引言:
京东,作为国内最大的自营式电商平台,拥有海量的用户,每时每刻产生海量的全链路流量信息。数据,是一种新颖的财富资源,不但可以进行实时数据分析,为采销和商家提供多维度的实时流量、销售等统计信息,帮助其进行及时调整销售或者运营策略来适应市场的动态变化;同时,可以进行机器学习从海量的数据中挖掘隐藏的内部规律和信息,实现个性化推荐,实时为每位访客推荐所喜欢的商品、店铺或者其他信息。
本文,基于京东海量的全链路数据,简明扼要的分享自己京东成都研究院JSHOP部门在实时数据统计分析以及数据挖掘方面的经验。
大数据
大数据的主要特征为5V,如下图所示:
JSHOP数据分析和挖掘整体框架图
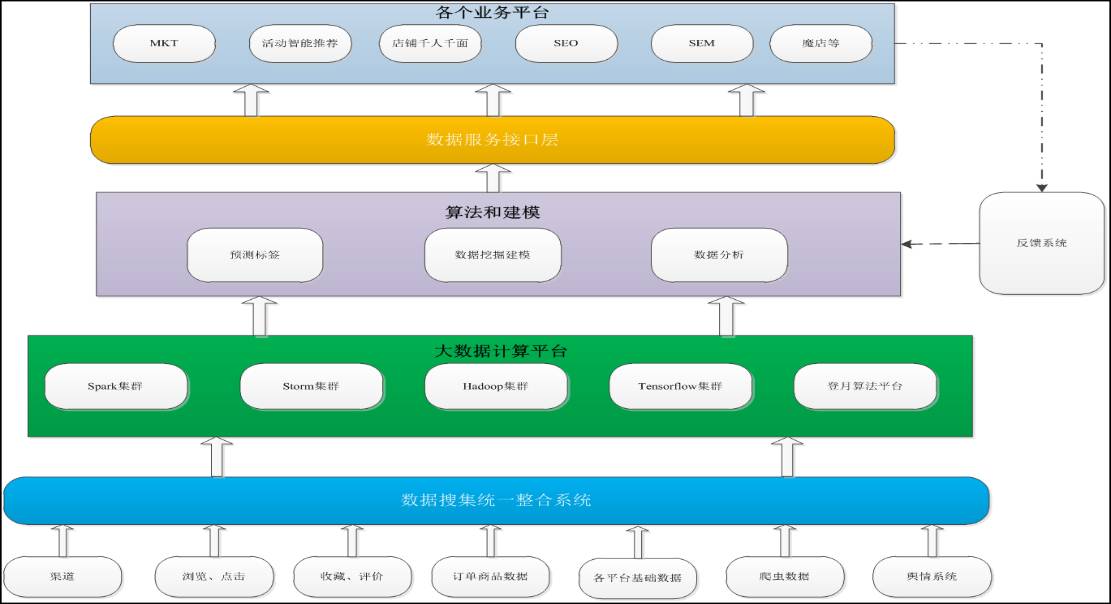 JSHOP部门的数据分析和数据挖掘平台的整体框架如上图所示,主要分为5层+1辅助系统,分别如下:
JSHOP部门的数据分析和数据挖掘平台的整体框架如上图所示,主要分为5层+1辅助系统,分别如下:
数据搜集统一整合系统:主要负责搜集京东整个供应链的数据信息,包括各个渠道数据、用户行为数据(网站浏览、点击、收藏、评价、加入购物车、删除购物车、下单、取消订单等)、平台基础数据、外部爬虫数据、舆情系统数据等,将其存储落地到京东大数据仓库中,统一管理。
大数据计算平台:主要包括Spark集群、Hadoop集群、Storm集群、Tensorflow集群和登月算法平台等,以平台的方式提供。
算法和建模层:主要利用大数据仓库中离线数据和Kafka存储的实时数据,利用上述的计算平台,选择、改造以及创新设计出适应特定场景的模型。
数据服务接口层:利用HIVE或者SPARK等脚本编写数据分析算法,按照topic进行建模统计数据,存入数据库(MYSQL或者HBASE等),以JSF接口或者HTTP前端接口的形式提供给各个业务平台。
业务平台:各个业务系统,包括活动系统、店铺系统、SEM等业务系统,作为消费端接入上述的数据服务,不用关系底层的算法和实现原理。
反馈系统:主要负责搜集访客对推荐结果的反应情况,利用反馈数据调整模型,适应线上的实时变化。
JSHOP数据分析整体流程图
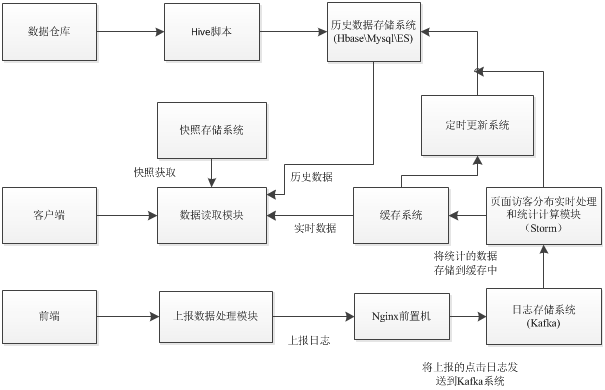 JSHOP数据分析整体流程图如上图所示,主要分为离线数据分析和实时数据分析两类。实时数据分析,前端埋点(多种方式)实时上报用户日志数据到日志存储系统(主要为KAFKA)中,然后利用实时计算框架STORM或者SPARK STREAMING来统计计算各种数据(PV\UV\直接订单\间接订单\排行信息\人员分布\地域分布信息等),将其存储到缓存REDIS中,以便实时获取。离线数据分析,主要编写HIVE脚本或者SPARK SQL等脚本来统计计算各种TOPIC的长期离线数据,存储到HBASE中,以便读取。
JSHOP数据分析整体流程图如上图所示,主要分为离线数据分析和实时数据分析两类。实时数据分析,前端埋点(多种方式)实时上报用户日志数据到日志存储系统(主要为KAFKA)中,然后利用实时计算框架STORM或者SPARK STREAMING来统计计算各种数据(PV\UV\直接订单\间接订单\排行信息\人员分布\地域分布信息等),将其存储到缓存REDIS中,以便实时获取。离线数据分析,主要编写HIVE脚本或者SPARK SQL等脚本来统计计算各种TOPIC的长期离线数据,存储到HBASE中,以便读取。
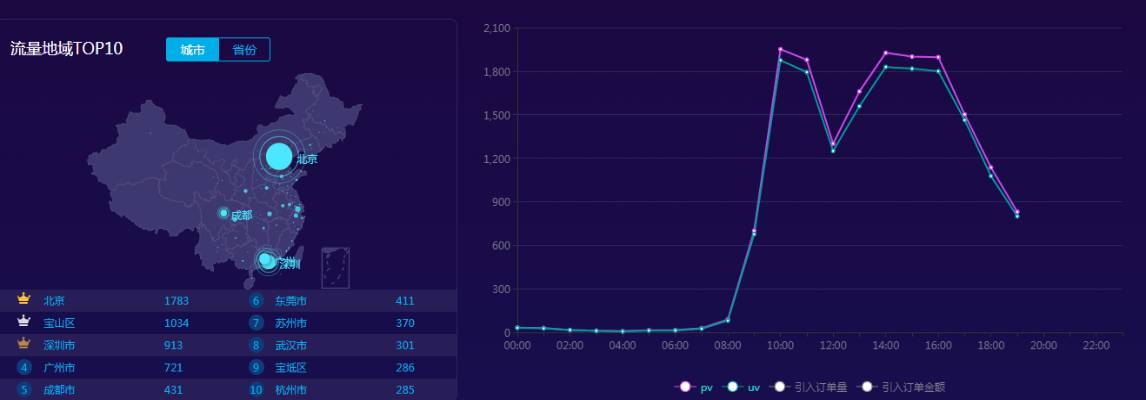
数据分析产品-实时数据监控系统部分截图
数据分析实战1-活动UV统计计算
场景描述:
十万量级别的活动系统,几亿左右的活跃用户,每个活动有几十或者上百个坑位,每个坑位可以有多个换品,统计计算每个活动每个坑位的实时访客数。
方案:利用基数估计算法HyperLogLog Counting
HyperLogLog Counting(以下简称HLLC)的基本思想也是在LLC的基础上做改进。
HLLC使用调和平均数替代几何平均数;LLC取得是几何平均数。由于几何平均数对于离群值特别敏感,因此当存在离群值时,LLC的偏差就会很大。
调和平均数的定义如下:
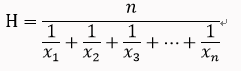
算术平均数:

HLLC比LLC具有更高的精度。对于分桶数m为2^13(8k字节)时,LLC的标准误差为1.4%,而HLLC为1.1%。
优点:无论用户多少,都占用12K的大小存储容量,方便后期扩展应用。
数据分析实战2-注意力热力图
数据分析产品-注意力热力图部分截图
注意力热力图,是热力图的一种,它将访问者对页面中不同的区域的关注程度以热力图的形式展现出来。注意力热力图以不同的颜色和颜色深浅代表不同大小的热度值,热度值大的区域的颜色会较深,热度值小的区域的颜色会较浅。注意力热力图能够非常直观的展示出网页的各个区域被关注的程度(在屏幕中被显示的时间长短),能够帮助网页装修人员优化页面内容,提高转化率。
对于每条日志数据,根据停留时间t1计算整体热度值totalvalue,计算公式如下:
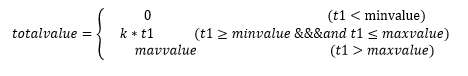
设置动态指数函数,计算公式如下:
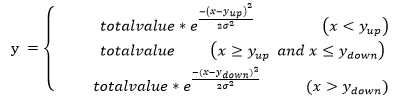
其中,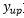 为距离上边缘1/4屏宽的纵坐标;
为距离上边缘1/4屏宽的纵坐标;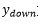 为距离下边缘1/4屏宽的纵坐标;x为上步骤的中间点集合中的点坐标;y为点坐标所对应的热度值;
为距离下边缘1/4屏宽的纵坐标;x为上步骤的中间点集合中的点坐标;y为点坐标所对应的热度值;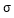 为变化因子,随着屏高变化,其计算公式如下:
为变化因子,随着屏高变化,其计算公式如下:
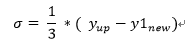
其中,为距离上边缘1/4屏宽的纵坐标;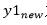 为当前屏的左上角的纵坐标。
为当前屏的左上角的纵坐标。
JSHOP数据挖掘-个性化推荐的整体流程图
JSHOP个性化推荐-聚合页产品整体流程图

聚合页猜你喜欢栏目和我的足迹栏目
个性化推荐-聚合页,是JSHOP部门在数据挖掘领域的第一个产品,主要从品类和品牌两个方面,以活动、店铺和商品为推荐承载物品,进行实时和离线两个时间维度的推荐。算法模型部分,采用的是多模型融合,每个模型推荐部分物品,然后利用排序算法(LR模型、GBDT模型)进行排序,挑选出排名靠前的部分商品,推荐给用户。根据场景的不同将推荐分为判断预测型、猜测预测型、关联型、周期型等,每种场景采用不同的算法进行推荐。根据时效性,将推荐系统分为离线型、近线型和实时型三条线路,根据场景的时效要求使用其中的一种或者多种。
判断预测型,主要根据用户最近一个月的浏览、点击、收藏、关注、购买等行为特征,判断该用户接下3天内会不会购买该商品,主要使用的算法为LR和GBDT算法以及其变种。
猜测预测型,主要根据用户以往的行为(包括浏览、点击、收藏、关注、购买),为用户和所有交互的商品进行打分(代表喜欢程度或者其他意义,分值越大代表意义越深),然后在未交互的商品中预测出可能会购买或者点击的商品列表,主要使用的算法有item-cf、user-cf和ALS模型以及其变种。
关联型,主要根据用户同一天内的购买组合或者加入购物车的商品组合,来判断用户购买一个商品后会购买另外一个商品的可能性,主要使用的算法有FP算法、Apriori算法等。
周期型,主要针对一些周期型比较强的品类商品,用户某个时间点购买了一个商品后,一定周期后还会购买该商品的可能性,主要使用的算法有LSTM算法等。
个性化推荐经验总结:
ALS模型优化:
训练过程数据量大,训练较慢。可以增加并行度\聚类处理等。
识别过程的笛卡儿积问题,识别太慢。Spark mllib中默认采用的分块大小可以适当调整。
Rank值为隐藏因子的个数,可以适当调整,提高模型的表达能力。
Ensemble模型:
• 参数级别的融合
• 模型级别的融合
1. 线性融合(加权、调制)
2. 级联融合(过滤)
3. 算法模型级别融合
离线和在线模型
比如LR模型和FTRL模型
自我简介:
本人毕业于四川大学通信与信息系统专业,有多年声纹识别、语音识别、语音增强、语音编解码等多个领域的研究经验。毕业后进入京东成都研究院JSHOP部门,主要从事于离线和实时数据统计与分析、数据挖掘以及高并发等方面的工作。
如果,大家对海量数据下实时数据统计分析和挖掘技术感兴趣的同学或者同事,可以一起共同探讨。










