
原文来源
:arXiv
作者:
Danial Maleki、Soheila Nadalian、Mohammad Mahdi Derakhshani、Mohammad Amin Sadeghi
「雷克世界」编译:嗯~是阿童木呀、EVA
导语:在图像处理中,伪像的去除和图像的压缩是很重要的处理过程。最近,伊朗德黑兰大学(University of Tehran)提出了一种能够执行伪像去除和图像压缩的深度学习网络,实验表明,该技术简单且高效,能够极大地提高伪像去除和图像压缩的性能。
我们提出了一种执行伪像去除和图像压缩的通用技术。对于伪像去除,我们输入一个JPEG图像并尝试去除其压缩伪像。对于压缩,我们输入一个图像并在一个序列中处理其8×8块(block)。对于每个块,我们首先尝试根据之前的块来预测其强度;然后,我们存储关于输入图像的残差。我们的技术重新使用了JPEG的传统压缩和解压缩例程。我们的伪像去除和图像压缩技术都使用相同的深度网络,但它们的训练权重有所不同。我们的技术简单快速,极大地提高了伪像去除和图像压缩的性能。
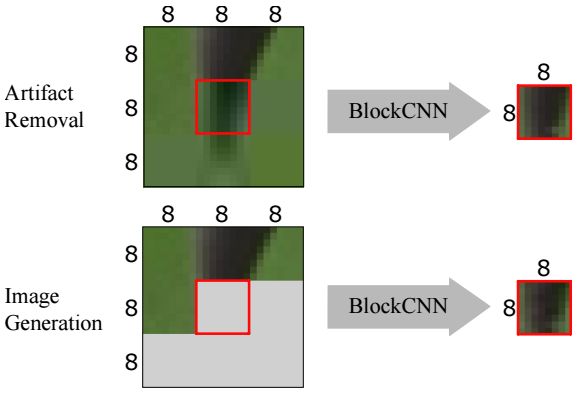
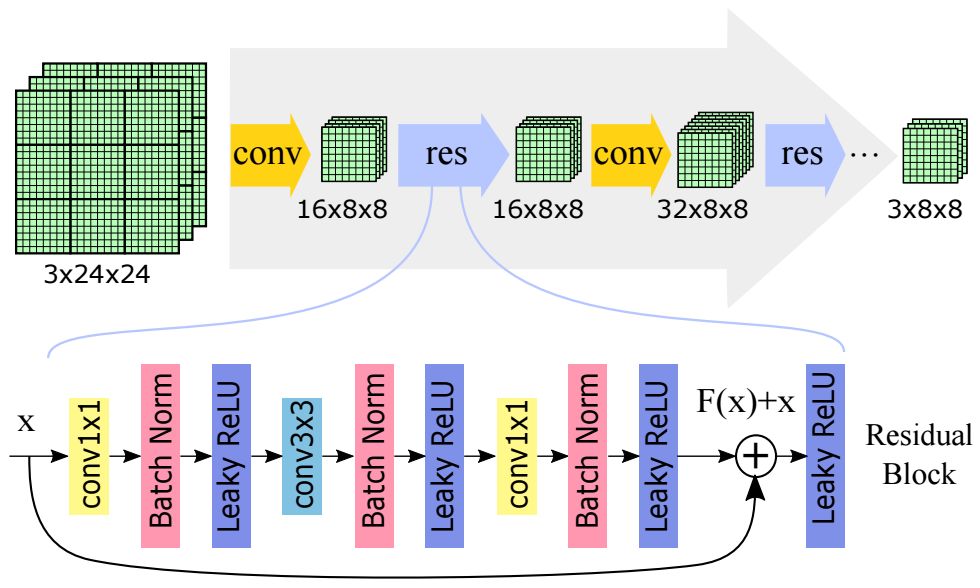
图1:BlockCNN:该体系结构可用于执行伪像去除和图像压缩。BlockCNN在8×8的图像块上运行。顶部:为了从每个块中去除伪像,我们将该块与其八个相邻块一起输入,并尝试从中心块中去除伪像。底部:在给定一个块的四个相邻区域(三个顶部和一个左边)的情况下,这个架构可以预测出该块。我们使用这个图像预测来压缩图像。我们首先尝试预测一个块,然后存储占用较少空间的残差。
深度学习的出现引起了图像表征方面的多重突破,包括:超分辨率、图像压缩、图像增强和图像生成。我们提出了一个统一模型(unified model),它可以执行两项任务:1.JPEG图像的伪像去除;2.新图像的图像压缩。
我们的模型使用深度学习和传统的JPEG压缩例程。JPEG将图像分成8×8块并独立压缩每个块。这会导致块状压缩伪像(图2)。我们发现,像素伪像的统计数据取决于它在块中的位置(图2)。因此,具有关于像素位置先验的伪像去除技术是有优势的。我们的模型在8×8块上运行,以便从先验中获益。此外,这让我们重新使用了JPEG压缩。

图2:左图:JPEG独立压缩每个8×8的块。因此,每个块都有独立的伪像特征。我们的伪像去除技术分别作用于每个块。右图:像素的压缩伪像的统计数据取决于它在8×8块内的位置。右图显示了压缩后的像素强度(块内)的均方差(Mean Square Error)。我们使用了600万张质量因数为20的图像块来生成此图。
对于图像压缩,我们在一个序列中检查图像块。当每个块被压缩时,我们首先尝试根据该块的相邻块来预测该块的图像(图1)。我们的预测有一个关于原始块的残差。我们存储这个残差,该残差比原始块占用的空间更少。我们使用传统的JPEG技术来压缩这个残差。我们可以使用JPEG压缩比对质量和空间进行折中权衡。我们的图像预测是一个确定性过程(deterministic process)。因此,在解压过程中,我们首先尝试预测块的内容,然后将所存储的残差进行累加。在解压缩后,我们执行伪像去除,以进一步提高修复图像的质量。通过这项技术,我们获得了质量和空间之间卓越的折中权衡。
图3:我们的网络架构。顶部:我们输入一张24×24的彩色图像并输出一张8×8的彩色图像。我们的网络有一系列的卷积和残差块。底部:我们的残差块包含多个操作,包括卷积、批量归一化和leaky ReLU激活函数。
相关研究
JPEG使用量化的余弦系数对8×8块进行压缩。JPEG压缩可能会导致不需要的压缩伪像。为此,科学家们开发了若干种技术以减少伪像并对压缩加以改进:
•深度学习
:Jain等人和Zhang等人训练了一个网络来降低高斯噪声(Gaussian noise)。而这个网络不需要知道噪声等级。Dong等人训练了一个网络来减少JPEG压缩伪像。Ball等人采用了非线性分析变换、统一量化器和非线性综合变换。Mao等人开发了一个用于去噪的编码器——解码器网络(encoder-decoder network)。该网络使用跳跃连接和解卷积层。Theis等人提出了一种基于自动编码器的压缩技术。
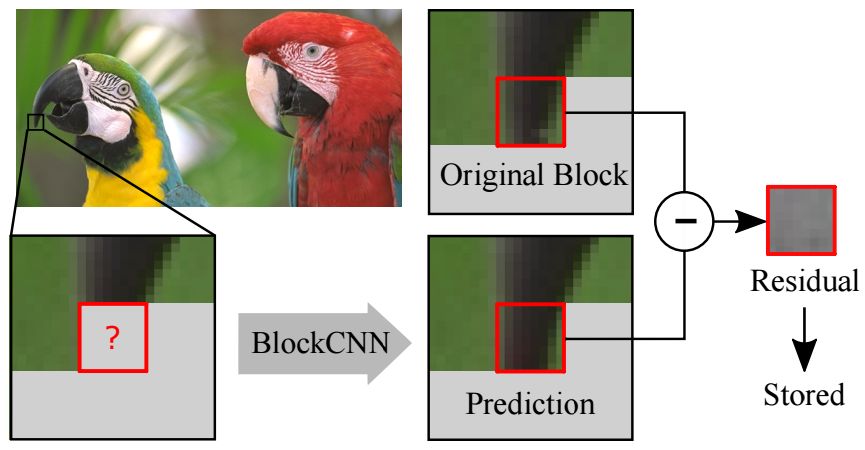
图4:我们的压缩管道。我们在一个序列中对图像块进行处理。对于每个块(用问号突出显示),我们首先尝试使用前面的块对其强度做出预测。然后计算出我们的预测与原始块之间的残差。我们将这个残差进行存储并继续处理下一个块。在解压缩过程中,我们会经历类似的顺序过程。我们首先使用其先前的块对图像块进行预测,然后对残差进行累加。
•基于残差的技术
:Svoboda等人应用残差表征学习来定义一个更容易的网络任务。Baig等人在压缩之前使用图像修补。Dong等人重用预训练模型来加速学习。
•生成式技术
:Santurkar等人使用深度生成式模型来重现图像和视频并去除伪像。在图像生成方面一个较为引人注意的成果是Oord等人提出的PixelCNN。Dahl等人引入了基于PixelCNN的超分辨率技术。而我们的BlockCNN架构也受到了PixelCNN的启发。





