
作者介绍
杨奇龙,前阿里数据库团队资深DBA,主要负责淘宝业务线,经历多次双十一,有海量业务访问DB架构设计经验。目前就职于有赞科技,负责数据库运维工作,熟悉MySQL性能优化,故障诊断,性能压测。
最近在压测新的存储,正好把工作过程中积累的对高性能MySQL相关的知识体系构建起来,做成思维导图的方式。总结乃一家之言,有不妥之处,望给位读者朋友指正。
构建高性能MySQL系统涵盖从单机、硬件、OS、文件系统、内存到MySQL 本身的配置,以及schema 设计、索引设计 ,再到数据库架构上的水平和垂直拓展。
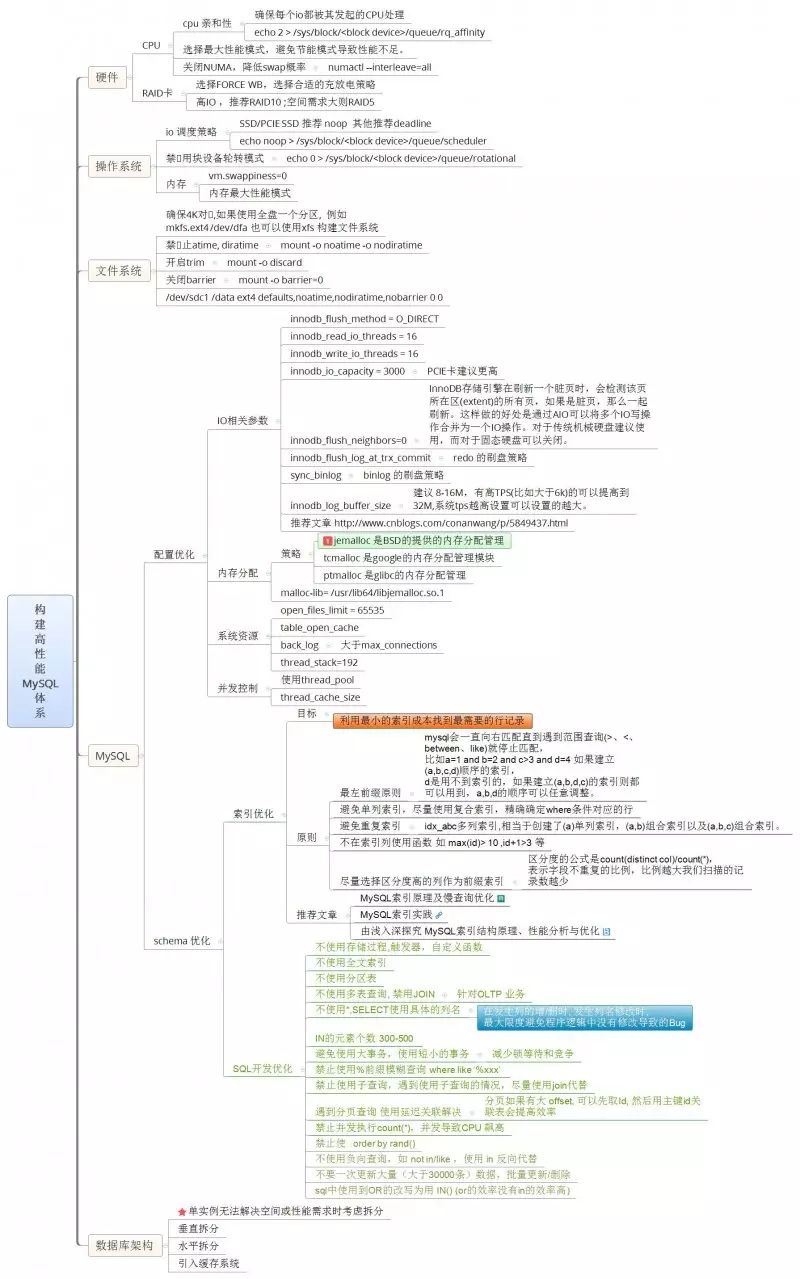
(1)CPU
确保每个io都被其发起的CPU处理
echo 2 > /sys/block//queue/rq_affinity
numactl --interleave=all
(2)RAID卡
选择FORCE WB读写策略
选择合适的充放电策略
高IO,推荐RAID10
空间需求大则RAID5
(1)IO调度策略
SSD/PCIE SSD推荐noop,其它推荐deadline
echo noop > /sys/block//queue/scheduler
(2)禁用块设备轮转模式
echo 0 > /sys/block//queue/rotational
(3)内存
确保4K对⻬,如果使用全盘一个分区,例如mkfs.ext4 /dev/dfa也可以使用xfs 构建文件系统。
mount -o noatime -o nodiratime
mount -o discard
mount -o barrier=0
/dev/sdc1 /data ext4 defaults,noatime,nodiratime,nobarrier 0 0
(1)配置优化
innodb_flush_method = O_DIRECT
innodb_read_io_threads = 16
innodb_write_io_threads = 16
innodb_io_capacity = 3000(PCIE卡建议更高)
innodb_flush_neighbors=0
InnoDB存储引擎在刷新一个脏页时,会检测该页所在区(extent)的所有页,如果是脏页,那么一起刷新。这样做的好处是通过AIO可以将多个IO写操作合并为一个IO操作。对于传统机械硬盘建议使用,而对于固态硬盘可以关闭
innodb_flush_log_at_trx_commit
redo 的刷盘策略
sync_binlog
binlog 的刷盘策略
innodb_log_buffer_size
建议8-16M,有高TPS(比如大于6k)的可以提高到32M,系统tps越高设置可以设置的越大
推荐文章 www.cnblogs.com/conanwang/p/5849437.html
jemalloc是BSD的提供的内存分配管理
tcmalloc是google的内存分配管理模块
ptmalloc是glibc的内存分配管理
malloc-lib= /usr/lib64/libjemalloc.so.1
malloc-lib= /usr/lib64/libjemalloc.so.1
back_log:大于max_connections
thread_stack=192
使用thread_pool
thread_cache_size
(2)schema优化
目标:利用最小的索引成本找到最需要的行记录。
原则:
最左前缀原则:MySQL会一直向右匹配直到遇到范围查询(>、3 and d=4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整
避免重复索引:idx_abc多列索引,相当于创建了(a)单列索引,(a,b)组合索引以及(a,b,c)组合索引。不在索引列使用函数 如 max(id)> 10 ,id+1>3 等
尽量选择区分度高的列作为前缀索引:区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少
推荐文章:
MySQL索引原理及慢查询优化
http://tech.meituan.com/mysql-index.html
MySQL索引实践
http://blog.coderland.net/mysql/2015/08/26/MySQL%E7%B4%A2%E5%BC%95%E5%AE%9E%E8%B7%B5/
由浅入深探究 MySQL索引结构原理、性能分析与优化
http://blog.jobbole.com/87107/
不使用存储过程、触发器,自定义函数
不使用全文索引
不使用分区表
针对OTLP业务尽量避免使用多表join和子查询
不使用*,SELECT使用具体的列名:在发生列的增/删时,发生列名修改时,最大限度避免程序逻辑中没有修改导致的BUG,IN的元素个数300-500
避免使用大事务,使用短小的事务:减少锁等待和竞争
禁止使用%前缀模糊查询 where like ‘%xxx’
禁止使用子查询,遇到使用子查询的情况,尽量使用join代替
遇到分页查询,使用延迟关联解决:分页如果有大offset,可以先取Id,然后用主键id关联表会提高效率
禁止并发执行count(*),并发导致CPU飙高
禁止使⽤order by rand()
不使用负向查询,如 not in/like,使用in反向代替
不要一次更新大量(大于30000条)数据,批量更新/删除
SQL中使用到OR的改写为用 IN() (or的效率没有in的效率高)
单实例无法解决空间和性能需求时考虑拆分
垂直拆分
水平拆分
引入缓存系统
IO相关的优化可能还不完整,以后会逐步完善。
关于数据库系统水平和垂直拆分是一个比较大的命题,这里略过,每个公司的业务规模不一样,选取的拆分策略也有所不同。
点击文末【阅读原文】或登录云盘http://pan.baidu.com/s/1dFpI4t7,可下载高清版思维导图。
也欢迎大家提供自己的想法,一起来完善这张高性能MySQL系统思维导图,可直接在本文微信评论区留言或发送邮件至:[email protected]。
相关专题:
◆ 近期热文 ◆
◆ 近期活动 ◆
DAMS中国数据资产管理峰会上海站

峰会官网:www.dams.org.cn











