有问题,不要怕!点击推文底部“
阅读原文
”下载爬虫俱乐部用户问题登记表并按要求填写后发送至邮箱
[email protected]
,我们会及时为您解答哟~
BosonNLP
是玻森中文语义开放平台推出的一款产品,采用将分词和词性标注联合枚举的方法,实现了这一套分词和词性标注系统,并通过开放
API
接口的形式提供给其他开发者使用。
官网是
http://bosonnlp.com/
。

在上一篇推文
爬虫神器"curl
"
中,我们介绍了命令行工具“
curl
”,包括
-o
的用法。除了
-o
,今天的推文中还会涉及到
curl
的如下常见用法:
 -X
:指定命令。HTTP协议的请求主要使用“
GET
”和“
POST
”两种方法,
BosonNLP
需要用到“
POST
”。
-X
:指定命令。HTTP协议的请求主要使用“
GET
”和“
POST
”两种方法,
BosonNLP
需要用到“
POST
”。
-H
:自定义头信息传递给服务器,就整个网络资源传输而言,包括
message-header
和
message-body
两部分,首先传递message-header,即http header消息。
-d
:以
HTTP POST
方式传送数据。

在正式开始前,我们首先需要注册
Boson
账号:

完成后,我们可以在控制台的底部看到自己的
API Token
(密钥),该密钥将用于身份验证:


clear
cap mkdir E:/分词与情感分析
cd E:/分词与情感分析
local text = "爬虫俱乐部将于2017年10月5-7日在武汉举行一期Stata编程技术定制培训。这次课程我们专门增加了Stata15新增功能以及我们团队编写的自动输出实证结果的多个命令的介绍!"
//这是我们要进行分词的文本
! curl -X POST
///使用POST方式请求,向Web服务器发送数据让Web服务器进行处理
-H "Content-Type: application/json"
///Content-Type表示返回数据的类型和字符编码格式,BosonNLP的返回内容为 JSON 格式,因此 Content-Type 是 application/json
-H "Accept: application/json"
///Accept指定客户端能够接收的内容类型
-H "X-Token: ZheLiShiMiYao"
///输入自己注册时获得的API Token(密钥)用于身份验证,这里的密钥是我们伪造的,记得换成自己的密钥哦
--data "\"`=ustrtohex("`text'")'\""
///
以
HTTP POST方式传送数据,使用ustrtohex()函数将文本内容转为unicode编码
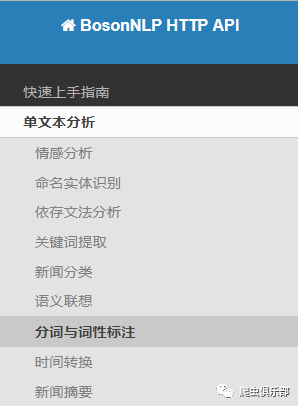
"http://api.bosonnlp.com/tag/analysis?space_mode=1&oov_level=3&t2s=0"
/// 网址则复制“开发者”-“分词与词性标注”页面上的URL(如下图所示)
-o 分词结果.txt
//将输出写到“分词结果.txt”文件中


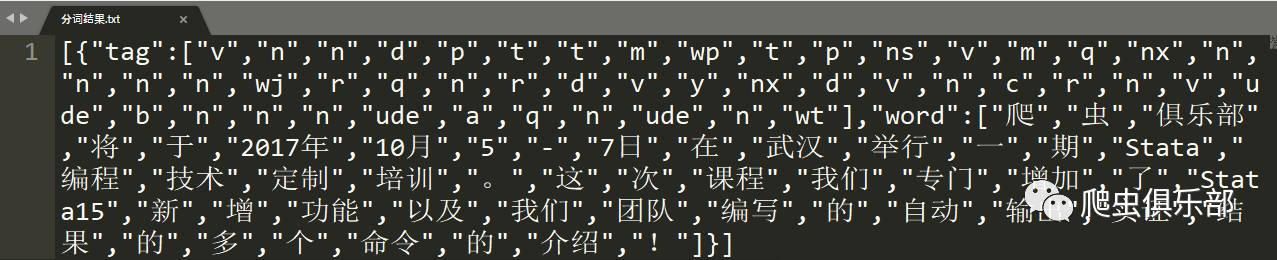
shellout 分词结果.txt
//打开“分词结果.txt”
import delimited using 分词结果.txt, clear encoding("utf8") ///
varnames(nonames) delimiter("asdfghjkl", asstring)
split v1, p(`","word":"')
//以,"word":为分隔符将词性标签与词分开
drop v1
//删除v1
sxpose, clear
//转置

rename _var1 v
//重命名_var1为v
replace v = ustrregexra(v, `"(\[\{"tag":\[")|("\]\}\])|("\])|(\[")"', "")
//将第一个观测值开头的[{"tag":["和第二个观测值结尾的"]}]、第一个观测值结尾的"]和第二个观测值开头的["替换为空,\表示转义
split v, p(`"",""')
//以","为分隔符,将每个词性和每个词都分开
drop v
//删除v

sxpose, clear
//转置
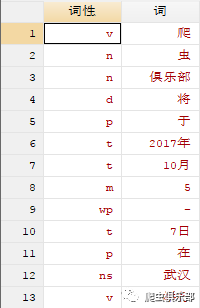
rename _* (词性 词)
//将变量名重命名为“词性”和“词”
这样,我们用stata调用curl使用BosonNLP的API所进行的分词就完成啦。没看懂记得戳下方视频学习哦!
注:此推文中的图片及封面(除操作部分的)均来源于网络!如有雷同纯属巧合!
以上就是今天给大家分享的内容了,说得好就赏个铜板呗!有钱的捧个钱场,有人的捧个人场~。
另外,我们开通了苹果手机打赏通道,只要扫描下方的二维码,就可以打赏啦!

应广大粉丝要求,爬虫俱乐部的推文公众号打赏功能可以开发票啦,累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫。第一批发票已经寄到各位小主的手中,大家快来给小爬虫打赏呀~










