主要观点总结
该文章主要介绍了一个或许对你有用的社群和开源项目,提供了包括面试交流、项目实战、源码学习等资源。同时指出,对信息应确认后传播,避免误导大众。最后介绍了知识星球的加入方式和内容。
关键观点总结
关键观点1: 社群介绍与资源提供
文章介绍了一个社群,该社群提供包括一对一交流、面试小册、简历优化、求职解惑等资源,并推荐了一些有用的资料和学习指南。
关键观点2: 开源项目的介绍与功能
文章介绍了一个开源项目,包括其前端和后端架构,以及支持的功能,如RBAC权限、SaaS多租户等。
关键观点3: 关于模型训练信息的解读与讨论
文章对一条关于模型训练的新闻进行了解读和讨论,指出其中的误解和真实情况,并对论文进行了解读。
关键观点4: 网络环境的影响与呼吁
文章指出国内网络环境的浮躁和对信息的误传问题,呼吁大家在看到信息时要思考确认,不要盲目传播误导大众。
关键观点5: 知识星球的加入方式和内容
文章介绍了知识星球的加入方式和内容,包括项目实战、面试招聘、源码解析、学习路线等。
正文
👉
这是一个或许对你有用
的社群
🐱
一对一交流/面试小册/简历优化/求职解惑,欢迎加入
「
芋道快速开发平台
」
知识星球。
下面是星球提供的部分资料:
👉
这是一个或许对你有用的开源项目
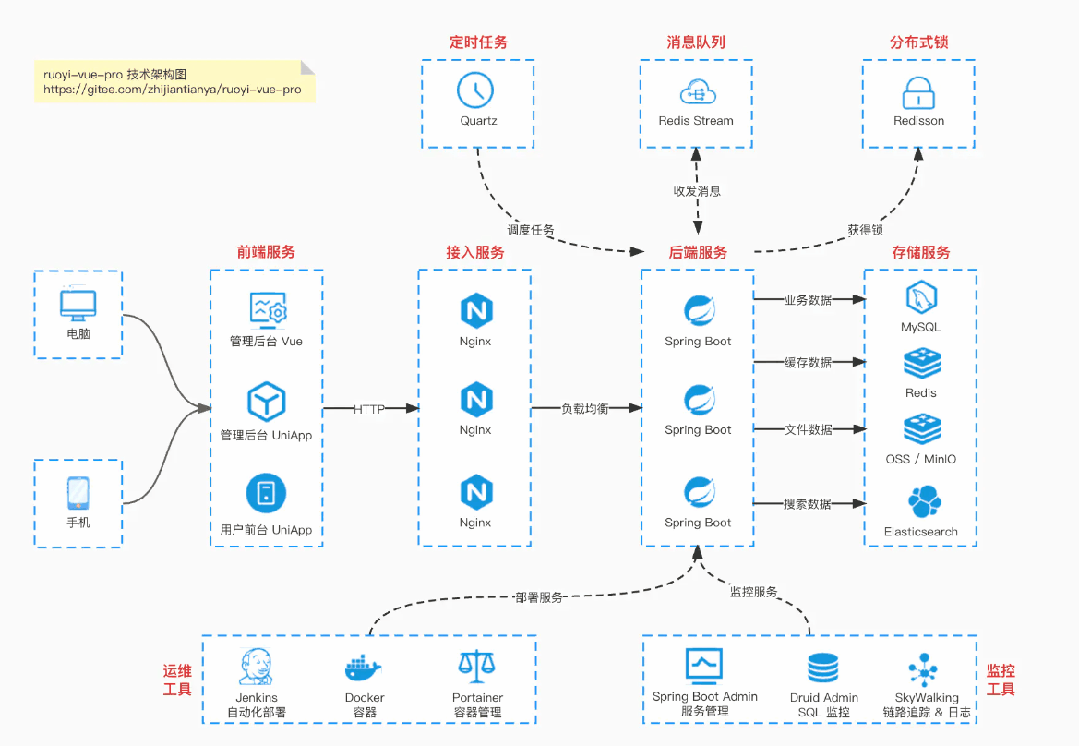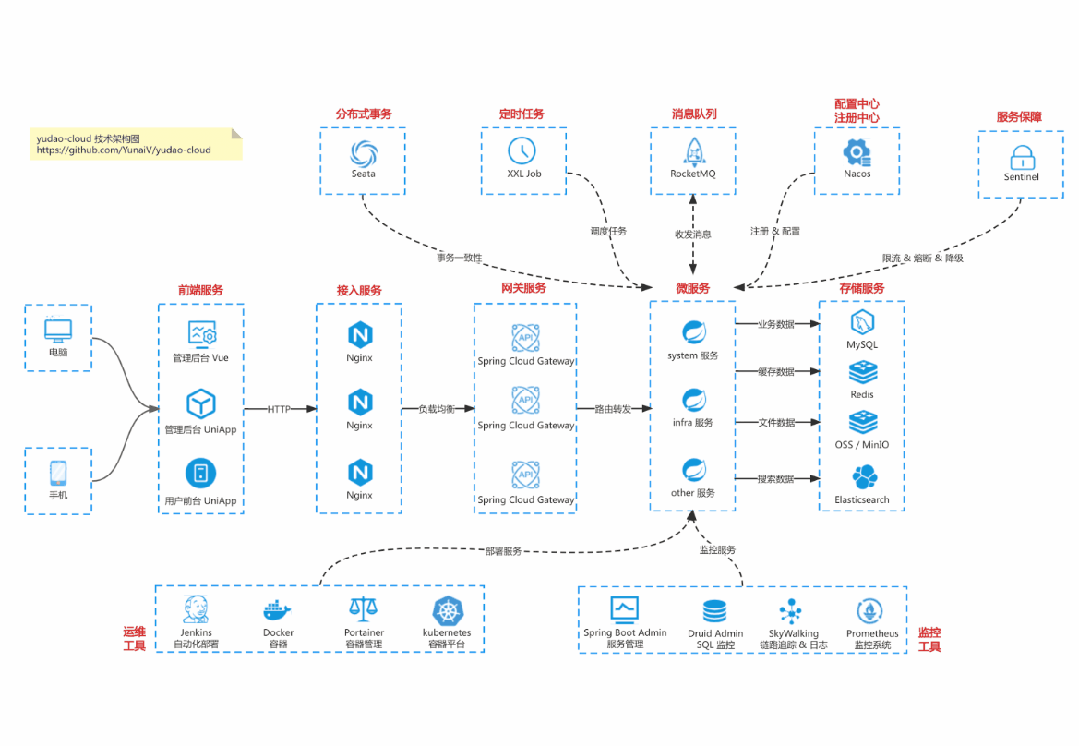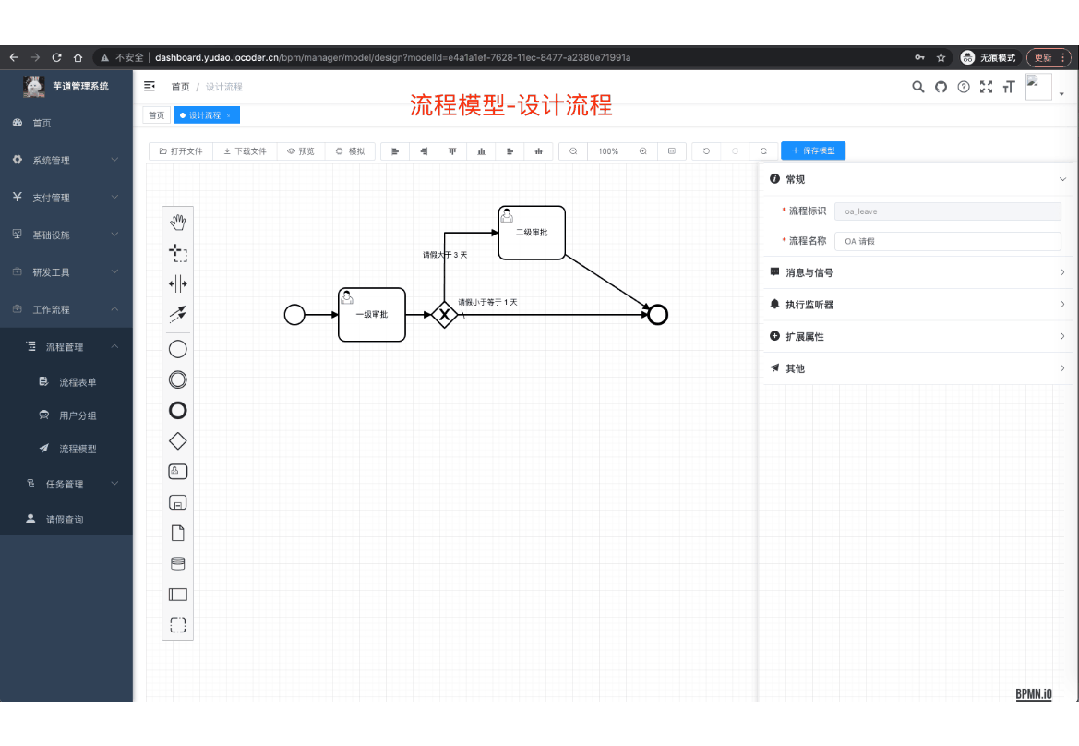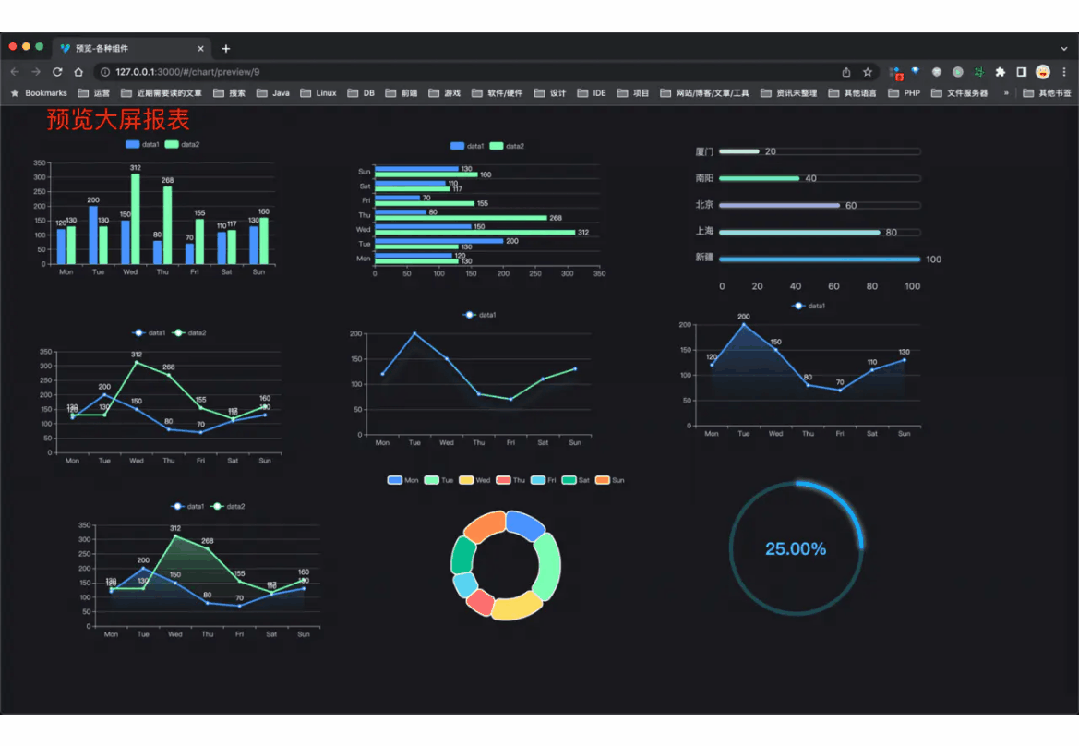
国产 Star 破 10w+ 的开源项目,前端包括管理后台 + 微信小程序,后端支持单体和微服务架构。
功能涵盖 RBAC 权限、SaaS 多租户、数据权限、
商城
、支付、工作流、大屏报表、微信公众号、
ERP
、
CRM
、
AI 大模型
等等功能:
-
Boot 多模块架构:https://gitee.com/zhijiantianya/ruoyi-vue-pro
-
Cloud 微服务架构:https://gitee.com/zhijiantianya/yudao-cloud
-
视频教程:https://doc.iocoder.cn
【国内首批】支持 JDK 17/21 + SpringBoot 3.3、JDK 8/11 + Spring Boot 2.7 双版本
今天下午简直被这条新闻刷屏了,"震惊",“李飞飞”,“50美元”,“Deep Seek R1",这几个词连到一起,简直是掀了Open AI和英伟达的桌子,即便是蒸馏出来的模型,那这么低的成本,OpenAI花了几十、几百亿美元做出来的模型,被轻松复制,那OpenAI的估值不得打个骨折?

我就赶紧看了下论文:
https://arxiv.org/html/2501.19393v1
Github:
https://github.com/simplescaling/s1

结果发现并不是那么回事。
首先这个50美元咋来的?因为论文中提到用了16块H100 GPU,而且只花了26min,如果是租服务器的话,确实也就是几十美元。

但问题是,论文中并不是训练出了DeepSeek R1!
论文的核心内容是基于开源的Qwen2.5 - 32B模型,该模型是蒸馏出来的模型,32B只能算是中等参数模型,作为本次实验对比的R1和o1都是大几千亿参数的模型。用小数据集进行监督微调,而且微调后的参数数量跟之前基本保持一致,然后在特定任务上把性能优化了,而这些任务的性能表现可以媲美DeepSeek R1和OpenAI o1。
怎么经过中文博主翻译过来后,就成了50美元蒸馏出了DeepSeek R1?
以下的论文的解读(使用豆包解读):
-
研究背景与目标
:语言模型性能提升多依赖训练时计算资源扩展,测试时缩放是新范式,OpenAI 的 o1 模型展示了其潜力,但方法未公开。本文旨在探寻实现测试时缩放和强推理性能的最简方法。
-
-
初始数据收集
:依据质量、难度和多样性原则,从 16 个来源收集 59,029 个问题,涵盖现有数据集整理和新的定量推理数据集创建,用 Google Gemini Flash Thinking API 生成推理轨迹和解决方案,并进行去重和去污染处理。
-
最终样本选择
:经质量、难度和多样性三步筛选得到 1,000 个样本的 s1K 数据集。质量筛选去除 API 错误和低质量样本;难度筛选依据两个模型的性能和推理轨迹长度排除过易问题;多样性筛选按数学学科分类,从不同领域采样,且倾向选择推理轨迹长的样本。
-
方法分类与提出
:将测试时缩放方法分为顺序和并行两类,重点研究顺序缩放。提出预算强制(Budget forcing)方法,通过强制设定思考令牌的最大或最小数量,控制模型思考时间,引导模型检查答案、修正推理步骤。
-
基准对比
:将预算强制与条件长度控制方法(令牌条件控制、步骤条件控制、类别条件控制)和拒绝采样进行对比。使用控制(Control)、缩放(Scaling)和性能(Performance)三个指标评估,结果表明预算强制在控制、缩放和最终性能上表现最佳。
-
实验设置
:用 s1K 对 Qwen2.5-32B-Instruct 进行监督微调得到 s1-32B 模型,在 AIME24、MATH500 和 GPQA Diamond 三个推理基准上评估,并与 OpenAI o1 系列、DeepSeek r1 系列等模型对比。
-
性能表现
:s1-32B 在测试时缩放中,性能随测试时计算资源增加而提升,在 AIME24 上超过 o1-preview 达 27%,且是最具样本效率的开源数据推理模型,接近 Gemini 2.0 在 AIME24 上的性能,验证了蒸馏过程的有效性。
-
数据相关
:测试数据质量、多样性和难度组合的重要性。随机选择(仅质量)、仅多样性选择、仅难度选择(选最长推理轨迹样本)的数据集性能均不如 s1K,训练 59K 全量样本虽性能强但资源消耗大,证明 s1K 构建方法的有效性。
-
测试时缩放方法
:预算强制在 AIME24 测试中控制完美、缩放良好、得分最高,“Wait” 作为扩展性能的字符串效果最佳。令牌条件控制在无预算强制时失败,步骤条件控制下模型可绕过计算约束,类别条件控制虽能提升性能但综合表现不如预算强制,拒绝采样呈现反向缩放趋势。
-
样本高效推理
:众多研究致力于复制 o1 性能,本文通过 1,000 样本监督微调结合预算强制,构建出有竞争力的模型,推测预训练使模型具备推理能力,微调激活该能力。同时,介绍了相关基准和方法的发展情况。










