现内存的再利用。
JVM
的
GC
机制虽然无需开发主动参与,减轻不少工作量,但是某些情况下,自动
GC
将会导致系统性能下降,响应变慢,所以这就需要我们提前了解掌握
GC
机制。当面对这种情况时,才能从容不迫的解决问题。另外
GC
机制也是
Java
面试高频考题,了解掌握 GC 是一项必备技能。
学习
GC
,首先我们解决三个问题:
2 什么是垃圾
我们先来看一段简单的代码。

上面代码通过将字符串对象转化成字节数组,然后写入本地文件。方法一旦开始执行,就将会在分配一定内存给新建的对象,然后将引用告诉了
str
,
bytes
变量。等到方法执行完毕,方法内部局部变量紧接着就会被销毁。但是这样仅仅销毁了局部变量,却没有带走内存上这些实际的对象。这类不再起作用,没有被引用的对象,将其归类为垃圾。
在偌大的内存上存活着无数对象,
GC
之前需要准确将这些对象标记出来,分为存活对象与垃圾对象。这个过程一旦少标记,那就只能等待下次
GC
标记,再回收,这样将会影响 GC 效率。另外决不能错标记,将正常存活对象标记为垃圾。一旦回收正常存活的对象,可能就会引起程序各种崩溃。
目前有两种算法可以用来标记:
2.1 引用计数法
引用计数法通过在对象头分配一个字段,用来存储该对象引用计数。一旦该对象被其他对象引用,计数加 1。如果这个引用失效,计数减 1。当引用计数值为 0 时,代表这个对象已不再被引用,可以被回收。
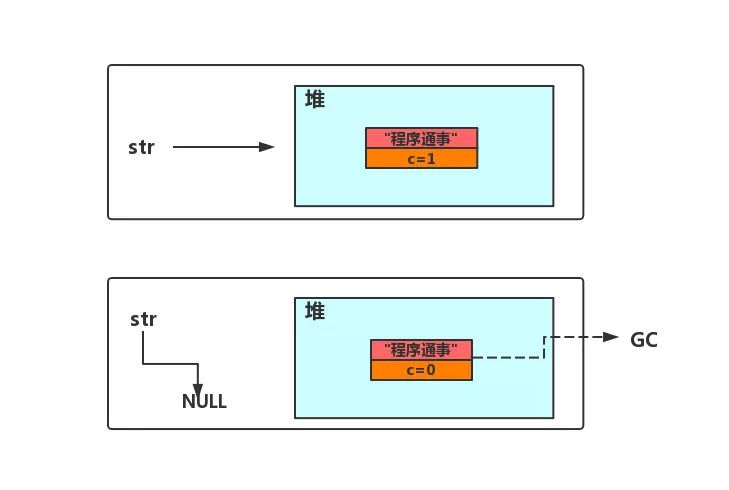
如上图所示,当
str
引用堆中对象时,计数值增加为 1。当
str
变为
null
时,既不再引用该对象,计数值减 1。此时该对象就可以被
GC
回收。
引用计数法只需要判断计数值,所以实现比较简单,这个过程也比较高效。但是存在一个很严重的问题,无法解决对象循环引用问题。
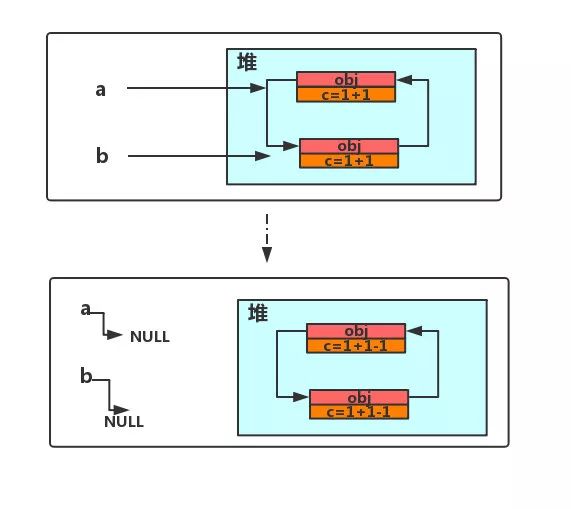
从上图可以看到,
a
,
b
不再引用堆中对象,导致计数减一。此时两个对象内部还存在互相引用,计数值不为 0,此时
GC
没办法回收该对象。
2.2 可达性分析法
这个算法首先需要按照规则查找当前活跃的引用,将其称为
GC Roots
。接着将
GC Roots
作为根节点出发,遍历对象引用关系图,将可以遍历(可达)的对象标记为存活,其余对象当做无用对象。
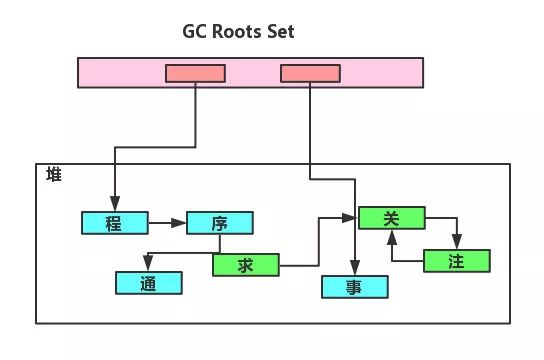
注意这里是是
引用
,而不是对象。
从上图可以看到,绿色对象虽然存在循环引用,但是由于这些对象不能被
GC Roots
遍历到,所以将会被回收。
可以被当做
GC Roots
活跃引用包括但不限于以下引用:
3 在哪里回收垃圾
还记得刚开始接触
Java
时,只知道堆栈,对象实例分配在堆中,方法中局部变量位于栈中。实际上
JVM
内存区域划分更加细致,分为:

如图所示,我们将内存划分为线程私有与线程共享的区域。方法区与堆都是线程共享的区域,这两部分占用
JVM
大部分内存,剩下三个小弟将会跟线程绑定,随着线程消亡,自动将会被
JVM
回收。
堆应该是大家最熟悉的一块区域,几乎所有对象实例都将会在此出生,通常也是虚拟机上占用内存最大一块区域,简直就是
JVM
内存中的大哥大。堆内存内部也不是简简单单一块而已,目前将会根据分代算法,将堆分代,不同对象位于不同区域。这一点我们下文再详细了解。
方法区将会保存已被虚拟上加载的类信息、常量,静态变量,字节码等信息,堆上的对象正式通过方法区这些信息,才能正确创建出来。
虚拟机栈栈由一系列栈帧组成,每个栈帧其实代表一个方法,栈帧中将会保存一个方法的局部变量表,方法出入口信息,操作栈等。每当调用一个方法,就将会把这个栈帧压入栈中,执行结束,出栈。
本地方法栈与虚拟机栈比较类似,最大区别在于,虚拟机栈执行的
Java
方法,而本地方法栈将会用来执行
Native
方法服务。下面方法就会在本地方法栈中执行。
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
程序计算器可以说是这几块区域占用最小的一部分,但是功能却十分重要。Java 源代码通过编译变成字节码,然后被 JVM 载入运行之后,将会变成一条条指令,而程序计数器的工作就是告诉当前线程下一条需要执行指令。这样即使发生了线程切换,等待恢复的时候,当前线程依然知道接下去要执行的指令。
4 怎么回收
目前主流 GC 算法主要分为三种:
4.1 标记-清除算法
这是一个最为基础也是最容易实现的算法,主要实现步骤分为两步:标记,清除。
-
标记:通过上述
GC Roots
标记出可达对象。
-

ps:这个图着实难画啊。。。。
可以看到经过这个算法回收之后,虽然堆空间被清理出来,但是也产生很多
空间碎片
。这就会导致一个新对象根据堆剩余容量计算,看起来是可以分配,但是实际分配过程,由于没有连续内存,导致虚拟机感知到内存不足,又不得不提前再次触发
GC
。
可能这里你就会有疑惑,为什么对象需要分配一块连续的内存?
这里引用一下 R 神 @RednaxelaFX 答案。
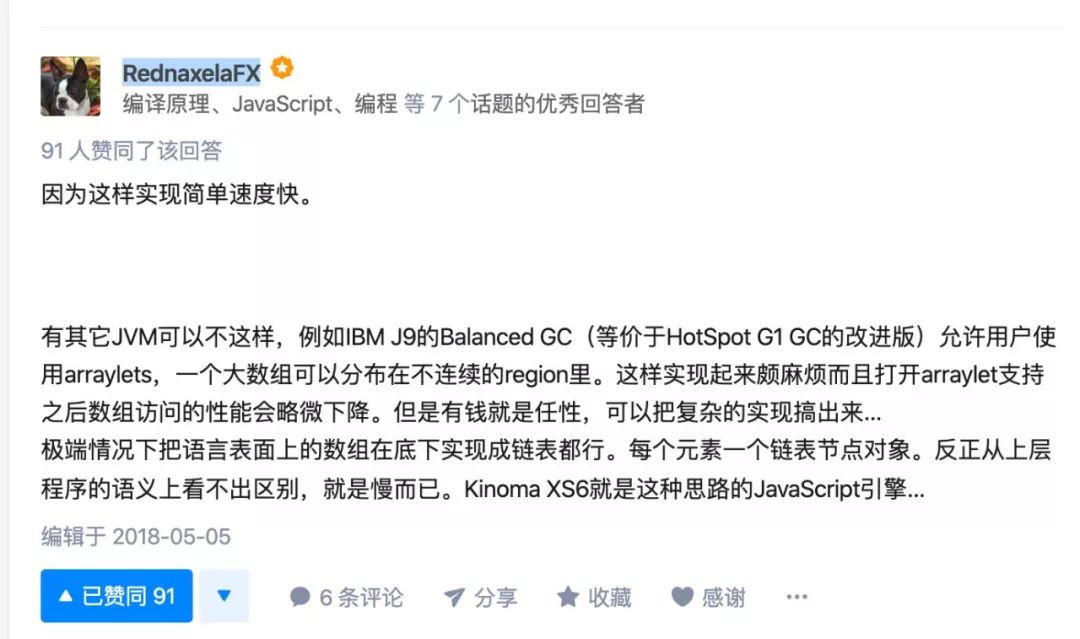
另外这个算法还有一个不足:标记与清除效率比较低。这就竟会导致
GC
占用时间过长,影响正常程序使用。
4.2 复制算法
为了解决上述效率问题,诞生复制算法。这个算法将可用内存分为两块,每次只使用其中一块,当这一块内存使用完毕,触发
GC
,将会把存活的对象依次复制到另外一块上,然后再把已使用过的内存一次性清理。

这个算法每次只需要操作一半内存,
GC
回收之后也不存在任何空间碎片,新对象内存分配时只需要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。但是这个算法闲置一半内存空间,空间利用效率不高。
PS:复制算法以空间换时间,两者不可兼得
另外对象存活率也会影响复制算法效率。如果对象大部分都是朝生夕死,只需要移动少量存活对象,就能腾出大部分空间。反而如果对象存活率高,这就需要进行较多的复制操作,回收之后也并没有多余内存,这就可能导致频繁触发
GC
。
针对这种存活时间长的对象,就需要使用标记-整理算法。









