转自
佩服 量子位
李林 问耕 编译自 Arxiv
量子位 出品 | 公众号 QbitAI
最近,Google又在论文题目上口出狂言:One Model To Learn Them All,一个模型什么都能学。
非营利研究机构OpenAI的研究员Andrej Karpathy在Twitter上评论说,Google在把自己整个变成一个大神经网络的路上,又前进了一步。
这个题目,可以说继“Attention Is All You Need”之后,再为标题党树立新标杆,量子位作为媒体自愧不如。
这篇最近预发表在Arxiv上的论文说,深度学习挺好,但是每解决一个问题都得建一个模型,还要花好长时间调参、训练,太讨厌了。
于是,他们搞出了一个在
各种领域的很多问题上效果都不错
的模型MultiModel。
他们现在在训练这个神经网络识别ImageNet图像、进行多种语言的翻译、在COCO数据集上根据图片生成文字说明、做语音识别、做英文语法分析。
这个
德智体美劳
全面发展的模型,包含卷积层、注意力机制、稀疏门控层。
上面提到的每个计算模块,都会在某些类任务中发挥着关键作用,但有意思的是,就算在那些发挥不了关键作用的任务中,这些模块也没捣乱,大多数时候还稍微有点用……
在数据比较少的任务上,用这个模型和其他任务联合训练效果尤其好。虽然有时候大型任务的性能会下降,也只是降了一点点。
摘要就讲了这些,接下来我们看看论文的详细内容:
1. 简介
多任务模型这个问题,并不是谷歌突发奇想开始研究的,以前也有不少相关论文。但是原来的模型都是一个模型训练一类任务:翻译的归翻译,识图的归识图。
也有那么一两篇用一个模型训练多种不相关任务的,但效果都不怎么好。
于是,Google Brain的同学们就搞了个MultiModel,用一个模型,可以同时学习不同领域的多个任务。
现在,MultiModel就同时在8个数据集上进行训练:
(1) 《华尔街日报》语音语料库
(2) ImageNet数据集
(3) COCO图片说明数据集
(4) 《华尔街日报》句法分析数据集
(5) WMT英-德翻译预料库
(6) WMT德-英翻译预料库
(7) WMT英-法翻译预料库
(8) WMT法-英翻译预料库
论文作者们说,模型在这些任务上的表现都不错,虽然算不上顶尖水平,但也比最近很多研究强。
下图举例展示了MultiModel模型的学习成果:
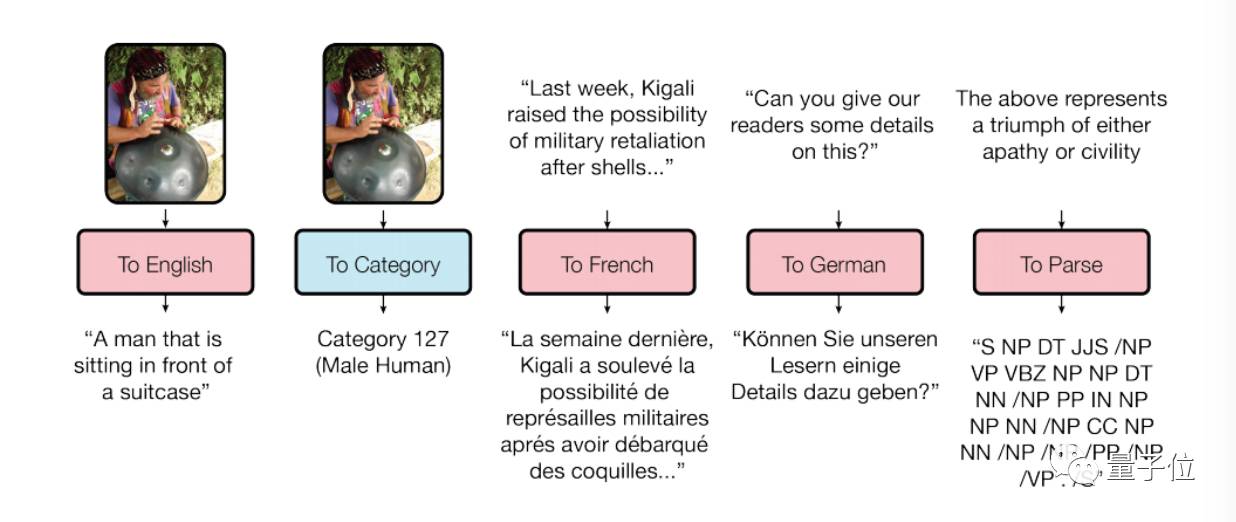
△
从左到右分别是生成图片说明、图像分类、英译法、英译德、句法分析
为了在不同维度、大小、类型的数据上进行训练,MultiModel由多个特定模式的子网络对这些输入数据进行转换,并放进一个共同的表示空间。这些子网络叫做“
模式网络
(modelity nets)”。
2. MultiModel架构
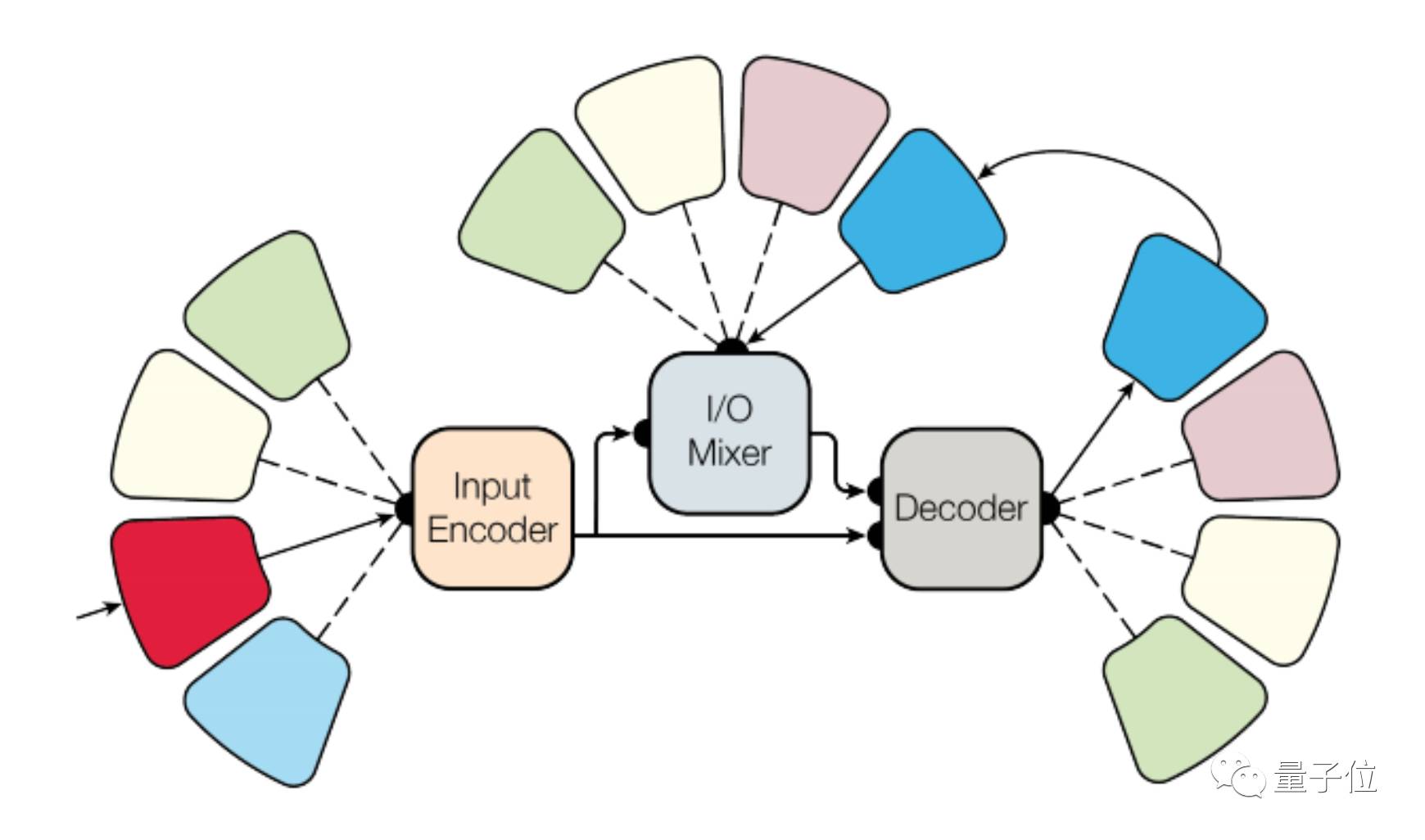
如上图所示,MultiModel由几个模式网络、一个编码器、I/O混合器、一个自回归解码器构成。
这个模型的主体,包含多个卷积层、注意力机制、和稀疏门控专家混合层(sparsely-gated mixture-of-experts layers),论文中对这三个部分分别做了说明。
2.1 卷积模块
这个模块的作用是发现局部模式,然后将它泛化到整个空间。
这个卷积模块包含三个组件:线性整流函数(ReLU)、SepConv和归一层。
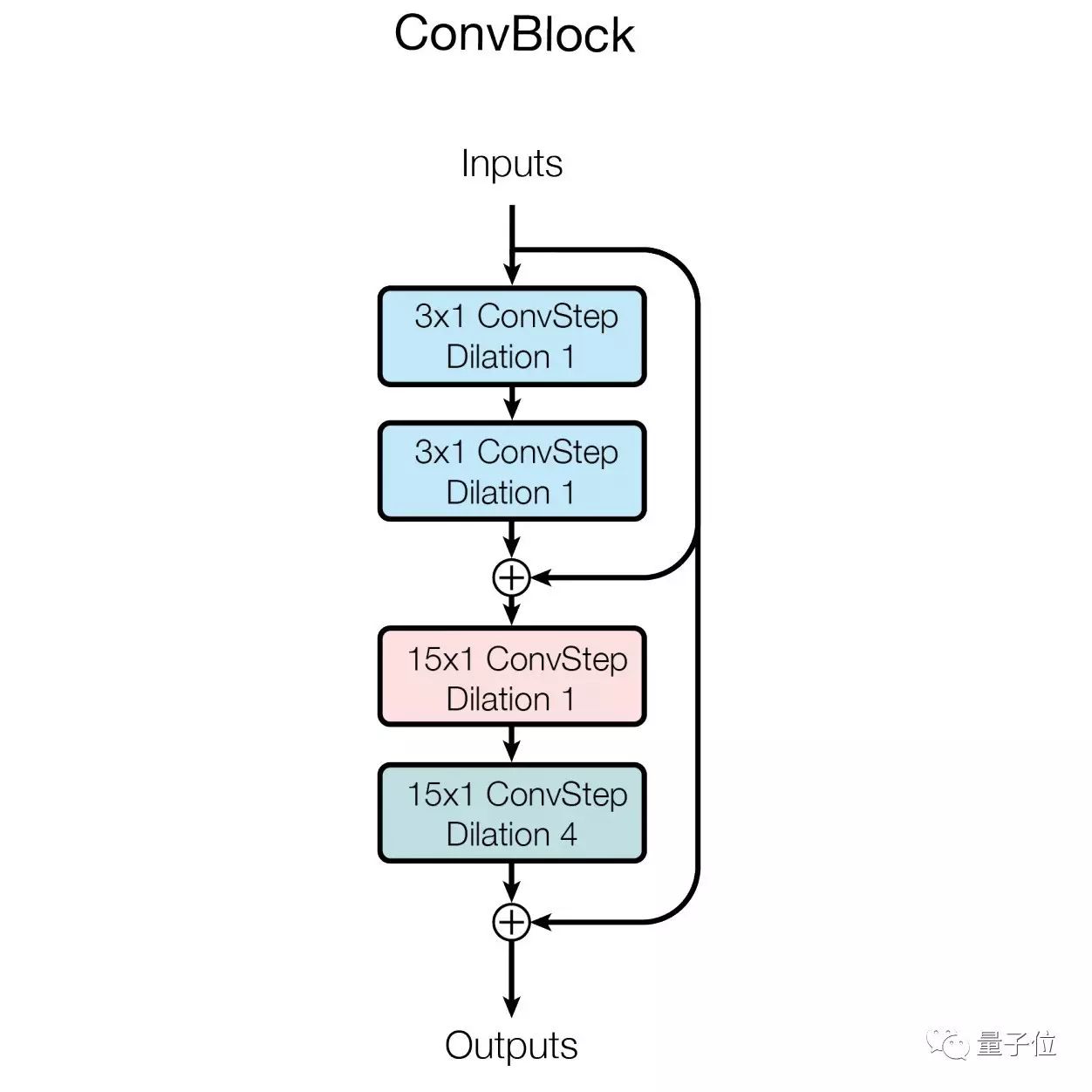
如图所示,这个模型用了四个卷积层,前两层有3×1个卷积核,后两层有15×1个卷积核,每层最后加了40%的dropout。
2.2 注意力模块
MultiModel模型中所用注意力机制和谷歌之前发布的标题党典范论文Attention Is All You Need中差不多。
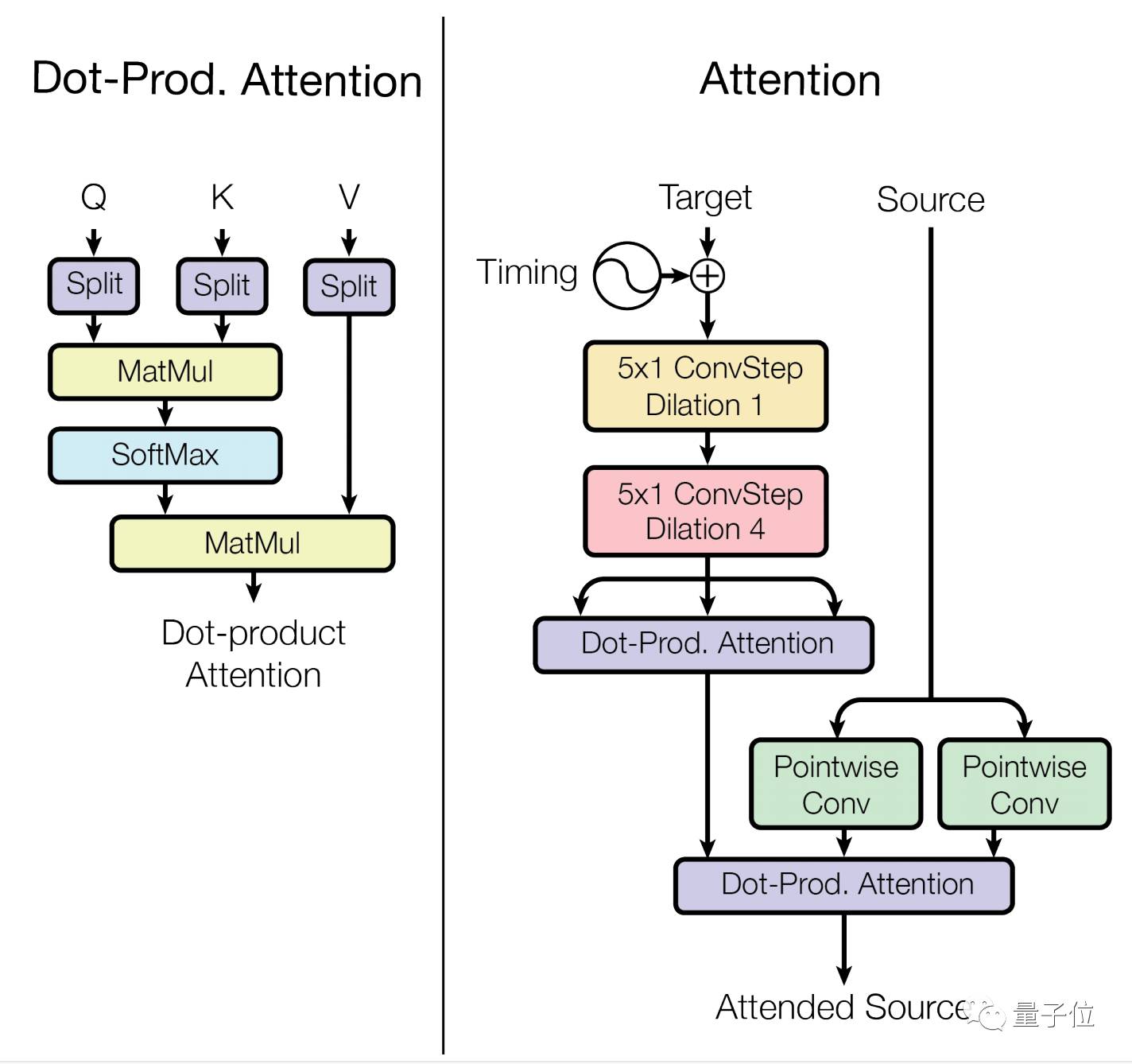
如图所示,注意力层的输入包括两个张量,一个来源张量(source)和一个目标张量(target),形式都是[batch size,sequence length, feature channels]。
本文的注意力模块和以前的主要区别在于是定时信号,定是信号的加入能让基于内容的注意力基于所处的位置来进行集中。
2.3 专家混合模块
MultiModel中的稀疏阵列混合专家层,由一些简单的前馈神经网络(专家)和可训练的门控网络组成,其选择稀疏专家组合处理每个输入。
详情见这篇论文:
Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, Jeff Dean, Noam Shazeer, Azalia Mirhoseini.
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.
arXiv preprint 1701.06538, 2017.
因为MultiModel里的专家混合模块基本是完全照搬。
本文的模型在同时训练8个问题时,用了240个“专家”,训练单个问题时用了60个“专家”。
2.4 编码器、混合器、解码器
MultiModel的主体由3部分组成:仅处理输入的编码器、将编码输入与先前输出(自动回归部分)混合的混合器、以及处理输入和混合以产生新输出的解码器。
编码器、混合器和解码器的结构类似于以前的完全卷积序列到序列模型,如ByteNet或WaveNet,但使用的计算模块不同。
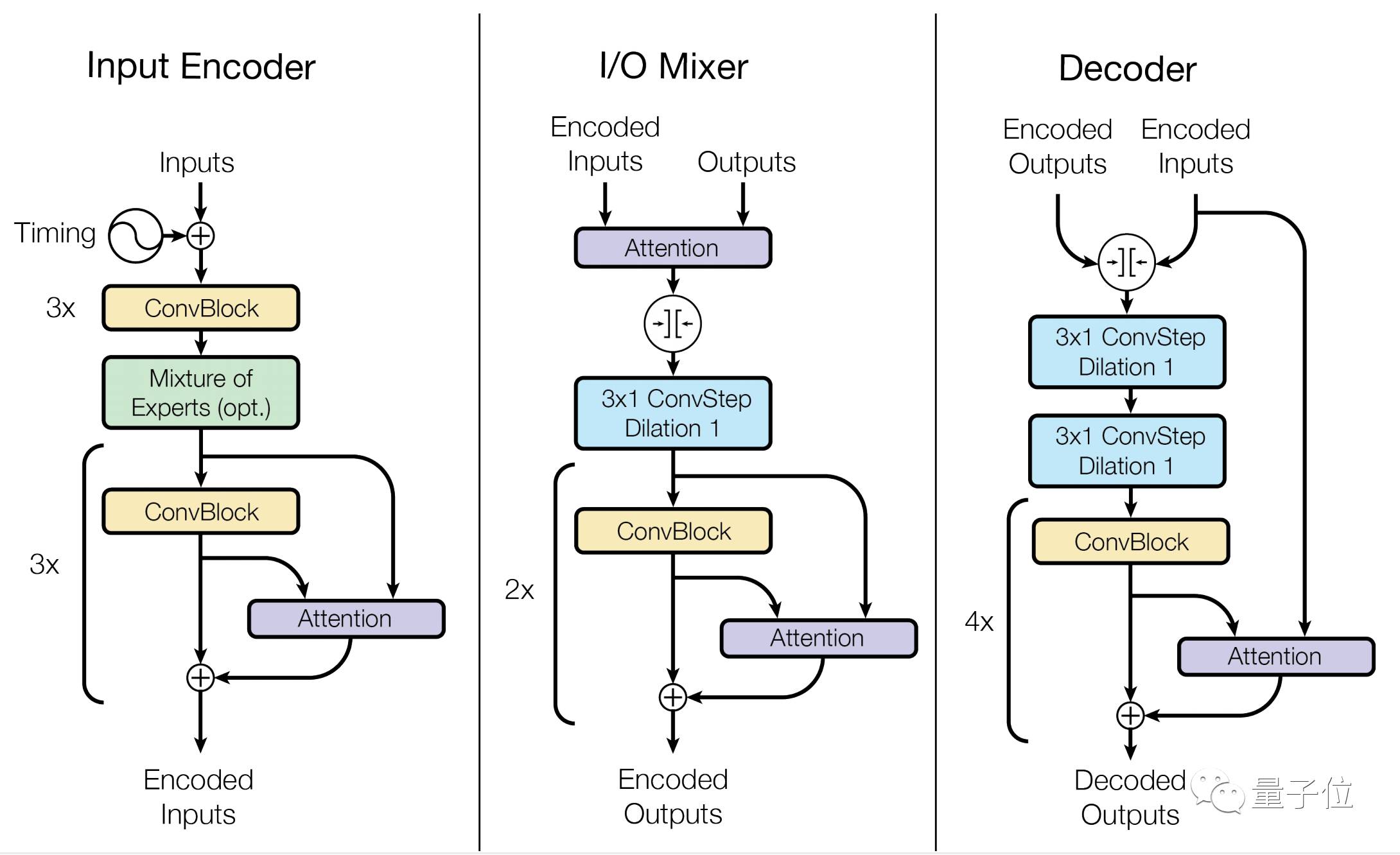
上图描绘了它们的架构。从图中可以看出,编码器由6个重复的卷积模块组成,中间有一个专家混合层。
混合器由注意力模块和2个卷积模块组成。解码器由四个卷积和注意力模块组成,中间有专家混合层。关键的是,混合器和解码器中的卷积填充在左边,所以他们将来永远不会访问任何信息。这让模型是自回归的,并且这种卷积自回归生成方案在输入和过去的输出上提供大的感受野,这能够建立长期依赖性。
为了让解码器即便在相同的模态下,也能为不同任务生成输出,我们总是使用命令令牌开始解码,例如To-English或To-Parse-Tree。我们在训练期间学习一个与每个令牌相对应的嵌入矢量。
2.5 模式网络
我们有4种模态网络,分别对应:语言(文本数据)、图像、音频和分类数据。
2.5.1 语言模式网络
我们将基于语言的数据用和8k subword-units相同的词汇进行标记化。语言输入模式是到终止令牌结束的一系列token。在输出端,语言模式通过解码器进行输出,并执行学到的线性映射和Softmax,生成令牌词汇的概率分布。
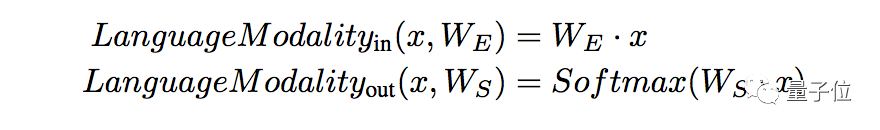
2.5.2 图像模式网络
图像输入模式类似于Xception进入流。 输入图像的特征深度使用残差卷积块逐渐加深,我们称之为ConvRes,并定义如下:
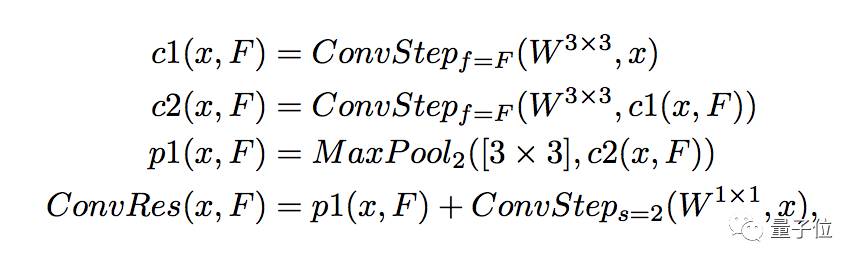
网络深度为d(我们使用了d=1024)的图像模态的输入流定义为:
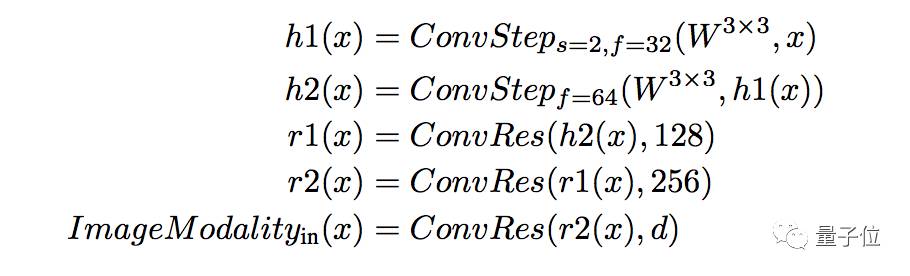
2.5.3 分类模式网络
分类输出模式类似于Xception退出流。 如果网络的输入是诸如图像或光谱音频数据的二维数据,则来自模型体的一维输出首先被重构成二维,然后是逐行下采样:
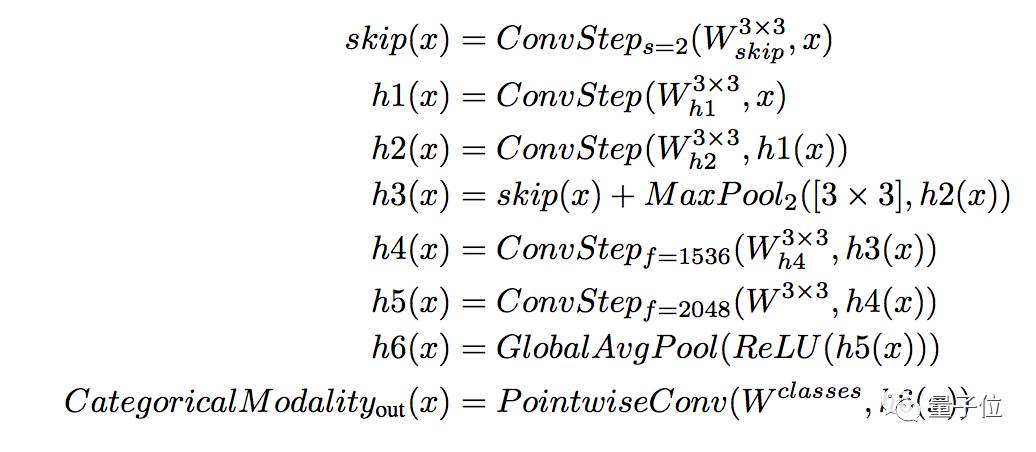
2.5.4 音频模式网络
我们以一维波形或者二维频谱图的形式接受音频输入,这两种输入模式都使用来上面提到的8个ConvRes块的堆栈。
3. 实验
我们使用TensorFlow实现了上述MultiModel架构,并在多种配置中对其进行了训练。










