清华大学微电子所李翔宇课题组基于40千赫超声波探测实现了复杂三维手势的识别系统,识别性能不受光照影响,适合于可穿戴设备的人机交互;
提出的特征对齐的随机森林识别算法可以容忍样本间的时间偏差,提升了算法的跨用户识别率。
━━
━━
从机械设备、电子设备等“机器”出现开始,
人与机器如何进行交互的问题就产生了,人机交互的方式则随着设备功能与样式的演进而不断变革。
手机、平板电脑等移动设备的出现,使得计算机的输入设备从鼠标时代进入了触摸屏时代,人机交互更加自然。
而当我们步入万物互联的物联网时代时,我们所拥有或需要操控的计算机设备变得无处不在且形态各异——穿戴在身上的智能手表、增强现实(AR)眼镜、身边的智能家电、汽车驾驶舱中的各种功能系统……一块局促的、必须准确地接触特定位置的触摸屏经常无法提供良好的操控体验。
我们需要新的人机交互技术,来适应新的设备形态和更高的体验要求。
手势交互,
特别是非接触的手势交互,就是一种有吸引力的人机交互方式:用户通过手部的动作来表达操控指令。手势是人类与生俱来的自然交互方式之一,手势交互能够最大限度地减少认知成本。由于不需要与设备发生接触,手势交互对设备尺寸和距离的要求被大大放宽,在不宜接触设备的场景(如手上沾有油污)下,它使得用户仍然能够操控设备。它也不需要视觉辅助调整手的位置,可以摆脱操作界面朝向的束缚,比如在驾驶车辆时,驾驶员可以不用把视线离开路面就能播放音乐、接通电话。因此,手势交互可以在可穿戴设备、虚拟现实(VR)和增强现实(AR)、智能家居、汽车中控等很多新型应用中带给人们更加自然、随意的交互体验,成为了近年来人机交互技术领域研究的重要方向。
手势交互的主要挑战是如何让机器理解人的手势,即手势识别问题。
手势识别作为实现手势交互的核心技术,目前主流的实现技术是基于机器视觉的方案,即采用摄像头采集人手的静态和运动图像,通过视觉算法提取出手的形状、位置信息,然后辨别对应的手势。
但是计算机视觉技术的识别效果严重依赖于采集的图像质量,因此在暗光、强光、存在烟雾、遮挡的情况下无法使用。
利用雷达技术获取手势信息是另一类新的手势识别技术。
雷达向探测空间主动发射调制的探测波,探测波照射到物体表面后发生散射,经过散射的波一部分返回到雷达装置,被雷达的接收器接收,成为回波。
散射波传播的距离会对应波的相位变化,目标的径向运动会引起回波的频率变化(多普勒效应),雷达算法通过提取回波的相位、频率变化信息就能够获得目标的距离和速度信息。
基于雷达的手势识别技术就是通过对手运动过程中的雷达回波的特征分析来识别手势的。
目前手势识别雷达有两种方案:
电磁波探测和超声波探测。
雷达方案与机器视觉方案相比不仅不受光照条件的限制,而且采集的数据量小,系统功耗更低、体积更小。
与计算机视觉方案擅长识别静态手势不同,雷达方案更擅长识别动态(运动的)手势。
超声波雷达和电磁波雷达原理相似,但是由于同样波长的超声波的频率要比电磁波低6个数量级,因此超声波雷达收发电路可以在几十到几百千赫的频率下工作,电路设计难度和工作功耗都大大低于电磁波雷达(电磁波雷达通常需要几十千兆赫的毫米波波段)。
超声波与电磁波相比的另一优点是它和无线通信设备之间不会互相干扰。
无论是电磁波还是超声波的手势识别,
其关键难点都在于识别算法,为了支持更加丰富的手势、减轻用户的疲劳感,研究表明手指的小幅运动是最为理想的近距离操控手势,我们将这种以手的形变动作为主要信号的手势称为“微手势”。微手势涉及手部多个关节的运动,此时,人手被看作一种做复杂不规则变形的非刚体目标。雷达回波信号不能像视频信号那样直观反映手势信息,微手势采用传统的基于规则的方式难以识别,而借助机器学习技术我们就可以为每种预定义的手势建立一个识别模型,基于从回波中提取的特征,根据训练得到的模型,自动完成手势分类。此外,由于可穿戴设备通常电池容量有限,为了保证足够的待机时间和响应速度,手势识别算法的计算不能过于复杂;从应用场景来看,要求用户提供手势样本、参与识别模型的训练并不现实,因此,识别算法还要具有足够高的跨用户识别准确率,也就是说基于其他人群的手势数据训练得到的模型可以准确识别没有参加训练的用户的手势。这些问题和要求对手势识别算法的研究提出了挑战。
近年来,清华大学微电子学研究所的李翔宇副研究员课题组围绕基于超声波的手势识别技术开展研究,并在系统设计和跨用户识别算法方面取得了进展。
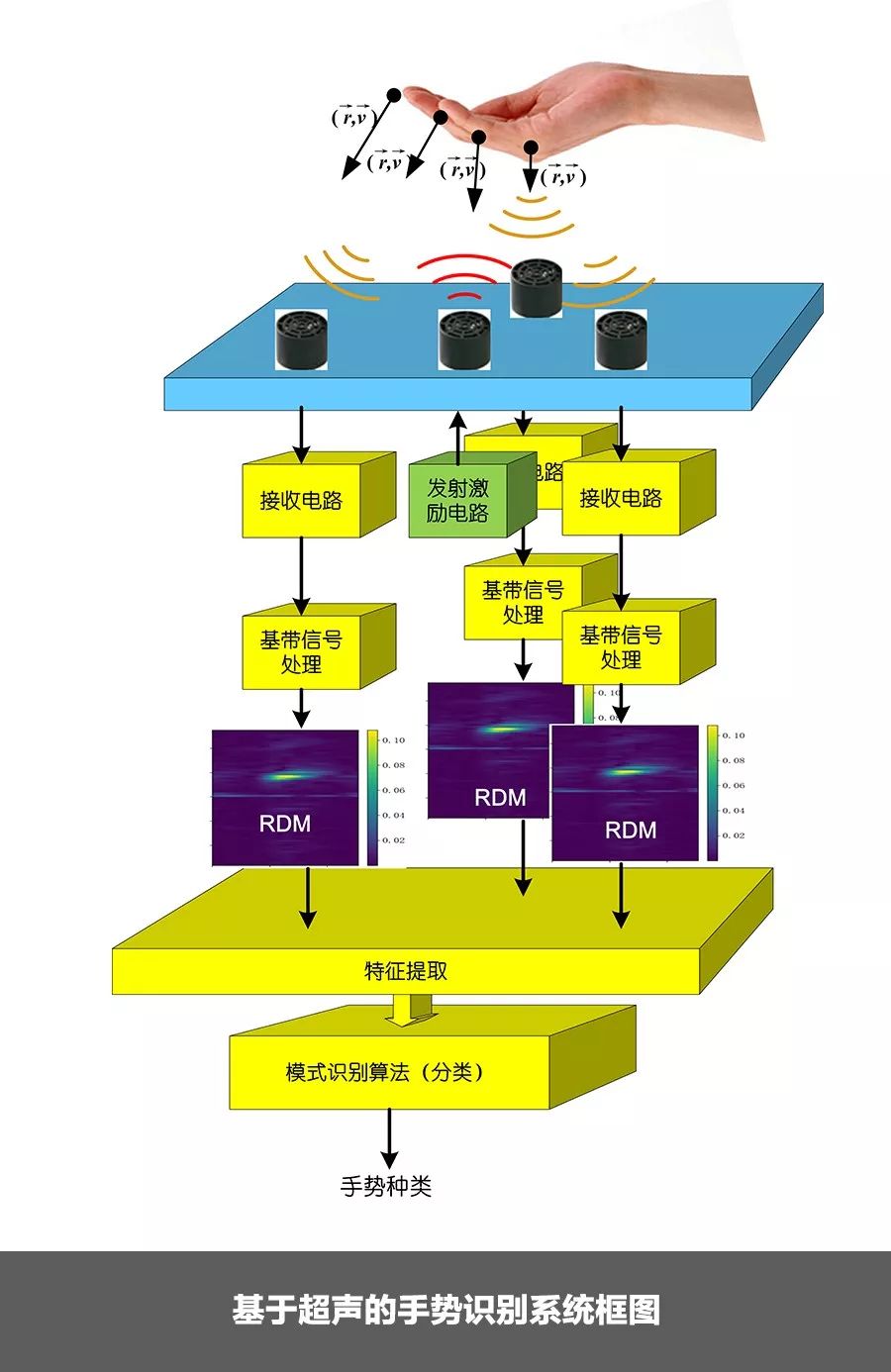
课题组搭建了一个可以进行3D微手势识别的原型系统(见下图),为了能够识别手的各个维度的运动,这一系统采用了一个发射器和3个“品”形排列的接收器。
下图给出了用于测试系统性能的8种手势的照片。
为了扩大操作范围,课题组选用了宽照射角度的40千赫的超声波换能器。
利用超声波频率低的优点,该系统的收发机用数字信号直接作为激励信号,采用数字解调方式,简化了系统的硬件设计。
该系统把手势目标看成由多个运动的散射中心组成的非刚体目标,回波信号则是每个散射中心回波信号的叠加。
因此,经过解调后的3路回波信号首先要经过预处理转化成距离-多普勒图像(RDM),这种图像能够反映回波能量在不同径向距离和径向速度上的分布。
不同时刻采样测量得到的RDM组成一组帧序列,就是用于识别的原始数据。
课题组没有采用常规的深度卷积神经网络(DCNN)的识别算法,而是采用了经典的基于特征的模式识别算法——随机森林算法。
这种算法与深度卷积神经网络相比具有低得多的计算复杂度和模型规模,更节省功耗,更加适用于可穿戴设备这样的轻量级系统。
识别算法首先从3路RDM帧序列中提取出一系列特征,组成特征向量,然后输入到随机森林中进行训练或分类。
但是传统的随机森林算法在处理序列分类问题时不能很好地处理时间偏差,而在跨用户识别的场景中,由于习惯不同,测试用户的动作可能比训练者的动作快或慢,这样就会导致样本的各帧特征和训练好的模型的帧错位,因此,传统随机森林算法在跨用户识别情况下的识别率并不理想。
无论是采用DCNN还是传统随机森林算法,要解决上述问题都要增加训练样本的来源,扩大样本的方差,这意味着更高的开发成本。
课题组周飞飞、李翔宇等人在2019年的IEEE传感器协会旗舰会议(IEEE SENSORS)上发表的论文Efficiently User-Independent Ultrasonic-Based Gesture Recognition Algorithm中提出了一种特征对齐的随机森林分类器——该分类器在训练和推理时先对样本RDM序列进行对齐,对齐是依据平均速度这一项特征采用动态时间规整(DTW)算法完成的,有效地控制了计算的复杂度,其他特征再根据对齐结果重新融合得到对齐后的特征向量送给二分类随机森林组成的分类器。
实验结果表明,该算法使用6名志愿者的训练数据能够达到93.9%的平均跨用户识别准确率,模型数据量则仅为DCNN算法的7.3%。
此外,
为了提高系统的实用性、降低功耗,课题组还在系统中增加了手势检测算法,可以自动感知到手势动作,继而触发识别计算;在无手靠近的情况下系统会自动转入低功耗模式,关闭识别功能。这既降低了待机功耗,又可以更加准确地截取有效的RDM序列。
现有系统的基带处理部分由FPGA和个人计算机实现,目前课题组正在进行基带部分的硬件和嵌入式系统设计工作,期望未来能够将除传感元件之外的所有功能都集成到一个芯片当中,届时系统的响应速度和功耗将得到大大改善,体积更加小巧,能够植入到可穿戴设备、智能家居中,使得人机交互更加“无拘无束”。
致谢:
感谢深圳市科技计划(基础研究项目)“复杂条件下的雷达手势识别技术研究”(项目编号:
JCYJ20180306170414910)的支持。
本文刊登于IEEE Spectrum中文版《科技纵览》2019年9月刊。










