经过前面几次推文的学习,相信大家对R语言已经有了一个大概的了解,同时也初步感受了R语言在数据处理领域的强大功能,不过实话实说,前面的内容还只是R语言应用的冰山一角而已。从这次推文开始,我们就要正式开始接触R语言对数据处理的强大能力。
在正文内容开始之前,我先给大家推荐一个文档
https://google.github.io/styleguide/Rguide.xml
相信很多同学在前几次推文的指导下,练习R代码编写的时候会发现,R语言和其他编程语言不太一样的地方,比如:
赋值符
,两者我该用哪个?同时,有些操作符前后有空格,有些又没有,到底该怎么写才对?除此之外,R语言的换行和缩进似乎也不像python那么严格。那我们平时自己写代码的时候应该遵循什么样的规则呢?
上面提到的这个文档就可以解答大家的这些疑问。这个文档是
Google’s R Style Guide
,众所周知,医生在临床上工作有临床指南,那程序员工作也有“指南”,上面的这个文档就是我们写R代码的指南。具体我这里不展开来讲,希望大家好好看看,务必遵守!!!
话不多说,我们进入这次课程的主要内容,上节课中完成了R语言中的数据导入工作,那么这次课程的主要内容就是给大家介绍一些数据管理和操作的基本函数或语句。
1、本节内容重点内容较多,
务必紧跟
红色标记
。
2、测试数据及代码
见
文末客服小姐姐
二维码。
一般来说,创建新变量是项目中必不可少的步骤。举个例子,有一个数据框mydata,其中有两列变量x1,x2。现在要求创建两个新的变量x3,x4,其中x3是变量x1,x2的加和,x4是x1,x2的均值。下面有三个实现方式的示例:

图
1:
创建新变量的三种方式。
第一种方法是通过
赋值操作
在数据框mydata中生成新的两列;第二种方法是通过
attach函数
加载mydata,赋值生成新的两列数据,再detach取消加载mydata数据框;第三种方法是通过
transform函数
把数据列合并在一起。大家可以根据自己的习惯来选择其中一种方法实现(跟大家讲个悄悄话:我喜欢
第一种方法
,直接明了)。同时我们也跟大家讲一下R里面的常用运算符:加(+)、减(-)、乘(*)、除(/)、求幂(^或者**)、求余(%%)、整数除法(%/%,如5%/%2=2)。
变量的重命名很好理解,变量的重编码的含义是根据一个或者一组变量的现有值创建新值的过程,比如,项目中要求将错误的数据改为准确值、将学生的百分制成绩改为等级制成绩等等。这个过程中
逻辑运算
发挥了很重要的作用。说到逻辑运算,就是对
TRUE和FALSE两个逻辑变量
的运算,逻辑运算符包括
&(与)、| (或)、!(非)三种。
我们以如图2中的一组数据来进行示范。
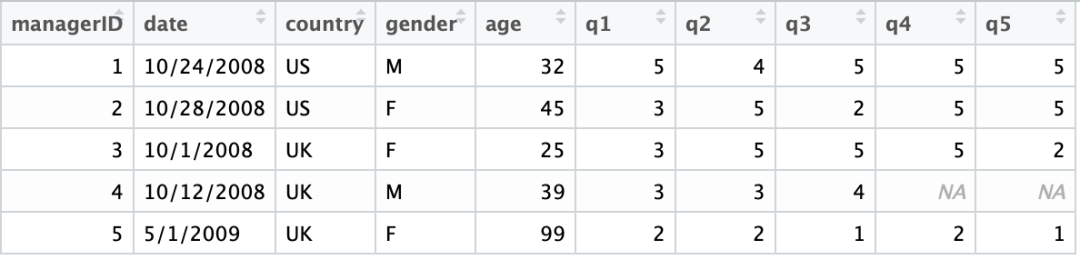
图
2:
示例数据
首先我们把age=99的数据改为缺失数据,然后将age重编码为等级制变量agecat,代码如图3。

图
3:
变量的重编码
这样我们发现处理完之后数据有了变化:
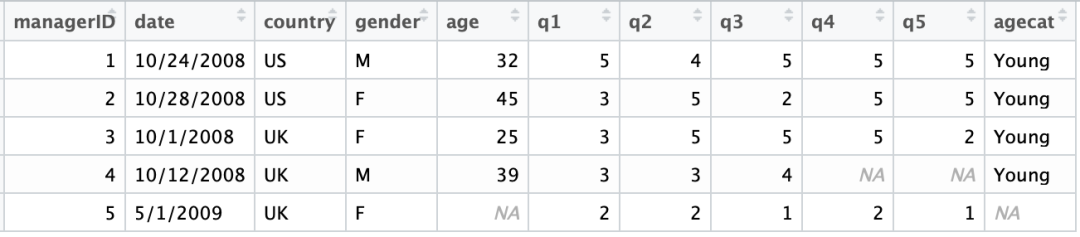
图
4
:注意最后一列
agecat
。
实际上变量重编码是一个很复杂的问题,绝不仅仅是像上面两步操作那么简单的。其中,car包中的recode()和doBy包中的recodevar()、R语言中自带的cut(),这三个函数都是很受欢迎的变量重编码函数。
相比于重编码,重命名就不那么神秘了,通过
names()
函数可以更改数据框的行名和列名。下面给大家举几个变量重命名的方法,大家可以自己动手试一下,感受一下这三个语句的效果。

图
5:
变量重命名的方法。
*plyr包是一个集合了很多数据集操作函数的R包,大家可以查看其帮助文档进一步学习。
几乎所有项目中,都存在缺失值,在R中缺失值用NA代替(前面我们已经见过了)。R语言提供了一个简单而重要的函数
is.na()
来监测数据集中的缺失值。下面是该函数的一个使用实例。
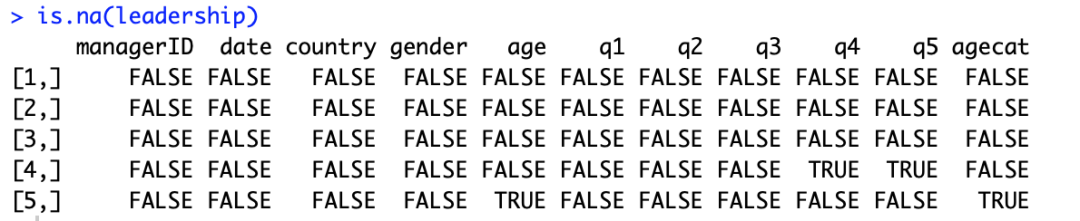
图
6:
使用
is.na()
函数
数据集leadership中缺失值NA的位置都被标记上了TRUE。
这个函数简单在于用法简单易记,重要在于R语言中
不存在
x == NA来判断变量x是否为缺失值的用法!!!值得一提的是,NA只是表示缺失值,和无效运算产生的结果NaN是不一样的。
我们在前面已经实验过了重编码某些值为缺失值的用法,就是将age为99的值标记为缺失值的步骤(如图3)。这一步虽然很简单,但在一些项目中如果遗漏了这个步骤,会对结果产生巨大的影响!
在识别和编码了缺失值之后,我们该怎么处理这些可恶的缺失值呢?缺失值的插补是一个非常复杂的问题,如果你的数据有很大一部分都是缺失值,你或许应该先去问问提供数据的人,为什么会有缺失值。或者,等我们后续课程专门讲解缺失值插补的操作。如果你的数据中只是存在很小一部分缺失值,直接删除这些麻烦的缺失值是一个理想的选择。R语言中提供了函数
na.omit()
来删除带有缺失值的行(如图7)。
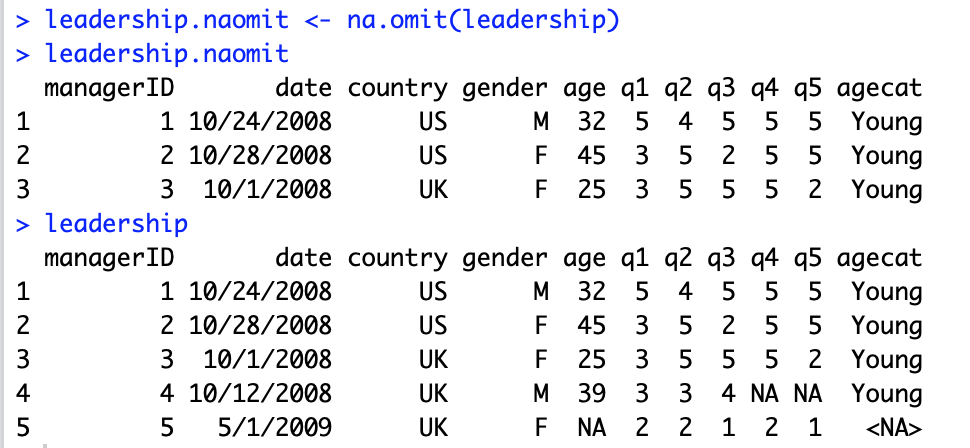
图
7:
函数
na.omit()
的使用。
在R语言中的很多数值函数都有一个na.rm=TRUE的可选参数,比如函数sum()。这个参数可以在计算之前就移除缺失值并使用剩余值计算(如图8)。
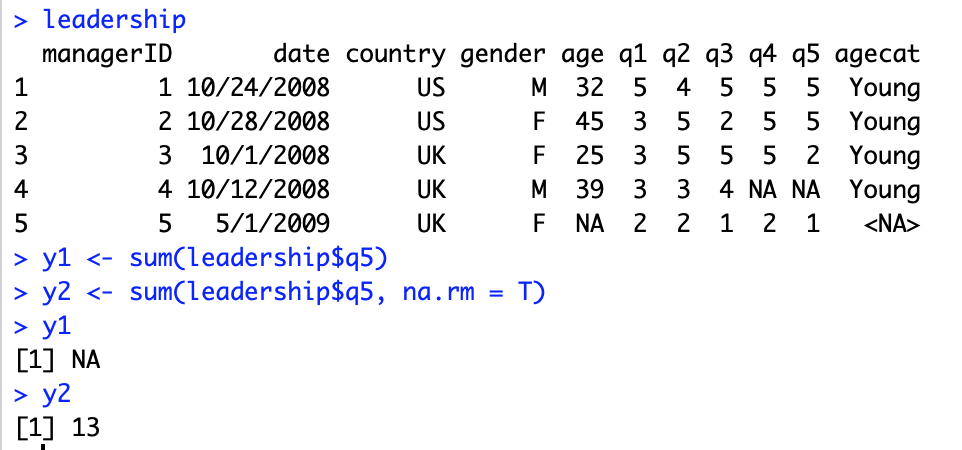
图
8:
函数
sum()
中
na.rm=TRUE










