我们知道,Openvwitch可以创建虚拟交换机,而网络包可以通过虚拟交换机进行转发,并通过流表进行处理,具体的过程如何呢?
一、内核模块Openvswitch.ko的加载
OVS是内核态和用户态配合工作的,所以首先要加载内核态模块Openvswitch.ko。
在datapath/datapath.c中会调用module_init(dp_init);来初始化内核模块。
其中比较重要的是调用了dp_register_genl(),这个就是注册netlink函数,从而用户态进程ovs-vswitchd可以通过netlink调用内核。
这里dp_genl_families由四个netlink的family组成
-
static struct genl_family *dp_genl_families[] = {
-
&dp_datapath_genl_family,
-
&dp_vport_genl_family,
-
&dp_flow_genl_family,
-
&dp_packet_genl_family,
-
};
|
可以看出,在内核中,包含对datapath的操作,例如OVS_DP_CMD_NEW,对虚拟端口vport的操作,例如OVS_VPORT_CMD_NEW,对flow流表的操作,例如OVS_FLOW_CMD_NEW
,
对packet包的操作,例如OVS_PACKET_CMD_EXECUTE。
二、用户态进程ovs-vswitchd的启动
ovs-vswitchd.c的main函数最终会进入一个while循环,在这个无限循环中,里面最重要的两个函数是bridge_run()和netdev_run()。
Openvswitch主要管理两种类型的设备,一个是创建的虚拟网桥,一个是连接到虚拟网桥上的设备。
其中bridge_run就是初始化数据库中已经创建的虚拟网桥。
虚拟网卡的初始化则靠netdev_run()。
bridge_run会调用static void bridge_reconfigure(const struct ovsrec_open_vswitch *ovs_cfg),其中ovs_cfg是从ovsdb-server里面读取出来的配置。
在这个函数里面,对于每一个网桥,将网卡添加进去。
-
HMAP_FOR_EACH (br, node, &all_bridges) {
-
bridge_add_ports(br, &br->wanted_ports);
-
shash_destroy(&br->wanted_ports);
-
}
最终会调用dpif_netlink_port_add__在这个函数里面,会调用netlink的API,命令为OVS_VPORT_CMD_NEW。
三、内核模块监听网卡
ovs-vswitchd启动的时候,将虚拟网卡添加到虚拟交换机上的时候,会调用netlink的OVS_VPORT_CMD_NEW命令,因而会调用函数ovs_vport_cmd_new。
它最终会调用ovs_netdev_link,其中有下面的代码:
-
err = netdev_rx_handler_register(vport->dev, netdev_frame_hook,
-
vport);
|
注册一个方法叫做netdev_frame_hook,每当网卡收到包的时候,就调用这个方法。
四、内核态网络包处理
Openvswitch的内核模块openvswitch.ko会在网卡上注册一个函数netdev_frame_hook,每当有网络包到达网卡的时候,这个函数就会被调用。
-
static struct sk_buff *netdev_frame_hook(struct sk_buff *skb)
-
{
-
if (unlikely(skb->pkt_type == PACKET_LOOPBACK))
-
return skb;
-
-
port_receive(skb);
-
return NULL;
-
}
|
调用port_receive即是调用netdev_port_receive
在这个函数里面,首先声明了变量struct sw_flow_key key;
如果我们看这个key的定义,可见这个key里面是一个大杂烩,数据包里面的几乎任何部分都可以作为key来查找flow表
-
tunnel可以作为key
-
在物理层,in_port即包进入的网口的ID
-
在MAC层,源和目的MAC地址
-
在IP层,源和目的IP地址
-
在传输层,源和目的端口号
-
IPV6
所以,要在内核态匹配流表,首先需要调用ovs_flow_key_extract,从包的正文中提取key的值。
接下来就是要调用ovs_dp_process_packet了。
这个函数首先在内核里面的流表中查找符合key的flow,也即ovs_flow_tbl_lookup_stats,如果找到了,很好说明用户态的流表已经放入内核,则走fast path就可了。于是直接调用ovs_execute_actions,执行这个key对应的action。
如果不能找到,则只好调用ovs_dp_upcall,让用户态去查找流表。会调用static int queue_userspace_packet(struct datapath *dp, struct sk_buff *skb, const struct sw_flow_key *key, const struct dp_upcall_info *upcall_info)
它会调用err = genlmsg_unicast(ovs_dp_get_net(dp), user_skb, upcall_info->portid);通过netlink将消息发送给用户态。在用户态,有线程监听消息,一旦有消息,则触发udpif_upcall_handler。
Slow Path & Fast Path
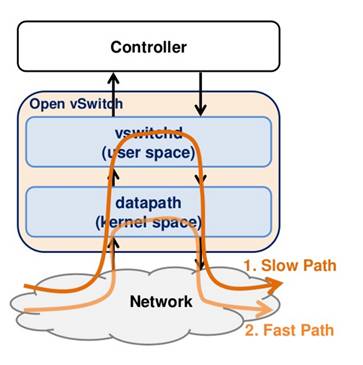
Slow Path:
当Datapath找不到flow rule对packet进行处理时
Vswitchd使用flow rule对packet进行处理。
Fast Path:
将slow path的flow rule放在内核态,对packet进行处理
Unknown Packet Processing
Datapath使用flow rule对packet进行处理,如果没有,则有vswitchd使用flow rule进行处理
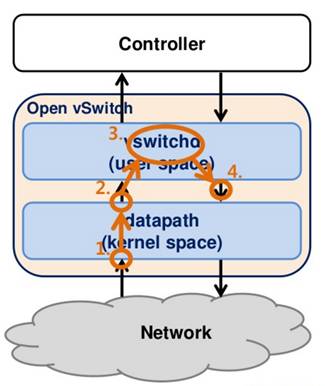
-
从Device接收Packet交给事先注册的event handler进行处理
-
接收Packet后识别是否是unknown packet,是则交由upcall处理
-
vswitchd对unknown packet找到flow rule进行处理
-
将Flow rule发送给datapath
五、用户态处理包
当内核无法查找到流表项的时候,则会通过upcall来调用用户态ovs-vswtichd中的flow table。
会调用ofproto-dpif-upcall.c中的udpif_upcall_handler函数。
(1) 首先读取upcall调用static int upcall_receive(struct upcall *upcall, const struct dpif_backer *backer, const struct dp_packet *packet, enum dpif_upcall_type type, const struct nlattr *userdata, const struct flow *flow, const unsigned int mru, const ovs_u128 *ufid, const unsigned pmd_id)
(2) 其次提取包头调用void flow_extract(struct dp_packet *packet, struct flow *flow),提取出的flow如下:
-
/* L2, Order the same as in the Ethernet header! (64-bit aligned) */
-
struct
eth_addr dl_dst;
/* Ethernet destination address. */
-
struct
eth_addr dl_src;
/* Ethernet source address. */
-
ovs_be16 dl_type;
/* Ethernet frame type. */
-
ovs_be16 vlan_tci;
/* If 802.1Q, TCI | VLAN_CFI; otherwise 0. */
-
ovs_be32 mpls_lse[ROUND_UP(FLOW_MAX_MPLS_LABELS, 2)];
/* MPLS label stack
-
(with padding). */
-
/* L3 (64-bit aligned) */
-
ovs_be32 nw_src;
/* IPv4 source address. */
-
ovs_be32 nw_dst;
/* IPv4 destination address. */
-
struct
in
6_addr ipv6_src;
/* IPv6 source address. */
-
struct
in
6_addr ipv6_dst;
/* IPv6 destination address. */
-
ovs_be32 ipv6_label;
/* IPv6 flow label. */
-
uint
8_t nw_frag;
/* FLOW_FRAG_* flags. */
-
uint
8_t nw_tos;
/* IP ToS (including DSCP and ECN). */
-
uint
8_t nw_ttl;
/* IP TTL/Hop Limit. */
-
uint
8_t nw_proto;
/* IP protocol or low 8 bits of ARP opcode. */
-
struct
in
6_addr nd_target;
/* IPv6 neighbor discovery (ND) target. */
-
struct
eth_addr arp_sha;
/* ARP/ND source hardware address. */
-
struct
eth_addr arp_tha;
/* ARP/ND target hardware address. */
-
ovs_be16 tcp_flags;
/* TCP flags. With L3 to avoid matching L4. */
-
ovs_be16 pad3;
/* Pad to 64 bits. */
-
-
/* L4 (64-bit aligned) */
-
ovs_be16 tp_src;
/* TCP/UDP/SCTP source port/ICMP type. */
-
ovs_be16 tp_dst;
/* TCP/UDP/SCTP destination port/ICMP code. */
-
ovs_be32 igmp_group_ip4;
/* IGMP group IPv4 address.
-
* Keep last for BUILD_ASSERT_DECL below. */
(3) 然后调用static int process_upcall(struct udpif *udpif, struct upcall *upcall, struct ofpbuf *odp_actions, struct flow_wildcards *wc)来处理upcall。
对于MISS_UPCALL,调用static void upcall_xlate(struct udpif *udpif, struct upcall *upcall, struct ofpbuf *odp_actions, struct flow_wildcards *wc)
会调用enum xlate_error xlate_actions(struct xlate_in *xin, struct xlate_out *xout)
在这个函数里面,会在flow table里面查找rule
ctx.rule = rule_dpif_lookup_from_table( ctx.xbridge->ofproto, ctx.tables_version, flow, xin->wc, ctx.xin->resubmit_stats, &ctx.table_id, flow->in_port.ofp_port, true, true);
找到rule之后,调用static void do_xlate_actions(const struct ofpact *ofpacts, size_t ofpacts_len, struct xlate_ctx *ctx)在这个函数里面,根据action的不同,修改flow的内容。
(4) 最后调用static void handle_upcalls(struct udpif *udpif, struct upcall *upcalls, size_t n_upcalls)将flow rule添加到内核中的datapath
他会调用void dpif_operate(struct dpif *dpif, struct dpif_op **ops, size_t n_ops),他会调用dpif->dpif_class->operate(dpif, ops, chunk);
会调用dpif_netlink_operate()
会调用netlink修改内核中datapath的规则。
-
case
DPIF_OP_FLOW_PUT:
-
put = &op->u.flow_put;
-
dpif_netlink_init_flow_put(dpif, put, &flow);
-
if
(put->stats) {
-
flow.nlmsg_flags |= NLM_F_ECHO;
-
aux->txn.reply = &aux->reply;
-
}
-
dpif_netlink_flow_to_ofpbuf(&flow, &aux->request);
-
break
;





