本文约3600字,建议阅读5分钟
本文介绍了5大深度学习模型。
深度学习,在人工智能领域不断取得了发展成就。其中,RNN、CNN、Transformer、BERT以及GPT五种深度学习模型,凭借其独特的优势,在计算机视觉、自然语言处理等诸多领域实现了重要突破。
本文将从四大维度——关键技术、数据处理、应用场景以及经典案例,对这五种模型进行简要介绍。首先,在关键技术方面,这五种模型各具特色,它们通过不同的算法和结构来提取数据中的深层信息,实现了高效的特征学习和模式识别。
应用场景:广泛应用于自然语言处理、语音识别、时间序列预测等诸多领域
RNN,作为一种高效的神经网络模型,其核心架构呈现为独特的循环体形式,使之能够有效应对序列数据的处理需求。其最显著的特点在于,RNN在处理当前输入信息的同时,亦能够将之前的信息有效储存于记忆单元之中,进而形成持续性的记忆能力。这种设计赋予了RNN在处理具有时序关系的数据时得天独厚的优势,因此,在自然语言处理、语音识别等任务中,RNN均展现出了卓越的性能与广泛的应用前景。
import torchimport torch.nn as nnimport torch.optim as optimfrom torchtext.legacy import data, datasetsfrom torchtext.legacy import Field
应用场景:广泛应用于计算机视觉、图像分类、物体检测等领域
CNN作为一种独特的神经网络模型,其核心结构由多个卷积层与池化层精妙组合而成。卷积层通过精巧的计算方法,能够有效地从图像中提炼出各类局部特征;而池化层则发挥着至关重要的作用,通过降低特征数量,显著提升了计算效率。正是这样的结构特点,使得CNN在处理计算机视觉任务时表现出色,如图像分类、物体检测等任务皆能游刃有余。相较于RNN,CNN在处理图像数据方面更胜一筹,它能够自动学习图像中的局部特征,无需人工设计繁琐的特征提取器,从而实现了更高效、更精准的处理效果。
Python# 导入所需的库import numpy as npfrom keras.preprocessing.image import ImageDataGeneratorfrom keras.models import Sequentialfrom keras.layers import Conv2D, MaxPooling2Dfrom keras.layers import Activation, Dropout, Flatten, Densefrom keras import backend as K
# 图像的尺寸img_width, img_height = 150, 150
# 设定训练数据和验证数据的路径train_data_dir = 'data/train'validation_data_dir = 'data/validation'nb_train_samples = 2000nb_validation_samples = 800epochs = 50batch_size = 16
if K.image_data_format() == 'channels_first': input_shape = (3, img_width, img_height)else: input_shape = (img_width, img_height, 3)
# 构建CNN模型model = Sequential()model.add(Conv2D(32, (3, 3), input_shape=input_shape))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) # 将3D特征图展平为1D特征向量model.add(Dense(64))model.add(Activation('relu'))model.add(Dropout(0.5))model.add(Dense(1))model.add(Activation('sigmoid')) # 二分类问题使用sigmoid激活函数
# 编译模型model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
# 数据增强,增加模型的泛化能力train_datagen = ImageDataGenerator( rescale=1. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(img_width, img_height), batch_size=batch_size, class_mode='binary')
validation_generator = test_datagen.flow_from_directory( validation_data_dir, target_size=(img_width, img_height), batch_size=batch_size, class_mode='binary')
# 训练模型model.fit_generator( train_generator, steps_per_epoch=nb_train_samples // batch_size, epochs=epochs, validation_data=validation_generator, validation_steps=nb_validation_samples // batch_size)
# 评估模型score = model.evaluate_generator(validation_generator, nb_validation_samples // batch_size)print('Test loss:', score[0])print('Test accuracy:', score[1])
应用场景:广泛应用于自然语言处理、机器翻译、文本生成等诸多领域
Transformer,作为一种基于自注意力机制的神经网络模型,凭借其独特的架构和机制,成为了深度学习领域的璀璨明星。其精妙之处在于由多个编码器和解码器共同构建的基本结构,编码器负责将输入的序列精妙地转换为向量表示,而解码器则负责将这一向量表示巧妙地还原为输出序列。
Transformer的创新之处在于引入了自注意力机制,这一机制赋予了模型捕捉序列中长距离依赖关系的非凡能力。它不再局限于传统的局部信息处理,而是能够洞察全局,把握整体,从而在处理长序列数据时表现出色。
在自然语言处理领域,Transformer以其卓越的性能赢得了广泛的赞誉和应用。无论是机器翻译中的精确翻译,还是文本生成中的流畅表达,Transformer都展现出了令人瞩目的成果。它的出现,无疑为自然语言处理领域的发展注入了新的活力。
经典案例:Transformer进行文本生成的Python代码示例
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# 加载预训练的模型和分词器model_name = "gpt2-medium"tokenizer = GPT2Tokenizer.from_pretrained(model_name)model = GPT2LMHeadModel.from_pretrained(model_name)
# 输入的文本input_text = "The quick brown fox"
# 对输入文本进行编码input_ids = tokenizer.encode(input_text, return_tensors="pt")
# 生成文本generated = model.generate(input_ids, max_length=50, num_return_sequences=1)
# 解码生成的文本output_text = tokenizer.decode(generated[0], skip_special_tokens=True)
print(output_text)
4、BERT(Bidirectional Encoder Representations from Transformers)
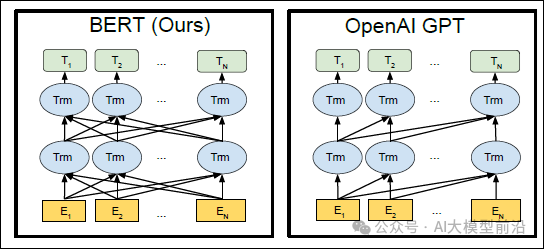
关键技术:双向Transformer编码器与预训练微调技术
处理数据:擅长处理双向上下文信息,为语言理解提供了强大的基础
BERT是一种基于Transformer的预训练语言模型,其最大的创新在于引入了双向Transformer编码器。这一设计使得模型能够综合考虑输入序列的前后上下文信息,极大地提升了语言理解的准确性。通过在海量文本数据上进行预训练,BERT成功地捕捉并学习了丰富的语言知识。随后,只需针对特定任务进行微调,如文本分类、情感分析等,便可轻松实现高效的应用。
BERT在自然语言处理领域取得了显著的成就,并广泛应用于各类NLP任务,成为当前自然语言处理领域的翘楚。
import torchfrom transformers import BertTokenizer, BertForMaskedLM
# 初始化BERT模型和分词器tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')model = BertForMaskedLM.from_pretrained('bert-base-uncased')
# 待生成文本的句子sentence = "BERT is a powerful NLP model that can be used for a wide range of tasks, including text generation. It is based on the Transformer architecture and has been pre-trained on a large corpus of text."
# 对句子进行分词和编码input_ids = torch.tensor([tokenizer.encode(sentence, add_special_tokens=True)])
# 选择需要生成文本的位置,此处我们假设需要生成一个词替换句子中的"[MASK]"masked_index = torch.where(input_ids == tokenizer.mask_token_id)[1]
# 使用BERT模型进行预测outputs = model(input_ids)predictions = outputs[0]
# 获取预测结果中概率最高的词predicted_token = tokenizer.convert_ids_to_tokens(torch.argmax(predictions[0, masked_index], dim=-1).tolist())
# 输出预测结果
print(f"Predicted token: {predicted_token}")
5、GPT(Generative Pre-trained Transformer)

关键技术:单向Transformer编码器与预训练微调技术
GPT,作为一种基于Transformer架构的预训练语言模型,其独特的创新之处在于引入了单向Transformer编码器。这一设计使得模型能够更精准地捕捉输入序列的上下文信息,从而生成更为连贯的文本内容。通过在庞大的文本数据集中进行预训练,GPT积累了丰富而深入的语言知识。之后,在针对特定任务进行微调时,GPT能够展现出强大的适应性和灵活性,如文本生成、摘要提取等。










