搜索引擎的基本数据结构是反向索引,也就是为每个关键词建立了到文档的映射,然后所有的关键词是一个有序列表。
搜索的时候,只要先从有序列表中匹配到关键词,就能搜索到包含该关键词的所有文档,反向索引的数据结构对于关键词搜索的场景是非常高效的。
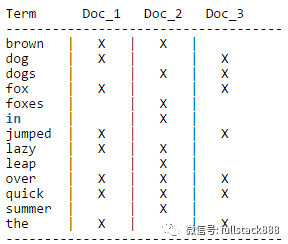
但聚合分析和搜索有很大的不同。典型的场景,比如计算某个文档中每个关键词的出现次数,反向索引就无能为力了,需要先扫描整个关键词映射表,才能找到该文档包含的所有关键词,然后再进行聚合统计(这个例子其实不太准确,因为Lucene在反向索引中冗余了词频的信息,用于计算搜索相关度),也就是要对整个反向索引做全扫描,在数据量大的时候,性能当然好不到哪里去。
所以,Elasticsearch为聚合计算引入了名为fielddata的数据结构,其实就是根据反向索引再次反向出来的一个正向索引,也就是文档到关键词的映射。因为聚合计算也好,排序也好,通常是针对某些列的,实际上生成的是文档到field的多个列式索引,所以叫做fielddata。

这样对文档内的关键词做聚合计算的时候,就只要从fielddata中根据文档ID查找就好。而且,fielddata是保存在内存中的,好处是不占用存储,坏处么,当然上内存不够用啦。而且这个内存是从JVM的Heap上分配的,因为JVM对于大内存的垃圾收集的影响,不能不说对稳定性有很大的挑战,数据量大的时候,时不时的OutOfMemory也不是闹着玩的。因为内存是有限的,所以不可能预先为所有的字段都建立fielddata,只能是由具体的搜索需求来触发。如果是未命中的搜索,还需要先在内存中建立fielddata,这会影响到响应时间。
fielddata的问题在于内存的有限性和JVM对于大内存的垃圾收集对系统带来的稳定性挑战。所以后来又引入了一个新的机制,就是DocValues,从数据结构上来说,它和fielddata是一样的按列的正向索引,但是实现方式不同,DocValues是持久化存储在文件中,并且是预先构建的,也就是数据进入到Elasticsearch时,就会同时生成反向索引和DocValues,这会消耗额外的存储空间,但对于JVM的内存需求会大幅度减少,剩余的内存可以留给操作系统的文件缓存使用。






