本文为人人都是产品经理独家约稿
由人人都是产品经理专栏作家@Gara 原创
未经本站许可,禁止转载
数据的使用价值,以其目的,可以分为三类。一类用于验证假说的是否,二类为思维之翻译,三类以趋势做预测。
前者是科学之所以为科学的护盾。这是说,我们总有一些道理,不知出处,或道听途说,或直觉所致,大体上,都可以暂理解为“假说”一类的道理,即未经证实的假设。我们提出一条假说,为验证假说,做了一个实验,总结了一些数字,用数字证明假说正确与否——这是我认为的数据的第一大效用。
第二类效用,举凡KPI、排行榜、算法之类的皆属此列。这类应用的思想是,算法设计者“想”让“谁”得到高分。因此,其数据结果的高度,取决于“规则设计者”的高度——我总是对这一类应用抱有警惕。因我自身偶尔都会扮演一下这“设计者”的角色,而时时苦恼于此。
第三类常见于各类趋势表,可观历史,亦测未来。准确且长远地预测未来是此效用的终极理想。
理论上,时间越近,关联越少,预测越准确。但是我们使用数据总是希望分析更加复杂的事务,因此受限于我们对世界的了解程度,使得预测结果总是存在或多或少的不确定性。
决定论认为事物具有因果联系性、规律性、必然性。通俗点说,就是如果我们理解了宇宙所有物质的运行规律,就可以准确知道未来会发生什么,决定论也认为我此时写下这句话是在世界诞生之初就决定好了的,曰之“命运”。非决定论与其相反,认为世界存在一定的不确定性。
预测科学试图通过特定范围的关联因素及因果性预测出一定程度准确的未来,但是也为“不确定性”保留了“置信区间”。
本文因笔者的学识有限,姑且将焦点放置于第一类效用,即:验证假设。展开为三个部分:一为指标,对基本概念的理解。二为分析,数据分析场景的梳理,及数据后台的设计。三为验证,假说与验证的思考方式。
指标
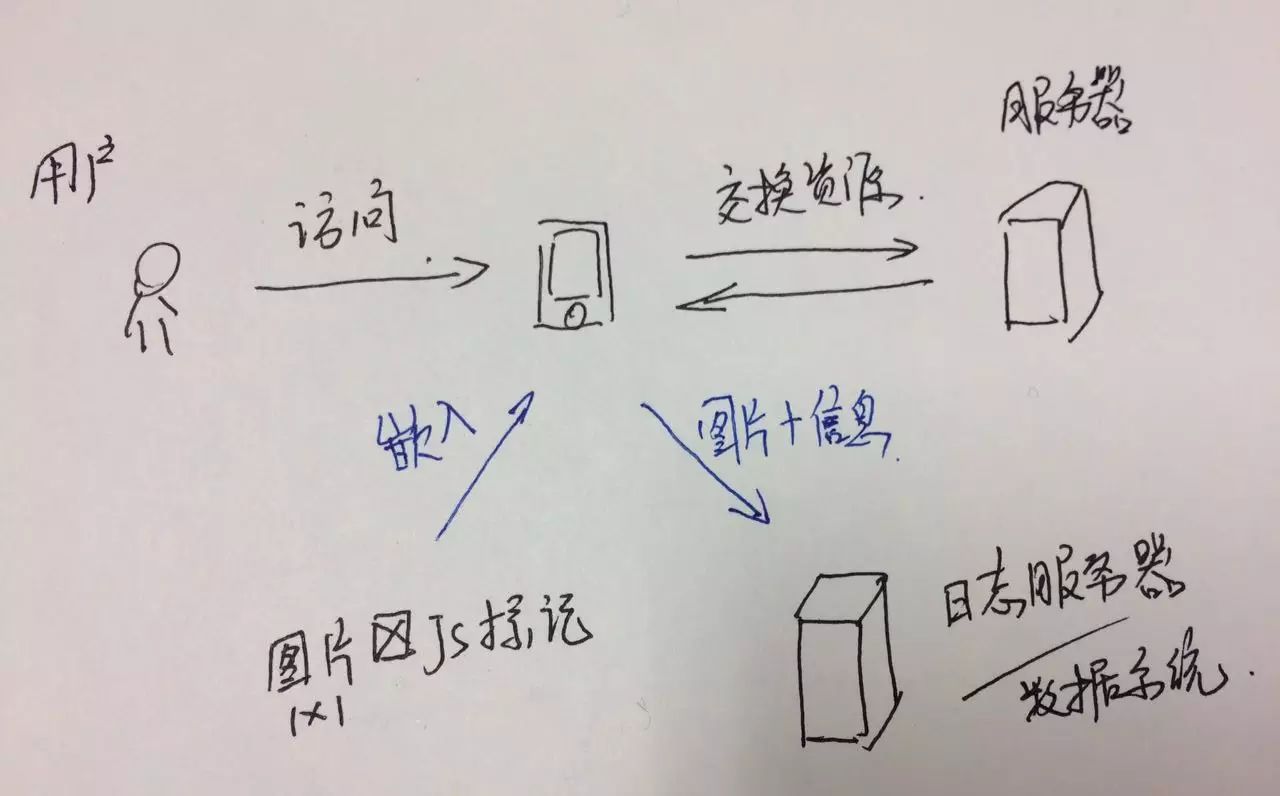
▍数据来源
用户在前台进行各种行为留下痕迹,由于用户行为留下的数据较大,用户有行为就记录,对服务器压力较大,所以会把前台的行为数据单独存储到日志服务器中。
那么按照数据的存储位置,大致会分成行为数据和后台数据两个类型。
第三方数据分析工具获取的都是前台的行为数据,也就是第三方
(比如友盟)
代替了原本的“日志服务器”的角色。
我们在设计数据产品时,应该了解数据来源,并且将不同的数据来源进行对接。
▍数据
由于产品形态的差异,获取数据的类型也有一些差别。
网页产品的组织结构是页面,用户行为从刷新某一个页面开
始到刷新下一个页面结束,PC产品可以获取到的基础数据主要有:
访问终端IP地址
用户访问网站时使用设备的IP地址。不同设备有对应的IP地址,主要用于分辨地域,但是统计结果有较大误差。
访问时间戳
用户访问页面的时间点,用于判断用户行为的时间顺序。如用户访问页面A时记录时间点,访问页面B时记录时间点,可以认为用户在第二个时间点离开了页面A。
访问地址路径
可以理解为用户访问页面URL,用于分辨用户访问网页的目的地,也就是访问了A页面还是B页面。
访问来源
来访的来源信息,比如来自搜索引擎的搜索结果页、直接访问、外链网站等。
来访者的其他信息
操作系统、浏览器、爬虫等信息。这类数据是由来访者表明身份获得的信息,因此取决于来访者的自觉性,有误差。有些浏览器不提供给非合作者信息,非正规爬虫也不会表明信息。
APP产品获
取的基础数据主要有:
终端信息
获取终端
(手机、平板等)
信息用于识别用户
操作系统
OS/Android/Win等
客户端信息
APP上传的自身信息。
客户端时间
用于判断用户启动或操作应用的时间点
操作事件
APP按照自定义事件所需,上传用户的操作行为和伴随这个行为的客户端信息。这是APP区别与PC的一类重要数据,其对用户行为的跟踪比网页通过刷新获取的数据更加精准。
▍用户识别
如果我们想要分析的某个结果需要涉及不同的数据来源
(比如我们的用户在某个时间段使用APP的场景更多还是PC场景更多?)
,那么数据与数据之间的关联工作是最重要的。我们通过用户识别的方式关联不同来源和结构的数据
(识别产品a的用户a和产品b的用户b是同一个用户U)
,以下是三类用户的识别方式:
网站用户识别
如果我们有两个网站产品,我们如何知道有哪些来访者同时访问了AB两个网站呢?
Cookie是网站以一小段文本的形式存放在用户本地终端的信息,以便网站之后的读取。Cookie是目前网站识别访客的主要手段。由于用户禁止或对Cookie进行清理等问题,这个数据结果的误差也会比较大。
APP用户识别
APP的识别方式类似网站,把信息写入终端。由于手机发生信息丢失的情况
(比如刷机)
比较少,所以APP的用户识别相对比较准确。我们可以知道每次启动这个应用的访客是不是我们认识的那一个。
产品用户识别
如果同时有网站端和移动端产品,我们又想知道哪些用户同时使用了网站和APP,由于以上识别方式是基于设备,数据中就无法判断用户了。所以跨产品形态的用户识别通常使用注册用户ID,前提是推动用户的注册和登录行为。
▍指标
以下是我们在产品数据分析中常用的指标。
网站常用的指标
IP地址
PV浏览量:
页面浏览量。每刷新一次页面,被记录为一次PV。
Visit访问次数:
今日早上访客A进入网站后离开,下午访客A又一次进入网站,并记录为2次Visit
(开发者使用会话数session定义一次访问行为,与visit的意义相同)
。
visitor访问者/UV访客数:
本周访客A进入网站10次,记录为1个UV,10个visit
访问时长:
即访客的停留时间,访客先进入页面A然后进度页面B,页面B的访问时间减去页面A的访问时间即访客停留页面A的时长,另外我们定义访客停留时间超过某个时长
(通常是半小时)
即离开网站,一次visit结束。
访问深度:
访客在一次访问行为中,访问了几个页面。
跳
出率/退出率:
访客访问landing page
(一次访问行为的第一个页面,任何一个页面都可能成为这个网站对于用户的登录页)
时离开网站即“跳出”。退出页是指用户这次访问行为的最后一个页面
(因每次访问都必然退出,所以退出率只能用于判断某个页面,网站的退出率理论上是百分之一百)
。
留存率:
留存率通常指整个产品的留存,周日
(起始日)
进入网站的新用户为100人,周一这100人里有50人继续访问了,到下周日,这100人中访问网站的还有2人。可得出,周日网站的次日留存50%,7日留存2%。
上下两图中,整体活跃用户数都在增长,但是留存曲线告诉我们下图留存表现更好,留存曲线在最后趋于平稳,而上图,用户在增加,但是也在不断流失,所以最后用户总数也无法提升。
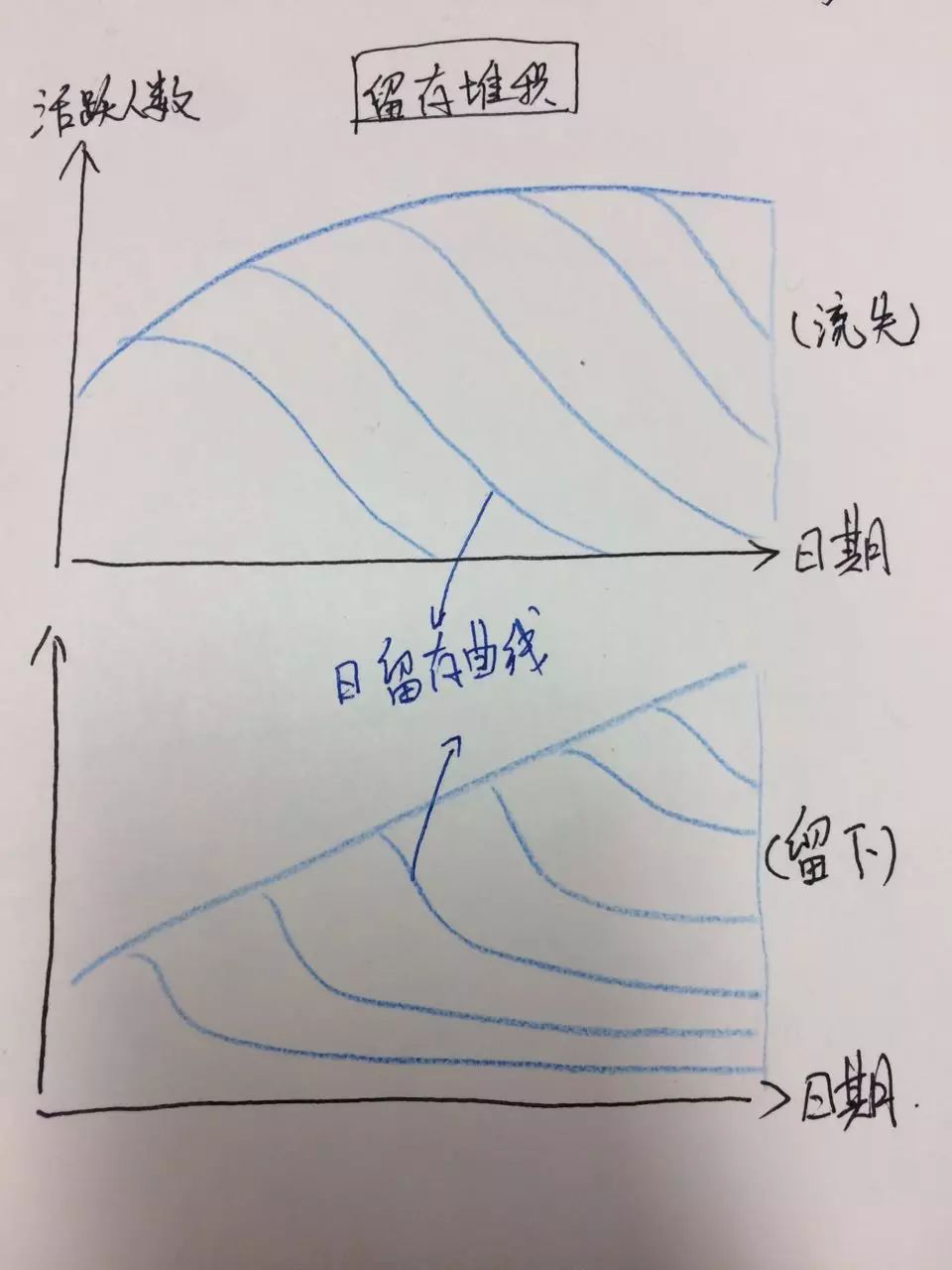
留存是产品运营健康程度的重要指标,不同的留存率走势关系不同的功能和运营周期。比如某产品用户完成核心任务的周期是6日左右,那么我们关注7日留存指标,常见的周期是次日、3日、7日、15日等。
转化率:
转化率是指在开始任务的过程中,通过某个步骤的人数比例:如果一个任务有abc三个步骤,a步骤100人,这100人中50人开始了b步骤,则b步骤的转化率是50%。
转化率经常使用漏斗图进行解读分析,是一个评测产品交互设计的关键指标。我们用它来监测流程中的哪个步骤出现问题,进而寻求解决方案。
APP与网站的差别是APP并非以页面为单位获取数据,并且与网站可以从任意一个页面进入不同,APP启动后停留的位置是基本固定的
(首页,或者开发者指定的页面)
。因此,与页面相关的指标不在APP的常用指标中,比如PV
(页面浏览量)
,访问深度
(浏览的页面数)
,跳出与退出
(进入页与退出页的指标)
等。移动端最有价值的数据集中在对行为事件的统计上。
自定义事件可以对行为、控件、位置等信息进行定义,比如“用户在xx位置,切换xx控件的状态的事件”或者“用户在xx位置,点击xx按钮的事件”等。基本原理是APP在用户进行某个行为时上传
(分析所需的)
信息。
自定义事件帮助我们获得大量的用户行为数据,对各类分析场景都有巨大帮助,比如“我想知道使用功能A
的用户有多大概率使用功能B”,对于转化率的监测也更加精确。
转化率
网站中的转化通常是监测从“页面A–页面B”的用户数,APP中由于自定义事件的存在,可以监测“位置A的按钮A—位置B的图片B”的用户数。
除了以上常用的基础指标,还有一些在分析的过程中被一步一步推理和分解出来。
▍常用的可视化图表
饼图
表达整体的一部分,表达同一个指标的不同部分,饼图适用于规模类数据,直观可理解,但是信息的扩展不足,一张图表通常只能表达一种指标。
柱形图/条形图
这类图表重
于不同系列之间数据的对比。
折线图
折线图更重于时间线上的前后关系,与柱形图不同,相近的数据对比性不强,更加重视整体趋势。由于其可扩展性更强,是最常使用的图表。
下图中还举例了异型图表,以及复合型图表。

分析
▍关注数据的对比
仅访客数可能无法帮助我们得到什么有价值的信息,但新老访客比例可能就暗示了什么;如果今天的购买量不能说明什么,那么今天与昨天的购买量比例就说明了什么——对比才有意义,我们的分析过程是大量的不同维度的数据对比。
▍数据分析的目的
我们首先应该探讨数据为何目的使用。
数据的使用价值远大于数据本身,多数情况,当我们试图进行数据分析的时候,关注的是“能否获得更多收入”或者“能否提供更大价值”。
目的决定视角。
商业目标
商业产品以面向用户的消费为主要营收,所以数据分析的目的是“提高用户营收”,数据的分析视角是“用户使用产品的体验过程
(因为用户为此付费)
”。
社会目标
如果我们的目的是“能否为残疾人提供更大价值”,数据分析的目的是“提高残疾人的生活便利程度”,数据分析的视角是“残疾人使用产品的体验过程
(用户因此获得幸福感)”
。
作为产品人,我建议同时考虑这两个目的,一则为企业消灾,二则为自身格局。
我们将通过用户使用产品的视角,先后获得到用户使用过程中的数据,然后制定关键指标来验证是否达到了目的。
用
户使用产品的过程与其产生的指标
我们已知流程是由一个个任务节点构成的,用户在使用产品的过程中通过一个个任务节点,最终完成流程。
数据从用户进行任务的过程中诞生,且由这些数据构成指标。
下图是某健身产品的用户流程图
(非可操作文档,仅用于逻辑说明的案例)
。跟随图文了解思路。
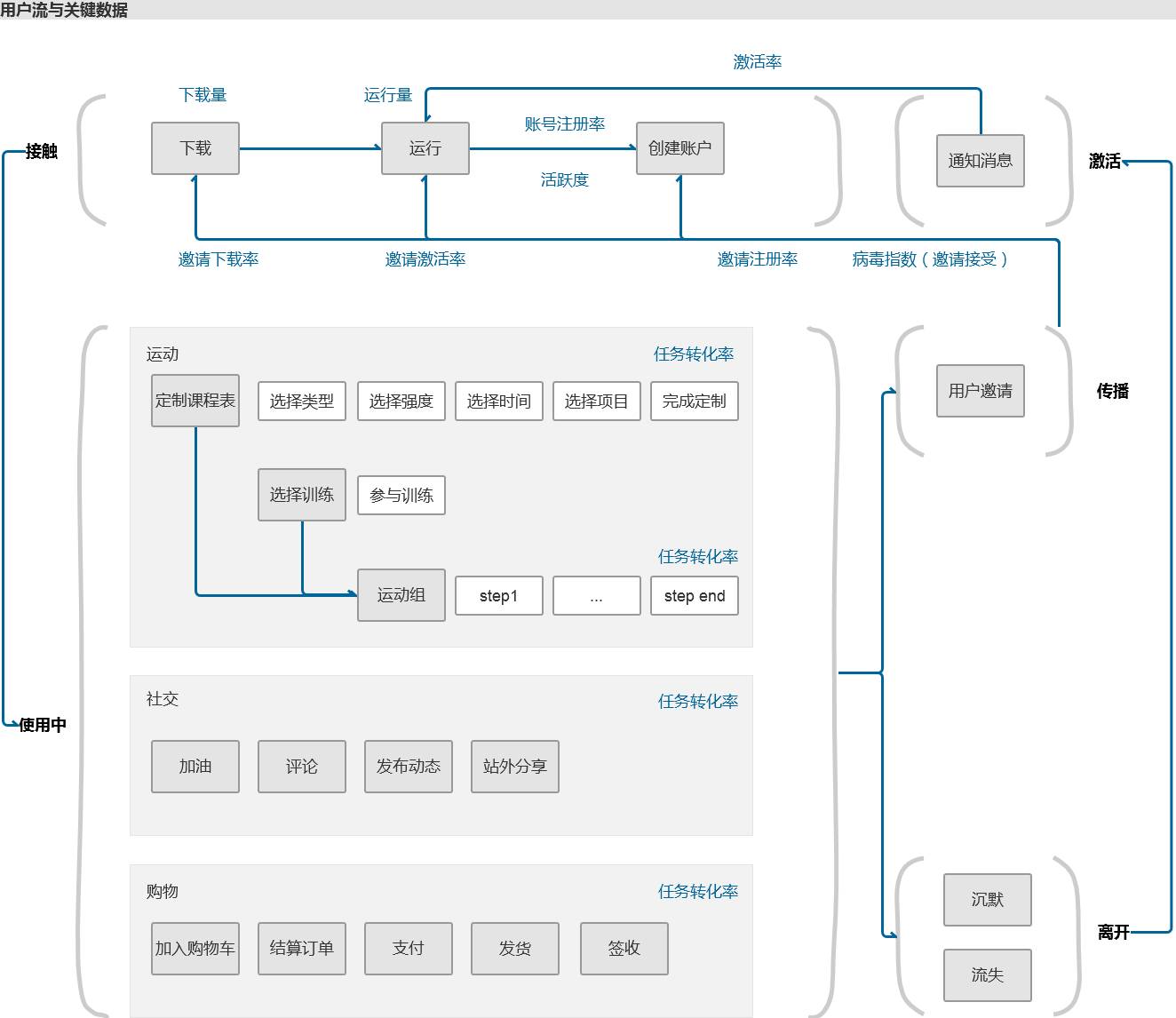
将用户与产品的交互过程按运营工作顺序划分为接触、使用、传播、离开、激活几个区间。
1.对每个区间包含的用户任务进行梳理:
2. 对每一个任务产生的基础指标进行梳理。基础指标通常指“数量”,比如下载产生的指标是“下载量”
3. 对前后任务基础指标的对比,产生一系列前后转化的复合指
标。如运行的下一个步骤是注册,前后对比就产生“注册率”指标。
复合指标不是唯一的,按照运营所需可以进行各种维度的扩展,比如“首次启动注册率”之类的指标。
4. 对关键任务流程进行漏斗型转化。这个工作与上一个步骤相似,它针对有多个复杂任务的重要流程进行转化率的分析。如图中“定制课程表”的流程
(前文对转化率进行过说明,不赘述)
。
5. 其他运营指标。
-
“病毒传播系数”:由邀请与接受邀请构成的指标,用户邀请率×邀请接受率的结果。
-
“活跃用户数”:自定义x时间段内打开过产品的用户数,默认为1日的时候,这个值等于日用户数。
-
“沉默用户数”:自定义x时间段内没有打开过产品的用数,运营可根据这个值设计不同的激活用户的活动。因为无法直接确认用户是否卸载APP,所以可认为超过某个时间段,用户已流失。除了图中涉及的指标,在对自身产品进行分析时,可以分解出更多有价值的指标。
验证
数据验证因其目的,上至下分为以下几类。
▍战略方向
“关键指标”验证方向合理性
传统的数据分析会为产品数据设立KPI,当KPI数值接近优势或危险区域时提醒或警告。“关键指标”的意义与KPI相似,但KPI是为了监控产品的“健康程度”,而“关键指标”是为了“验证目标是否达成”,因此它的应用场景有更大的灵活性,不论是否互联网产品,目的大小,都可以使用这个思考方式。
并且,我们日常可以监控这个“关键指标”,而不是每天都花很多时间去分析每一个指标的数值发生了什么变化。










