编者按:随着AI技术进一步发展,它将与越来越多的传统行业结合。作为新兴技术,AI的人才市场开始出现供不应求,新技术总有一定的壁垒,需要自我学习和用项目实践来掌握。技术的更替常常猝不及防,例如现在的TensorFlow和前两年Spark,刚掌握好能熟练运用Spark了,主流又开始跟进TensorFlow了。技术人需要学习成本,企业项目开发也要考虑新技术采纳时间。有什么办法能在企业已有的大数据平台经验基础上进行AI开发?同程利用Spark对机器学习平台的思考和实现过程值得借鉴。
更多精彩文章请添加微信“AI 前线”(ID:ai-front)
关注人工智能的落地实践,与企业一起探寻 AI 的边界,AICon 全球人工智能技术大会火热售票中,6 折倒计时一周抢票,详情点击:
https://aicon.geekbang.org/?utm_source=wechat&utm_medium=ai-front&utm_campaign=autoreply
人脑具备不断积累经验的能力,依赖经验我们便具备了分析处理的能力,比如我们要去菜场挑一个西瓜,别人或者自己的经验告诉我们色泽青绿、根蒂蜷缩、纹路清晰、敲声浑响的西瓜比较好吃。
我们具备这样的能力,那么机器呢?机器不是只接收指令,处理指令吗?和人脑类似,可以喂给机器历史数据,机器依赖建模算法生成模型,根据模型便可以处新的数据得到未知属性。以下便是机器学习与人脑归纳经验的类别图:
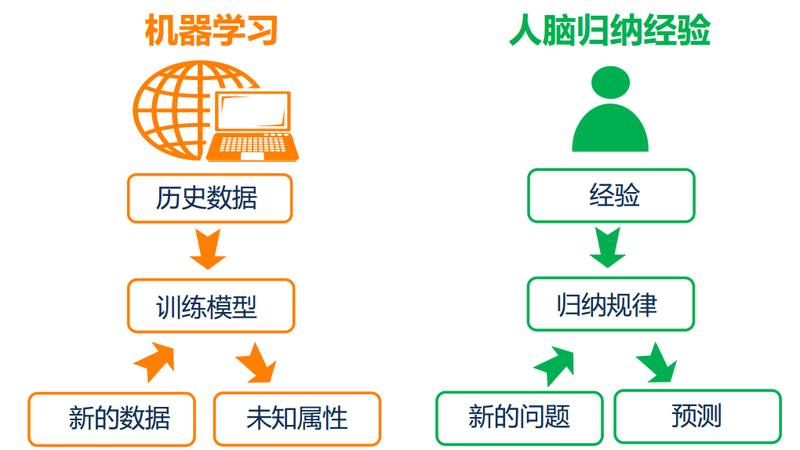
在同程内部,我们对应用机器学习的一些团队做了了解,发现他们普遍的处理步骤如下:

这个过程中存在一些痛点:
因此我们觉得可以构建一套平台化的产品直接对线上数据进行建模实验,节省机器学习的开发成本,降低机器学习的应用门槛。
在算法库方面,我们选择了 Spark,相比于 R 或者 Python,Spark 具备分布式计算的能力,更高效。
ml 和 mllib 都是 Spark 中的机器学习库,目前常用的机器学习功能两个个库都能满足需求。ml 主要操作的是 DataFrame,相比于 mllib 在 RDD 提供的基础操作,ml 在 DataFrame 上的抽象级别更高,数据和操作耦合度更低。
ml 提供 pipeline,和 Python 的 sklearn 一样,可以把很多操作 (算法 / 特征提取 / 特征转换) 以管道的形式串起来,对于任务组合非常便利,如 StringToIndexer、IndexerToString、VectorAssembler 等。
从架构设计上来说,不管是算法单元、特征工程单元、评估单元或者其他工具单元,我们认为都可以以组件的形式来设计。借助通用的接口行为以及不同的实现可以达到松耦合、易扩展的目的。
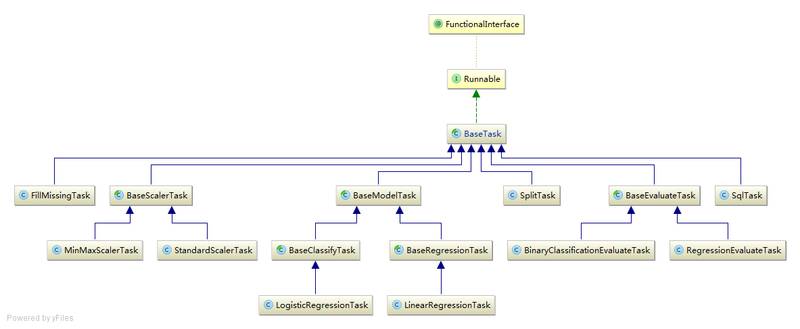
上图是整个设计类图的一部分,实际上我们做了较多层次的抽象以及公用代码。下面看看核心类 BaseTask:

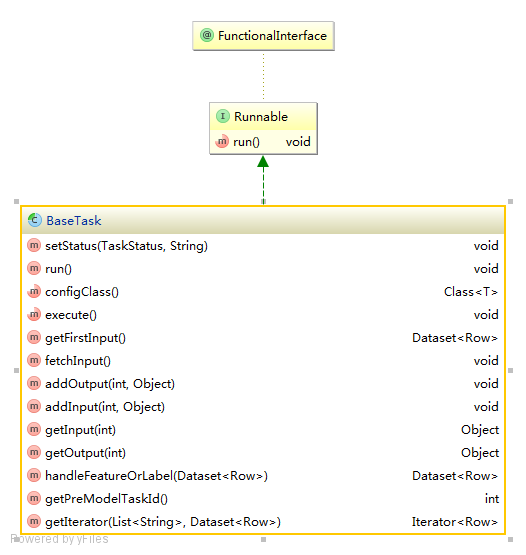
run 方法的实现是一套模板,步骤如下:

每个组件只要实现自己的核心逻辑 execute 方法就可以了。
基于上述的设计目标,机器学习平台第一个版本的架构如下:
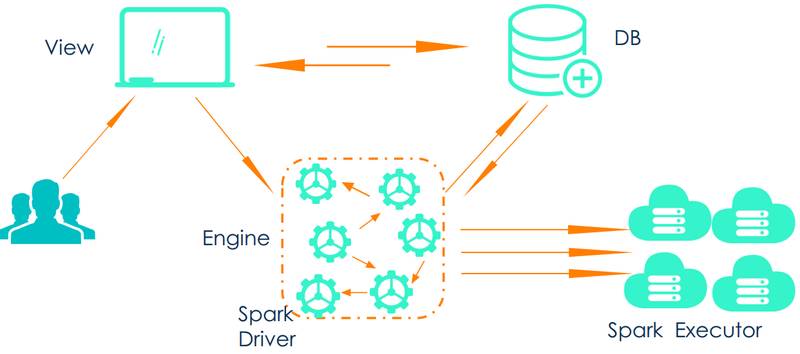
-
用户通过界面拖拽组件构建建模流程,并将组件配置以及依赖关系保存到 DB 中
-
用户可以在界面上触发建模试验的运行,实际上通过 spark-submit 提交一个 spark 任务
-
Ml Engine 负责这个任务的执行,在 Driver 端会从 DB 中获取当前试验的依赖组件以及流程关系。这些组件将依次运行,涉及 RDD 相关的操作时会提交到 Spark Executor 进行并行计算
流程 & 评估视图
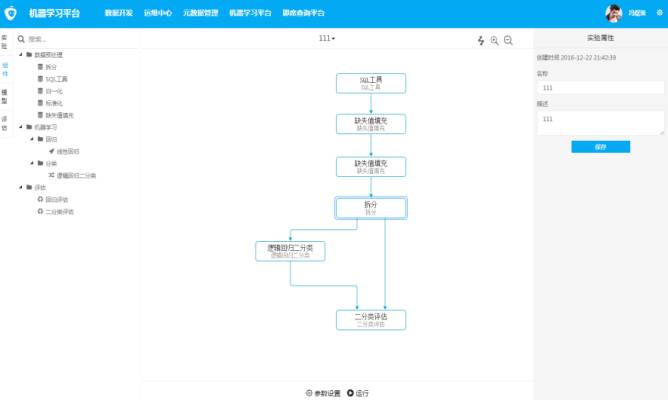

第一个版本我们并没有提供太多的算法组件,只有线性回归和逻辑回归,但是基于组件化的思想,我们非常有信心在后期快速迭代。
除了算法较少外,结合业务反馈与自身思考。我们觉得机器学习平台可以做更多的事:
v2.0(扩充组件 & 离线计算 & 周期性调度)
第二个版本中,我们首先基于原有的设计框架扩充完善了相关实用组件:


同时在第二个版本中,我们在细节上又做了一些完善:
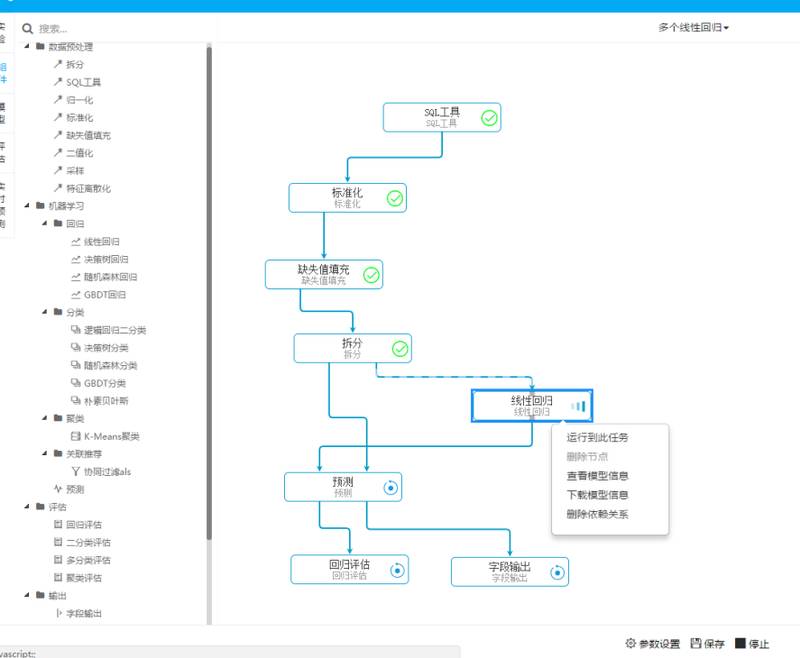
离线计算
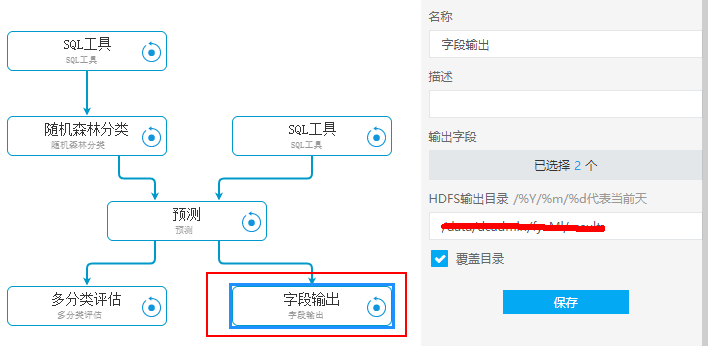
我们提供了‘字段落地’的工具组件,可以将预测结果以 csv 的格式落入 hdfs 中:
周期性调度 & 宏变量支持
我们的另一款产品:大数据开发套件(BDK),函盖周期性调度的功能,机器学习平台的建模实验可以以子任务的形式嵌入其中,结合宏变量(某种规则的语法替换,例如’/%Y/%m/%d’可以表示为当前天等等)用户可以在我们的平台中托管他们的建模试验,从而达到周期性离线计算的目的。
架构
综上,丰富组件及完善功能、离线计算结果落地、结合 BDK 进行周期性离线计算是我们平台第二个版本主要关注的,具体架构有了以下演进:
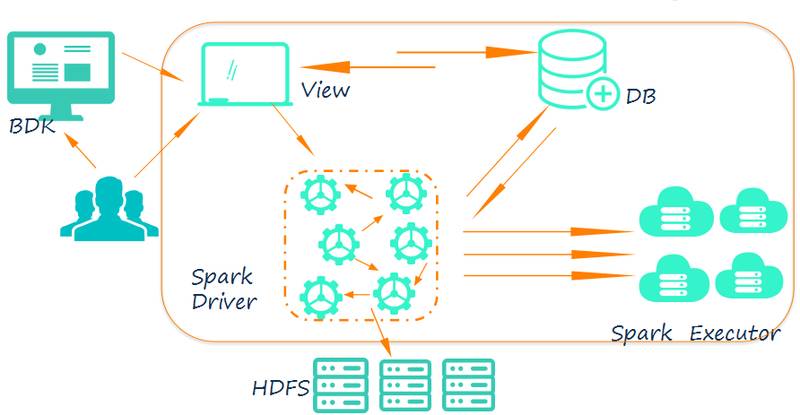
实时预测
在我们的平台中可以通过建模实验训练模型,模型可以通过 PMML 这样的标准导出,同样也可以通过我们的模型导出功能将模型以 parquet 格式保存在 Hdfs 相应的目录上。用户可以得到这些模型标准,自己去实现一些功能。但是我们觉得实时预测的功能在我们平台上也可以抽象出来。于是 3.0 的架构中我们开发了提供实时预测服务的 tcscoring 系统:
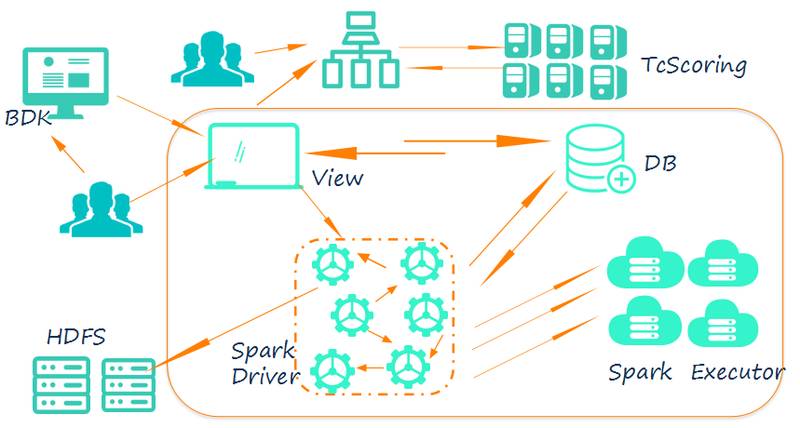
tcscoring 系统的依赖介质就是模型的 PMML 文件,用户可以在机器学习平台上直接部署训练完成了的模型对应的 PMML 文件,或者通过其他路径生成的 PMML 文件。部署成功后会返回用于预测的 rest 接口供业务使用:
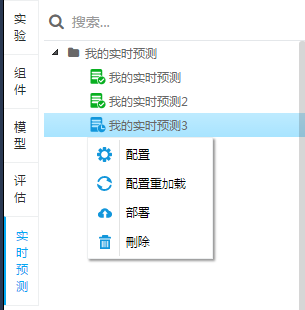
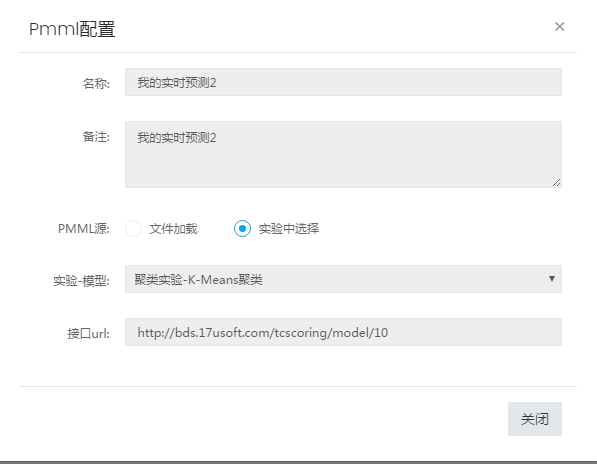
当然,PMML 的部署也可以结合 BDK 设置成周期性调度,这些结合模型的周期性训练,整个训练 + 预测的过程都可以交给机器学习平台 +BDK 实现托管。










