And the Lord spake, saying, "First shalt thou take out the Holy Pin. Then, shalt thou count to three. No more. No less. Three shalt be the number thou shalt count, and the number of the counting shall be three. Four shalt thou not count, nor either count thou two, excepting that thou then proceed to three. Five is right out. Once the number three, being the third number, be reached, then, lobbest thou thy Holy Hand Grenade of Antioch towards thy foe, who, being naughty in My sight, shall snuff it."
上帝说:『首先取下栓,然后不多不少数到三。应该数到三,你数到的数字是三。你除了数到三,既不要数到四,也不要数到二,五是数多了。「三」一旦被数到,成为被数到的第三个数字,就高高的向敌人扔出安提拉之神圣手榴弹,阿门。』
—— 巨蟒与圣杯 Monty Python and the Holy Grail (1975)
UTF-8的来历
UTF-8
的规范里充斥着这样神秘的句子:“
第一个位元组由
110
开始,接着的位元组由
10
开始
”,“
第一个位元组由
1110
开始,接着的位元组由
10
开始
”。
那么这到底是什么意思呢?为什么要这么做呢?
我们先从二进制说起。我们都知道,一个字节是由
8
个二进制位构成的,最小就是
00000000
,最大就是
11111111
。那么一个字节所能表示的最多字符数就是
2
的
8
次方,也就是
256
。对于
26
个英文字母来说,大小写全算上就是
52
个,再加上
10
个阿拉伯数字,
62
个字符,用可以表达
256
个不同字符的一个字节来存储是足够了。
但是,我们中国的常用汉字就有
3000
多个,用一个只能表达
256
个字符的字节显然是不够存储的。至少也需要有
2
个字节,
1
个字节是
8
个二进制位,
2
个字节就是
16
个二进制位,最多可以表达
2
的
16
次方,也就是
256*256=65536
。
65536
个字符足够容纳所有中国的汉字,外带日语、韩语、阿拉伯语、稀其古怪语等等各种各样的字符。所以这样就产生了
Unicode
,因为它用
2
字节表示字符,所以更严格来讲应该叫
UCS-2
,后来因为怪字符太多,
2
字节都不够用了,所以又搞出来了一个
4
字节表示的方法,称作
UCS-4
。不过现在对绝大多数人来讲
UCS-2
已经是足够了。
Unicode
本来是一个好东西,用
2
字节表示
65536
种字符,全人类皆大欢喜的事情。但是偏偏有一帮子西洋人,非要认为这个东西是一种浪费,说我们英文就最多只需要
26
个字母就够了,
1
个字节就够了,为什么要浪费
2
字节呢?比如说字母
A
就是
01000001
,这一个字节就够了的东西,你弄
2
字节,非要在前面加
8
个
0
,
0000000001000001
,这不是浪费吗?我们就偏要用
1
字节表示英文。
好吧,我们全人类只好做妥协,规定每个字节,只要看见
0
打头的,就知道这是英文字母,这肯定不是汉字,只有看见
1
开头的,才认为这是汉字。
但是我们汉字用
1
个字节表示不下,那好办,用
2
个
1
开头的字符表示
1
个汉字。这样本来
16
个二进制位,减去
2
个开头的
1
,只剩下
14
个二进制位了,
2
的
14
次方就是
16384
个字符,对于中文来讲,也是足够用了。但是无奈他们还是想表达
65536
种字符,那怎么办呢?就需要
3
个字节才能容纳得下了,于是
UTF-8
粉墨登场。
首先,首位为
0
的字符被占了,只要遇到
0
开头的字符,就知道这是一个
1
字节的字符,不必再往后数了,直接拿来用就可以,最多表示
128
种字符,从
00000000
到
01111111
,也就是从
0
到
127
。
接下来的事情就比较蹊跷了。我们怎么用
1
开头的字符既表示
2
字节,又表示
3
字节呢?假设我们只判断首位的
1
,这显然是不行的,没有办法区分,所以我们可以用
10
或者
11
开头的字符来表示
2
字节,但是
3
字节又该以什么开头?或者可以用
10
开头表示
2
字节,用
11
开头表示
3
字节?那么
4
字节的字符将来又该怎么办?也许我们可以用
110
开头表示
3
字节,用
111
开头表示
4
字节?那么
5
字节
6
字节呢?似乎我们看到了一个规律:前面的
1
越多,代表字节数越多。
这时候,看一下我们的第一种方案:用
10
开头表示
2
字节,那么我们的一个字符将是
10xx xxxx 10xx xxxx
用
110
表示
3
字节,那么一个
3
字节的字符将是:
110x xxxx 110x xxxx 110x xxxx
这样无疑是能区分得开的。但是
4
字节怎么办?
1110 xxxx 1110 xxxx 1110 xxxx 1110 xxxx
吗?这样也能区分开,但似乎有点浪费。因为每个字节的前半扇都被无用的位占满了,真正有意义的只有后面一半。
或者我们干脆这样做得了,我们来设计方案二:为了节省起见,所有后面的字符,我们统统都以
10
开头,只要遇见
10
我们就知道它只是整个字符流的一部分,它肯定不是开头,但是
10
这个开头已经被我们刚刚方案一的
2
字节字符占用了,怎么办?好办,把
2
字节字符的开头从
10
改成
110
,这样它就肯定不会和
10
冲突了。于是
2
字节字符变成
110x xxxx 10xx xxxx
再往后顺推,
3
字节字符变成
1110x xxxx 10xx xxxx 10xx xxxx
4
字节字符变成
1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx
好像比刚才的方案一有所节省呢!并且还带来了额外的好处:如果我没有见到前面的
110
或者
1110
开头的字节,而直接见到了
10
开头的字节,毫无疑问地可以肯定我遇到的不是一个完整字符的开头,我可以直接忽略这个错误的字节,而直接找下一个正确字符的开头。
这个改良之后的方案二就是
UTF-8
!
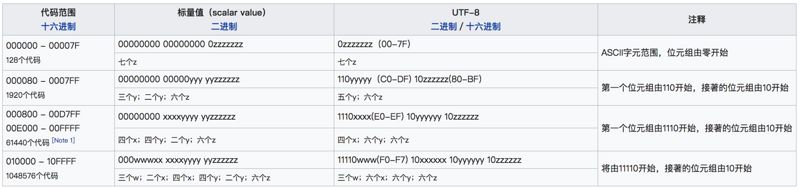
UTF-8表示的字符数
现在,我们来算一下在
UTF-8
方案里,每一种字节可以表示多少种字符。
1
字节的字符,以
0
开头的,
0xxxxxxx
,后面
7
个有效位,
2
的
7
次方,最多可以表示
128
种字符。
2
字节的字符,
110xxxxx10xxxxxx
,数一数,
11
个
x
,所以是
2
的
11
次方,
2









