
编辑 | 姗姗
出品 | 人工智能头条(公众号ID:AI_Thinker)
【导读】 ICML ( International Conference on Machine Learning),国际机器学习大会如今已发展为由国际机器学习学会(IMLS)主办的年度机器学习国际顶级会议。今天,第35届 ICML 大会在瑞典的斯德哥尔摩正式召开,与大家一同分享这一领域在这一年里的突破。ICML 2018 共有 2473 篇论文投稿,共有 621 篇论文杀出重围入选获奖名单,接受率接近25%。其中 Google 强势领跑,Deep Mind 、FaceBook和微软也是精彩纷呈;而在高校中 UC Berkeley 和 Stanford 、CMU 以近 30 篇荣登 Top 榜。
而今年不得不说咱们国内的成绩,虽然清华被收录了 12 篇,相比之下还是有差距,不过相比往年的数量和今年如此激烈的竞争下,进步是不可忽视的,尤其是今年复旦大学的一篇论文与 DeepMind、斯坦福大学的两篇论文一同获得 Runner Up 奖,腾讯 AI Lab 也是有超十篇论文被收录,都让我们对国内研究抱有更多的期待,也相信国内的研究所与高校在人工智能领域的基础性研究方面会取得更骄人的成绩。
▌
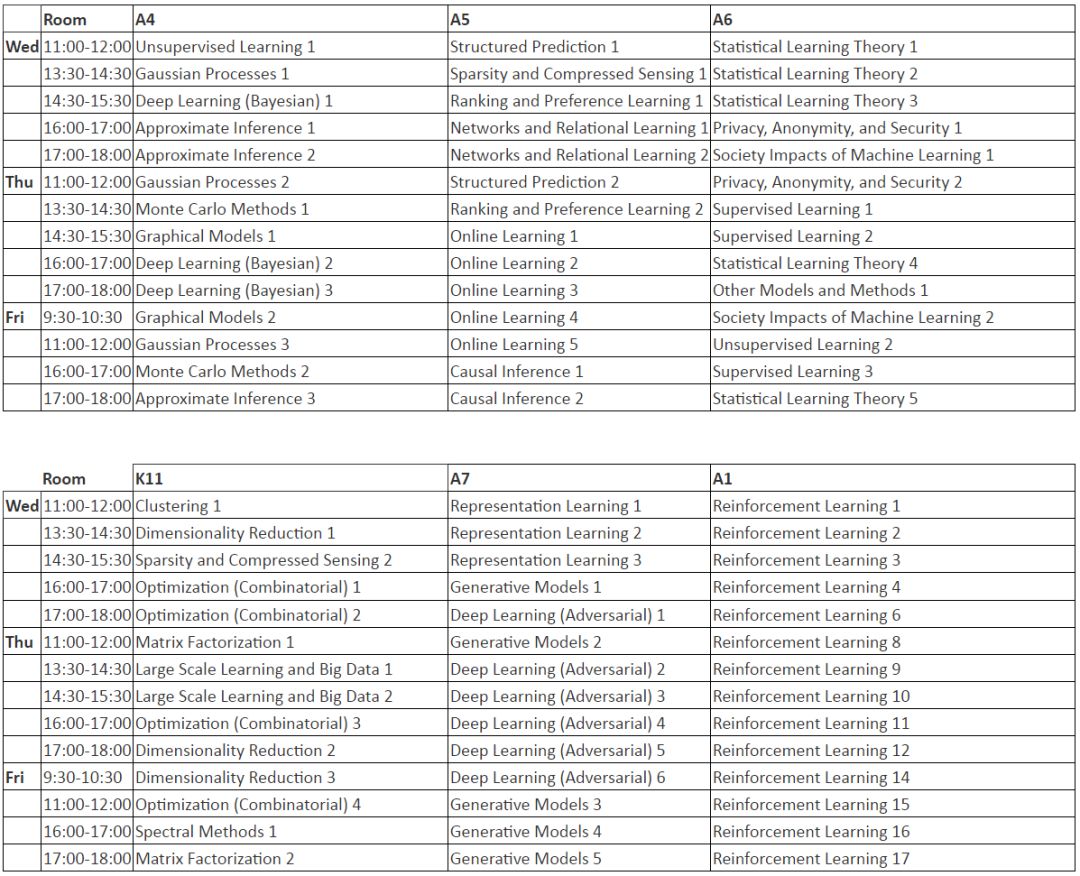
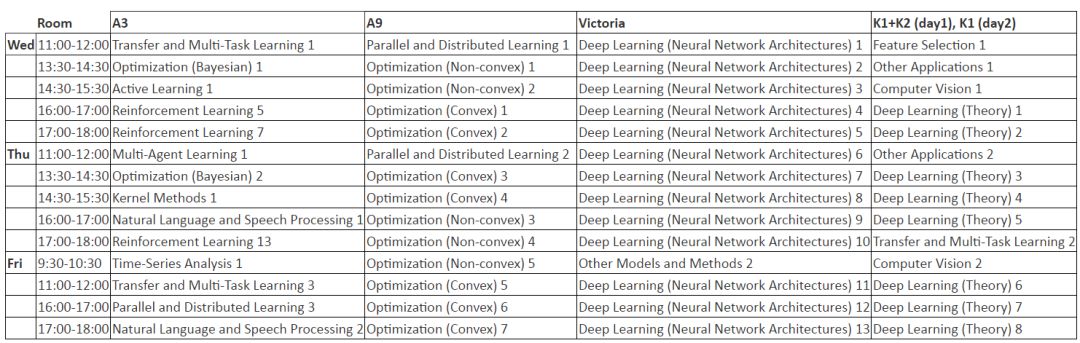
会议巡讲 Schedule
Tutorial Session 是后续主要技术开始前的教程日



后续三天就是主要技术的精彩纷呈,涉及了深度学习、强化学习、有限学习、变分贝叶斯、优化方法、自动机器学习等内容。
▌
论文收集录

最佳论文1
:来自 MIT 的 Anish Athalye 与来自 UC Berkely 的 Nicholas Carlini 和 David Wagner 获得了最佳论文。该研究定义了一种被称为「混淆梯度」(obfuscated gradients)的现象。在面对强大的基于优化的攻击之下,它可以实现对对抗样本的鲁棒性防御。早在今年 2 月,这项研究攻破了 ICLR 2018 七篇对抗样本防御论文的研究,曾一度引起了深度学习社区的热烈讨论。

论文链接:
https://arxiv.org/abs/1802.00420
项目链接:
https://github.com/anishathalye/obfuscated-gradients
最佳论文2:
来自 UC Berkeley EECS 的 Lydia T. Liu、Sarah Dean、Esther Rolf、Max Simchowitz 和 Moritz Hardt 的论文同样也获得了最佳论文奖。在这个研究中,关注机器学习公平性的静态分类标准如何与暂时的利益指标相互作用。总结了三个标准准则的延迟影响,强调评估公平性准则的度量和时序建模的重要性等一系列的新挑战和权衡问题。
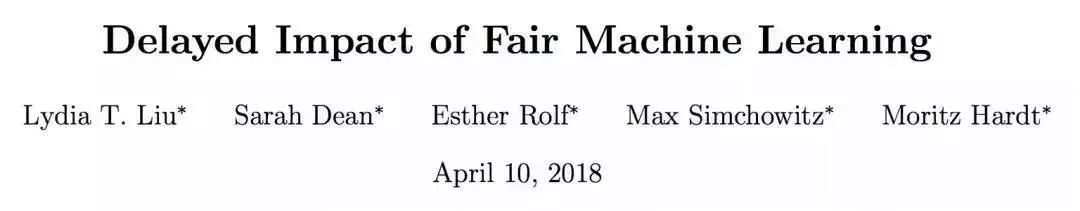
论文链接:
https://arxiv.org/abs/1803.04383
▌
Runner Up 论文
Runner UP 论文1:
复旦大学数据科学学院副教授黄增峰完成的在线流(online streaming)算法与 DeepMind、斯坦福大学的两篇论文共同获得 Runner Up 奖。在该论文讨论的这种在线流算法可以在只有非常小的协方差误差的情况下,从大型矩阵抽取出最能近似它的小矩阵。

论文地址:
http://203.187.160.132:9011/www.cse.ust.hk/c3pr90ntc0td/~huangzf/ICML18.pdf
Runner UP 论文2:
来自 DeepMind 和牛津大学的研究者在研究中开发了新的技术来理解和控制一般博弈中的动态。主要的结果是将二阶动态分解为两个部分。第一个和潜博弈(potential game)相关;第二个和哈密顿博弈相关,这是一种新的博弈类型,遵循一种守恒定律——类似于经典力学系统中的守恒定律。

论文地址:
https://arxiv.org/abs/1802.05642
Runner UP 论文3:
来自斯坦福大学的研究者在研究中首先展示了为解决经验风险最小化(ERM)使最初公平的模型也变得不公平了这一问题,提出了一种基于分布式鲁棒优化(distributionally robust optimization,DRO)的方法,可以最小化所有分布上的最大风险,使其接近经验分布。

论文地址:
https://arxiv.org/abs/1806.08010
颁发的两项最佳论文奖来表彰一些最有前途的论文技术方案的研究。最好的论文还将被邀请参加《机器学习杂志》。
▌
国内未来可期
而今年腾讯 AI Lab也是取得了十余篇入选的好成绩,相比去年的 4 篇入选,这个成绩不仅是国内企业研究、高校研究的榜首,在国际排名上也是有了很大的进步。
在十余篇的研究中,主要分为三类:新模型与新框架、分布式与去中心化及机器学习的理论研究与优化方法。本次为大家介绍三种新模型与新框架。
用于强化学习的基于反馈的树搜索
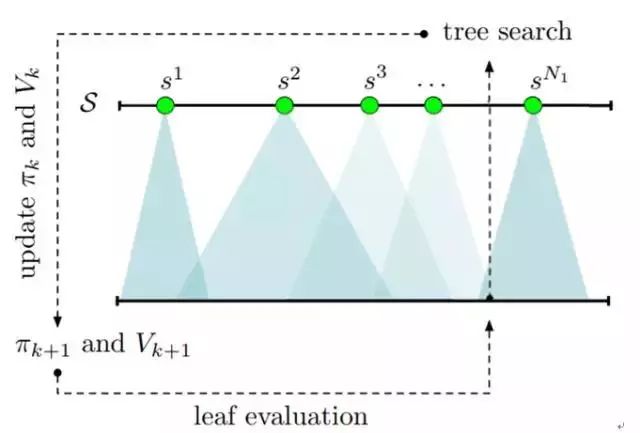
研究者还使用深度神经网络实现了这种基于反馈的树搜索算法并在《王者荣耀》1v1 模式上进行了测试。为了进行对比,研究者训练了 5 个操控英雄狄仁杰的智能体,结果他们提出的新方法显著优于其它方法。
论文链接:
https://arxiv.org/abs/1805.05935
通过学习迁移实现迁移学习











