(点击
上方公众号
,可快速关注)
来源:伯乐在线 - xianhu
如有好文章投稿,请点击 → 这里了解详情
马尔可夫链是一个随机过程,在这个过程中,我们假设前一个或前几个状态对预测下一个状态起决定性作用。和抛硬币不同,这些事件之间不是相互独立的。通过一个例子更容易理解。
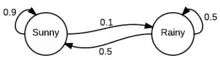
想象一下天气只能是下雨天或者晴天。也就是说,状态空间是雨天或者晴天。我们可以将马尔可夫模型表示为一个转移矩阵,矩阵的每一行代表一个状态,每一列代表该状态转移到另外一个状态的概率。
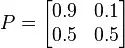
然而,通过这个状态转移示意图更容易理解。
换句话说,假如今天是晴天,那么有90%的概率明天也是晴天,有10%的概率明天是下雨天。
文章生成器
马尔可夫模型有个很酷的应用是一种语言模型,在这个模型中,我们根据当前的一个或几个词预测下一个词是什么。如果我们只是根据上一个词预测,则它是一个一阶马尔可夫模型。如果我们用上两个词预测,则它是一个二阶马尔可夫模型。
在我的实例中,我使用Henry Thoreau的小说Walden做训练。为了好做实验,我也加入了Nietszche的Thus Spoke Zarathustra,以及一些Obama的演讲。无论你训练什么样的文本,模型都会生成相似的结果,是不是很酷?
首先我们引入NLTK,它是Python中最好的NLP库。我想说,虽然我们这里做的自然语言处理很简单,但NLTK的内置函数还是帮我节省了很多代码。然后我们利用split()函数将字符串(从文本文件中获得的)转换成一个数组。
import
nltk
import
random
file
=
open
(
'Text/Walden.txt'
,
'r'
)
walden
=
file
.
read
()
walden
=
walden
.
split
()
上边两个函数是代码的基本函数。我们最终要使用的NLTK中的“条件频率字典”必须以成对数组作为输入,所以短语“Hi my name is Alex”需要变为[(“Hi”, “my”), (“my, “name”), (“name”, “is”), (“is”, “Alex”)]。函数makePairs以一个数组(以词分割字符串得到)作为输入,输出符合上边格式的数组。
生成文章的方法,需要一个条件频率分布作为输入。想想看,“农场”的后边每一个词出现的次数是多少?这是一个“条件频率分布”的输出(对于所有的词,而不只是“农场”)。生成函数的其余部分是根据训练数据中观察到的分布输出文本。我通过创建一个出现在当前词后边的每一个词组成的数组实现这一点。数组中也有正确的计数,因此,接下来我只需要随机选择数组中的一个词即可,而这个过程也是服从分布的。
def
makePairs
(
arr
)
:
pairs
=
[]
for
i
in
range
(
len
(
arr
))
:
if
i
<
len
(
arr
)
-
1
:
temp
=
(
arr
[
i
],
arr
[
i
+
1
])
pairs
.
append
(
temp
)
return
pairs
def
generate
(
cfd
,
word
=
'the'
,
num
=
50
)
:
for
i
in
range
(
num
)
:
arr
=
[]
# make an array with the words shown by proper count
for
j
in
cfd
[
word
]
:
for
k
in
range
(
cfd
[
word
][
j
])
:
arr
.
append
(
j
)
print
(
word
,
end
=
' '
)
word
=
arr
[
int
((
len
(
arr
))
*
random
.
random
())]
最后三行代码,我们输出了一些很像Walden风格的文本。
pairs = makePairs(walden)
cfd = nltk.ConditionalFreqDist(pairs)
generate(cfd)
输出结果:
我建议你看一下我Github上的iPython笔记,因为我继续完成了一个方法。利用这个方法,你只需要输入一个文件名,它就能输出生成的文本。Obama的例子也非常的酷。
如果你想自己尝试一下,只需要创建一个文本文件,然后把它放在合适的目录即可。
觉得本文有帮助?请分享给更多人
关注「算法爱好者」,修炼编程内功





