摘要:
Source Map很神奇,它的原理挺复杂的…
Fundebug经授权转载,版权归原作者所有。
线上产品代码一般是编译过的,前端的编译处理过程包括不限于
-
转译器/Transpilers (Babel, Traceur)
-
编译器/Compilers (Closure Compiler, TypeScript, CoffeeScript, Dart)
-
压缩/Minifiers (UglifyJS)
这里提及的都是可生成Source Map的操作。
经过这一系列骚气的操作后,发布到线上的代码已经面目全非,对带宽友好了,但对开发者调试并不友好。于是就有了Source Map。顾名思义,他是源码的映射,可以将压缩后的代码再对应回未压缩的源码。使得我们在调试线上产品时,就好像在调试开发环境的代码。
来看一个工作的示例
准备两个测试文件,一个
log.js
里包含一个输出内容到控制台的函数:
function sayHello(name) {
if (name.length > 2) {
name = name.substr(0, 1) + '...'
}
console.log('hello,', name)}
一个
main.js
文件里面对这个方法进行了调用:
sayHello('世界')sayHello('第三世界的人们')
我们使用
uglify-js
将两者合并打包并且压缩。
npm
install uglify-js -g
uglifyjs log.js main.js -o output.js --source-map "url='/output.js.map'"
安装并执行后,我们得到了一个输出文件
output.js
,同时生成了一个Source Map文件
output.js.map
。
output.js
function sayHello(name){if(name.length>2){name=name.substr(0,1)+"..."}console.log("hello,",name)}sayHello("世界");sayHello("第三世界的人们");
output.js.map
{"version":3,
"sources":["log.js","main.js"],"names":["sayHello","name","length","substr","console","log"],"mappings":"AAAA,SAASA,SAASC,MACd,GAAIA,KAAKC,OAAS,EAAG,CACjBD,KAAOA,KAAKE,OAAO,EAAG,GAAK,MAE/BC,QAAQC,IAAI,SAAUJ,MCJ1BD,SAAS,MACTA,SAAS"}
为了能够让Source Map能够被浏览器加载和解析,
再添加一个
index.html
来加载我们生成的这个
output.js
文件。
<html lang="en"><head>
<meta charset="UTF-8">
<meta name=
"viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>source map demotitle>head><body>
Source Mapdemo <script src="output.js">script>body>html>
然后开启一个本地服务器,这里我使用 python 自带的server 工具:
python3 -m http.server
在浏览器中开启Source Map
Source Map在浏览器中默认是关闭的,这样就不会影响正常用户。当我们开启后,浏览器就根据压缩代码中指定的Source Map地址去请求 map 资源。
最后,就可以访问
http://localhost:8000/
来测试我们的代码了。
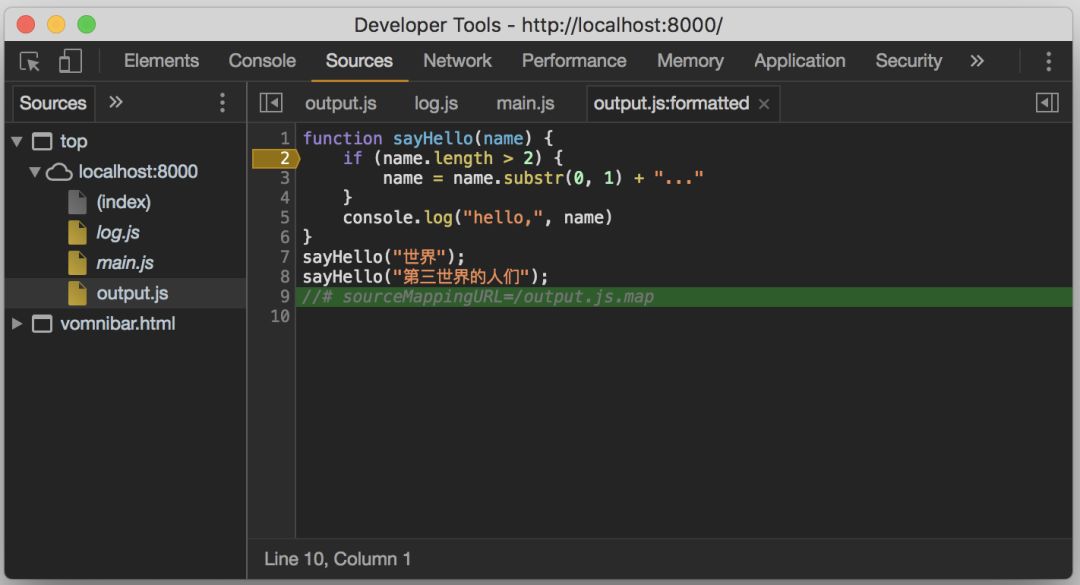
在压缩过的代码中打断点
从截图中可以看到,开启Source Map后,除了页面中引用的
output.js
文件,浏览器还加载了生成它的两个源文件,以方便我们在调试浏览器会自动映射回未压缩合并的源文件。
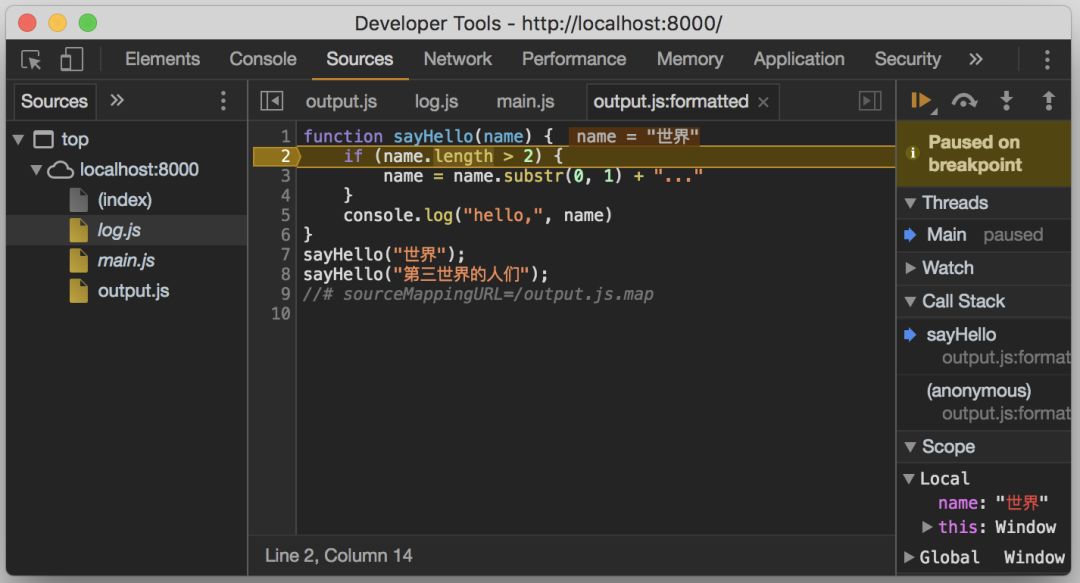
为了测试,我们将 output.js 在调试工具中进行格式化,然后在
sayHello
函数中打一个断点,看它是否能将这个断点的位置还原到这段代码真实所在的文件及位置。
刷新页面后,我们发现,断点正确定位到了
log.js
中正确的位置。
会否觉得很赞啊!
下面我们来了解它的工作原理。
我们所想象的Source Map
将现实中的情况简化一下无非是以下的场景:
输入 ⇒ 处理转换(uglify) ⇒ 输出(js)
上面,输出无疑就是需要发布到产品线上的浏览器能运行的代码。这里只讨论js,所以输出是js代码,当然,其实Source Map也可以运用于其他资源比如LESS/SASS等编译到的CSS。
而Source Map的功能是帮助我们在拿到输出后还原回输入。如果我们自己来实现,应该怎么做。
最直观的想法恐怕是,将生成的文件中每个字符位置对应的原位置保存起来,一一映射。请看来自这篇文章中给出的示例:
“feel the force” ⇒ Yoda ⇒ “the force feel”
一个简单的文本转换输出,其中
Yoda
可以理解为一个转换器。将上面的的输入与输出列成表格可以得出这个转换后输入与输出的对应关系。
|
输出位置
|
输入
|
在输入中的位置
|
字符
|
|
行 1, 列 0
|
Yoda_input.txt
|
行 1, 列 5
|
t
|
|
行 1, 列 1
|
Yoda_input.txt
|
行 1, 列 6
|
h
|
|
行 1, 列 2
|
Yoda_input.txt
|
行 1, 列 7
|
e
|
|
行 1, 列 4
|
Yoda_input.txt
|
行 1, 列 9
|
f
|
|
行 1, 列 5
|
Yoda_input.txt
|
行 1, 列 10
|
o
|
|
行 1, 列 6
|
Yoda_input.txt
|
行 1, 列 11
|
r
|
|
行 1, 列 7
|
Yoda_input.txt
|
行 1, 列 12
|
c
|
|
行 1, 列 8
|
Yoda_input.txt
|
行 1, 列 13
|
e
|
|
行 1, 列 10
|
Yoda_input.txt
|
行 1, 列 0
|
f
|
|
行 1, 列 11
|
Yoda_input.txt
|
行 1, 列 1
|
e
|
|
行 1, 列 12
|
Yoda_input.txt
|
行 1, 列 2
|
e
|
|
行 1, 列 13
|
Yoda_input.txt
|
行 1, 列 3
|
l
|
这里之所以将输入文件也作为映射的必需值,它可以告诉我们从哪里去找源文件。并且,在代码合并时,生成输出文件的源文件不止一个,记录下每处代码来自哪个文件,在还原时也很重要。
上面可以直观看出,生成文件中 (1,0) 位置的字符对应源文件中 (1,5)位置的字符,…
将上面的表格整理记录成一个映射编码看起来会是这样的:
mappings(283 字符):1|0|Yoda_input.txt|1|5, 1|1|Yoda_input.txt|1|6, 1|2|Yoda_input.txt|1|7, 1|4|Yoda_input.txt|1|9, 1|5|Yoda_input.txt|1|10, 1|6|Yoda_input.txt|1|11, 1|7|Yoda_input.txt|1|12, 1|8|Yoda_input.txt|1|13, 1|10|Yoda_input.txt|1|0, 1|11|Yoda_input.txt|1|1, 1|12|Yoda_input.txt|1|2, 1|13|Yoda_input.txt|1|3
这样确实能够将处理后的文件映射回原来的文件,但随着内容的增多,转换规则更加地复杂,这个记录映射的编码将飞速增长。这里源文件
feel the force
才12个字符,而记录他转换的映射就已经达到了283个字符。所以这个编码的方式还有待改进。
省去输出文件中的行号
大多数情况下处理后的文件行数都会少于源文件,特别是 js,使用 UglifyJS 压缩后的文件通常只有一行。基于此,每必要在每条映射中都带上输出文件的行号,转而在这些映射中插入
;
来标识换行,可以节省大量空间。
mappings (245 字符): 0|Yoda_input.txt|1|5, 1|Yoda_input.txt|1|6, 2|Yoda_input.txt|1|7, 4|Yoda_input.txt|1|9, 5|Yoda_input.txt|1|10, 6|Yoda_input.txt|1|11, 7|Yoda_input.txt|1|12, 8|Yoda_input.txt|1|13, 10|Yoda_input.txt|1|0, 11|Yoda_input.txt|1|1, 12|Yoda_input.txt|1|2, 13|Yoda_input.txt|1|3;
可符号化字符的提取
这个例子中,一共有三个单词,拿输出文件中
the
来说,当我们通过它的第一个字母
t
(1,0)确定出对应源文件中的位置(1,5),后面的
he
其实不用再记录映射了,因为
the
可以作为一个整体来看,试想 js 源码中一个变量名,函数名这些都不会被拆开的,所以当我们确定的这个单词首字母的映射关系,那整个单词其实就能还原到原来的位置了。
所以,首先我们将文件中可符号化的字符提取出来,将他们作为整体来处理。
|
序号
|
符号
|
|
0
|
the
|
|
1
|
force
|
|
2
|
feel
|
于是得到一个所有包含所有符号的数组:
names: ['the','force','feel']
在记录时,只需要记录一个索引,还原时通过索引来这个
names
数组中找即可。所以上面映射规则中最后一列本来记录了每个字符,现在改为记录一个单词,而单词我们只记录其在抽取出来的符号数组中的索引。
所以
the
的映射由原来的
0|Yoda_input.txt|1|5, 1|Yoda_input.txt|1|6, 2|Yoda_input.txt|1|7
可以简化为
0|Yoda_input.txt|1|5|0
同时,考虑到代码经常会有合并打包的情况,即输入文件不止一个,所以可以将输入文件抽取一个数组,记录时,只需要记录一个索引,还原的时候再到这个数组中通过索引取出文件的位置及文件名即可。
sources: ['Yoda_input.txt']
所以上面
the
的映射进一步简化为:
0|0|1|5|0
于是我们得到了完整的映射为:
sources: ['Yoda_input.txt']
names: ['the','force','feel']
mappings (31 字符): 0|0|1|5|0, 4|0|1|9|1, 10|0|1|0|2;
记录相对位置
当文件内容巨大时,上面精简后的编码也有可能会因为数字位数的增加而变得很长,同时,处理较大数字总是不如处理较小数字容易和方便。于是考虑将上面记录的这些位置用相对值来记录。比如(1,1001)第一行第999列的符号,如果用相对值,我们就不用每次记录都从0开始数,假如前一个符号位置为 (1,999),那后面这个符号可记录为(0,2),类似这样的相对值帮我们节省了空间,同时降低了数据的维度。
具体到本例中,看看最初的表格中,记录的输出文件中的位置:
|
输出位置
|
输出位置
|
|
行 1, 列 0
|
行 1, 列 0
|
|
行 1, 列 4
|
行 1, 列 (上一值 + 4 = 4)
|
|
行 1, 列 10
|
行 1, 列 (上一值 + 6 = 10)
|
对应到整个表格则是:
|
输出位置
|
输入文件的索引
|
输入的位置
|
符号索引
|
|
行 1, 列 0
|
0
|
行 1, 列 5
|
0
|
|
行 1, 列 +4
|
+0
|
行 1, 列 +4
|
+1
|
|
行 1, 列 +6
|
+0
|
行 1, 列 -9
|
+1
|
然后我们得到的编码为:
sources: ['Yoda_input.txt']
names: ['the','force','feel']
mappings (31 字符): 0|0|1|5|0, 4|0|1|4|1, 6|0|1|-9|1;
注意
-
上面记录相对位置后,我们的数字中出现了负值,所以之后解析Source Map文件看到负值就不会感到奇怪了
-
另外一点我的思考,对于输出位置来说,因为是递增的,相对位置确实有减小数字的作用,但对于输入位置,效果倒未必是这样了。拿上面映射中最后一组来说,原来的值是
10|0|1|0|2
,改成相对值后为
6|0|1|-9|1
。第四位的值即使去掉减号,因为它在源文件中的位置其实是不确定的,这个相对值可以变得很大,原来一位数记录的,完全有可能变成两位甚至三位。不过这种情况应该比较少,它增加的长度比起对于输出位置使用相对记法后节约的长度要小得多,所以总体上来说空间是被节约了的。
VLQ (Variable Length Quantities)
进一步的优化则需要引入一个新的概念了,VLQ(Variable-length quantity)。
VLQ 以数字的方式呈现
如果你想顺序记录4个数字,最简单的办法就是将每个数字用特殊的符号隔开:
1|2|3|4
如果如果提前告诉你这些被记录的数字都是一位的,那这个分隔线就没必要了,只需要简单记录成如下样子也能被正确识别出来:
1234
此时这个记录值的长度是原来的1/2,省了不少空间。
但实际上我们不可能只记录个位数的数字,使用 VLQ 方式时,如果一个数字后面还跟有剩余数字,将其标识出来即可。假设我们想记录如下的四个数字:
1|23|456|7
我们使用下划线来标识一个数字后跟有其他数字:
1234567
所以解读规则为:
VLQ 以二进制方式的方式呈现
上面的示例中,引入了数字系统外的符号来标识一个数字还未结束。在二进制系统中,我们使用6个字节来记录一个数字(可表示至多64个值),用其中一个字节来标识它是否未结束(正文 C 标识),不需要引入额外的符号,再用一位标识正负(下方 S),剩下还有四位用来表示数值。用这样6个字节组成的一组拼起来就可以表示出我们需要的数字串了。
|
B5
|
B4
|
B3
|
B2
|
B1
|
B0
|
|
C
|
Value
|
S
|
|
|
|
第一个字节组(四位作为值)
这样一个字节组可以表示的数字范围为:
|
Binary group
|
Meaning
|
|
000000
|
0
|
|
000001 *
|
-0
|
|
000010
|
1
|
|
000011
|
-1
|
|
000100
|
2
|
|
000101
|
-2
|
|
…
|
…
|
|
011110
|
15
|
|
011111
|
-15
|
|
100000
|
未结束的0
|
|
100001
|
未结束的-0
|
|
100010
|
未结束的1
|
|
100011
|
未结束的-1
|
|
…
|
…
|
|
111110
|
未结束的15
|
|
111111
|
未结束的-15
|
* -0 没有实际意义,但技术上它是存在的
任意数字中,第一个字节组中已经标明了该数字的正负,所以后续的字节组中无需再标识,于是可以多出一位来作表示值。
|
B5
|
B4
|
B3
|
B2
|
B1
|
B0
|
|
C
|
Value
|
|









