
【文末有彩蛋】
本文来自作者
刘盼
在 GitChat 上的分享,「
阅读原文
」看看大家与作者交流了哪些问题?
我们先以汽车在现代科技领域的演进来开始这次的 chat,最早的就是电动汽车,其中的代表无疑是特斯拉,相信大家对电动车还是比较熟悉的,这里就不展开说明了。
最近很火的共享车,以滴滴来讲,据滴滴官方报道平台用户3亿,车主1500万,日均订单有1400万,从1400万的数据来看订单数已经超过美团,大众点评。
在中国互联网界仅次于阿里巴巴和京东,要知道滴滴是个非常年轻的公司,但是这1400万的日均订单也只占整个出行市场的1%,可见整个出行市场的天花板还远远望不到头。
接下来就是车联网领域,车联网是个很广义的概念,涉及面很广,确切来讲属于物联网的一个终端。
下面以一张图来了解车联网涉及到的方方面面。
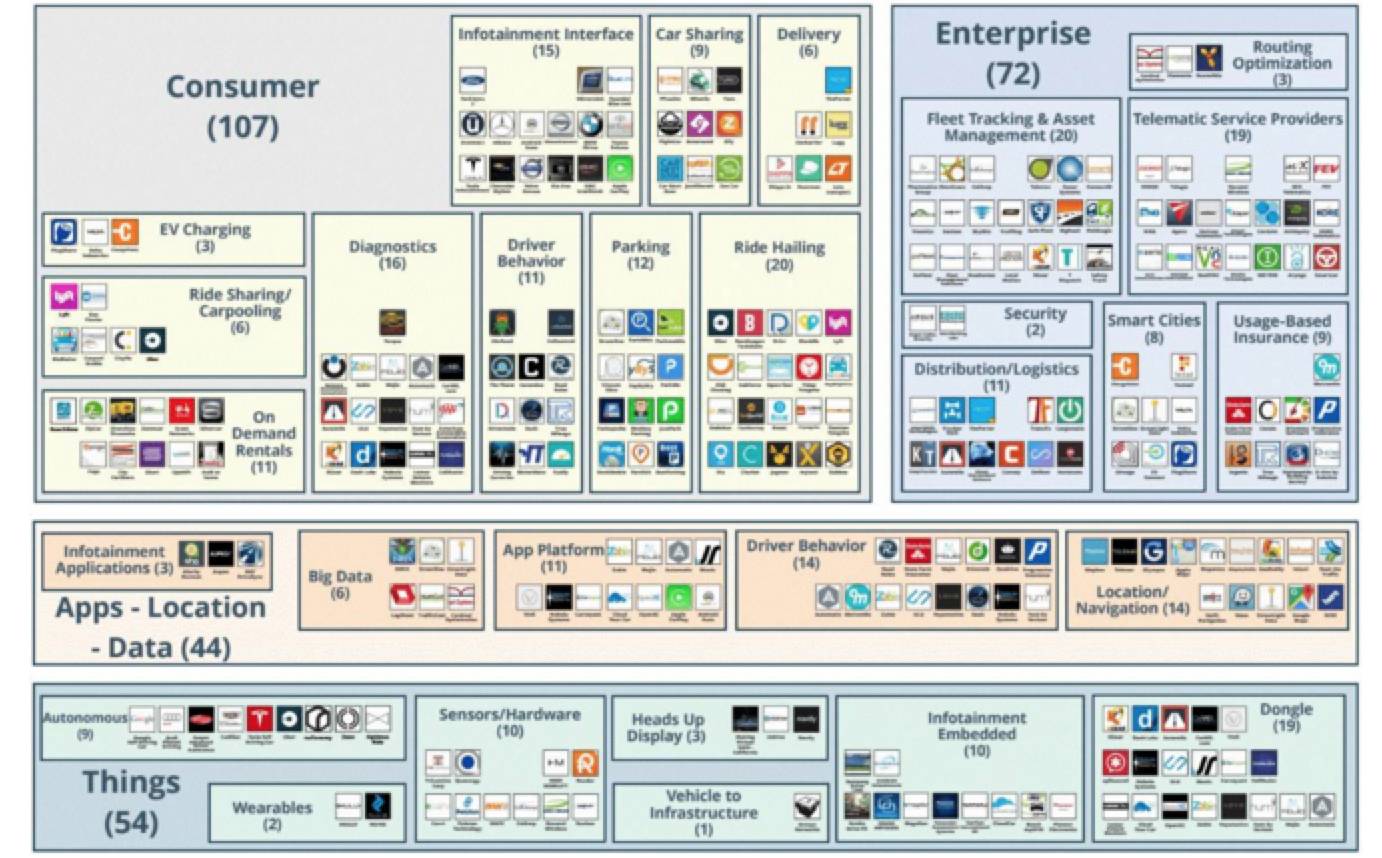
下面进入这次 chat 的主题,自动驾驶,目前市场上的自动驾驶公司我个人认为可以分为以下几类:
-
google,uber
-
volvo audi
-
drive.ai comma.ai
-
delphi bosch
第一类就是谷歌旗下子公司 waymo,和 uber 收购的 otto,这也是互联网行业进军的代表,但是这两家公司可是死对头,关于 uber/otto 侵权 waymo 的激光雷达技术闹的不可开交。
第二类是传统汽车厂商比如 volvo,audi 都是在很早就对自动驾驶领域展开研究。
第三类是一些小型创业公司,其中的代表是吴恩达老婆的 drive.ai 和神奇小子 geohot 的 comma.ai。
相信很多人对 geohot 并不陌生,没错,他就是17岁破解 iphone,21岁引发黑客大战的神奇小子。
他自称打造了一套1000美元的自动驾驶套件 comma one,现已开源,感兴趣的朋友可以去学习,地址是https://github.com/commaai/openpilot。
第四类是 delphi,bosch 这样的 tiger 1 厂商。这些公司都在为自动驾驶的那一天添砖加瓦,可是这些科技巨头和汽车巨头为什么都不约而同的选择自动驾驶呢,我想可以从以下几点总结一下。
目前每年全球有130万人死于车祸,损失 $518B,相关于很多国家1-2%的 GDP,自动驾驶可以很大效率的减少车祸,拯救生命。
除了在安全方面对人类有很大帮助,在时间利用上也可以解放人类在汽车上的使用时间,从而提高人类「寿命」,据报道平均每人每日在汽车上花费时间101分钟,从驾驶中解放的时间如果去做其他的事情,可以提高20%的 GDP。
此外据报道目前汽车90%的时间是闲置停在停车场的,如果汽车可以自己开的话,那汽车本身就可以共享,利用共享的商业模式让汽车时时刻刻都跑在路上,对于生命时间的延续和土地资源的解放都是毋庸置疑的。
现在我们知道自动驾驶会给人类带来前所未有的必要性和价值,那么什么才是自动驾驶呢,网络上关于自动驾驶的定义千奇百怪。
这里我以我的理解统一定义一下,
自动驾驶是根据汽车依靠人工智能、视觉计算、雷达、监控装置和全球定位系统协同合作,让电脑可以在没有任何人类主动的操作下,自动安全地操作机动车辆。
根据这个定义,其实自动驾驶其实已经有了一定程度的实际应用。判断自动驾驶的核心就在于主动式的操作,而根据其主动介入的程度,自动驾驶可以分为下列几个阶段。
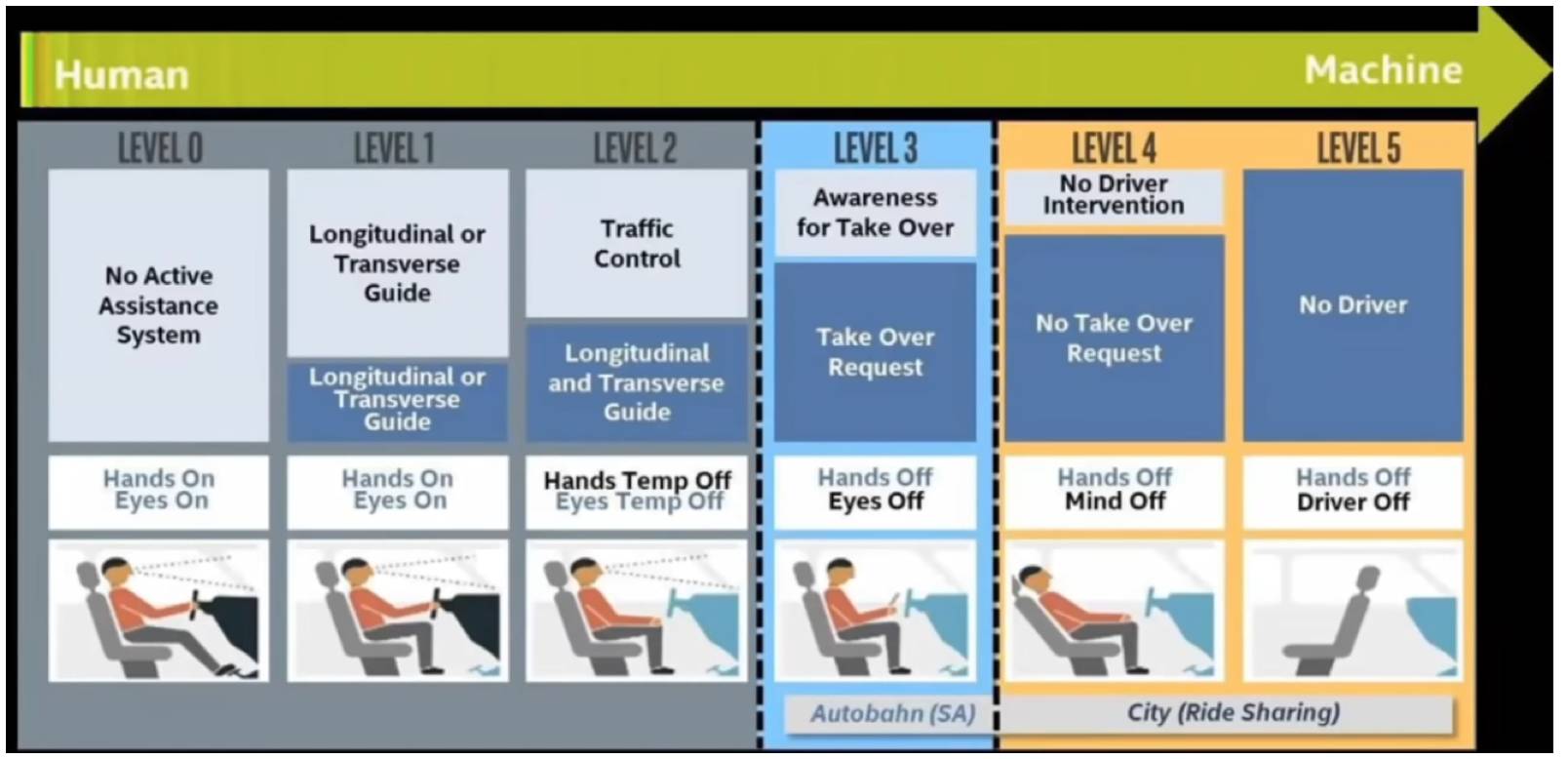
SAE(美国汽车工程师协会)和 NHTSA(美国高速公路安全局)将自动驾驶技术进行了分级。这里我们用一张图来概括一下:
-
Level 0 就是我们目前看到的大部分汽车。
-
Level 1 实际上是 ADAS 阶段,驾驶员辅助系统能为驾驶员在驾驶时提供必要的信息采集,在关键时候,给予清晰的、精确的警告,相关技术有:车道偏离警告(LDW),正面碰撞警告(FCW)和盲点报警系统。。
-
Level 2 就是半自动驾驶,驾驶员在得到警告后,仍然没能做出相应措施时,半自动系统能让在汽车自动做出相应反应。
相关技术有:紧急自动刹车(AEB),紧急车道辅助(ELA),就像 tesla autopilot,不仅车速帮你控制,方向盘也帮你控制,从技术上来看特兹拉已经做到很成熟。
-
Level 3 场所的高度自动驾驶。该系统能在驾驶员监控的情况下,让汽车提供长时间或短时间的自动控制行驶,比如在商场,学校,小区里,这个实际上在欧洲搞了很多年了,很多地方可以看到这种 shuttles。
-
Level 4-5 完全自动驾驶,在无需驾驶员监控的情况下,汽车可以完全实现自动驾驶,意味着驾驶员可以在车上从事其他活动,如上网办公、娱乐或者休息。

自动驾驶汽车技术的基本模块:
-
Perception (other objects around the car)
-
Localization (GPS + local landmarks + IMU)
-
Decision (path, speed and other behavior planning)
-
Control (Drive by wire steering wheel,throttle & brake…)
其中感知和决策模块是目前自动驾驶领域两大流派的主要区别。这里我们简单做个区分:
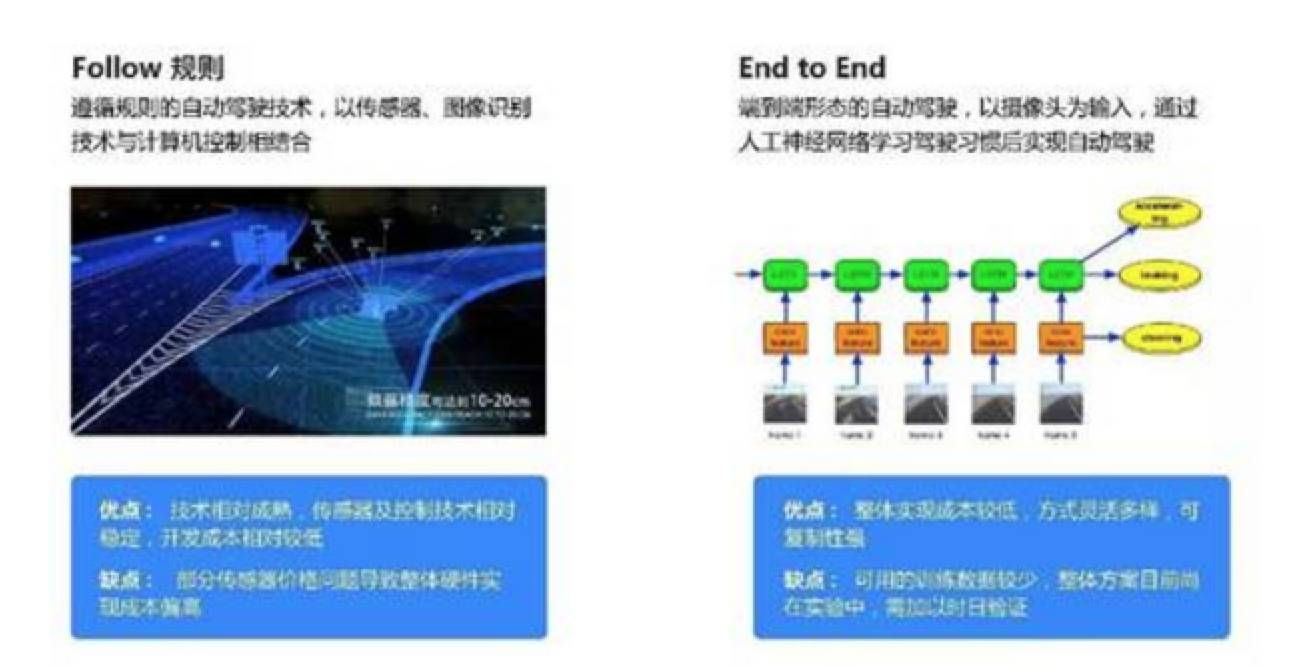
第一个流派就是基本上所有的公司,包括百度的两个部门、Google、特斯拉都在做这件事情,就是基于规则的自动驾驶。基于规则很简单,就是把我们的自动驾驶分为很多场景。
比如高速公路,普通的道路,城市的道路,然后又分为很多的情景,包括类似于天气,包括像停车这样一些事情,遇到什么情况该怎么做这样一个事情。这叫基于规则的一种自动驾驶,简单的。
另外一种是端到端的自动驾驶,端到端大家不用管这边如何描述,其实蛮简单,你可以把自己想象成一个老司机,你会开车,但可能开了十万公里,你的车依然不知道你的驾驶行为和驾驶习惯是什么。
我们在想,是不是有一个人他能在你的车后面,它可以是一个机器人,它在不断的学习你的开车习惯,有一天在你累的时候它可以帮助你去开车,而且是以你的习惯去开车,这种方法就是 End to End(端到端 )。
端到端可以认为是黑箱子,我们只关心输入和输出,不关心里面到底是不是能做决策。
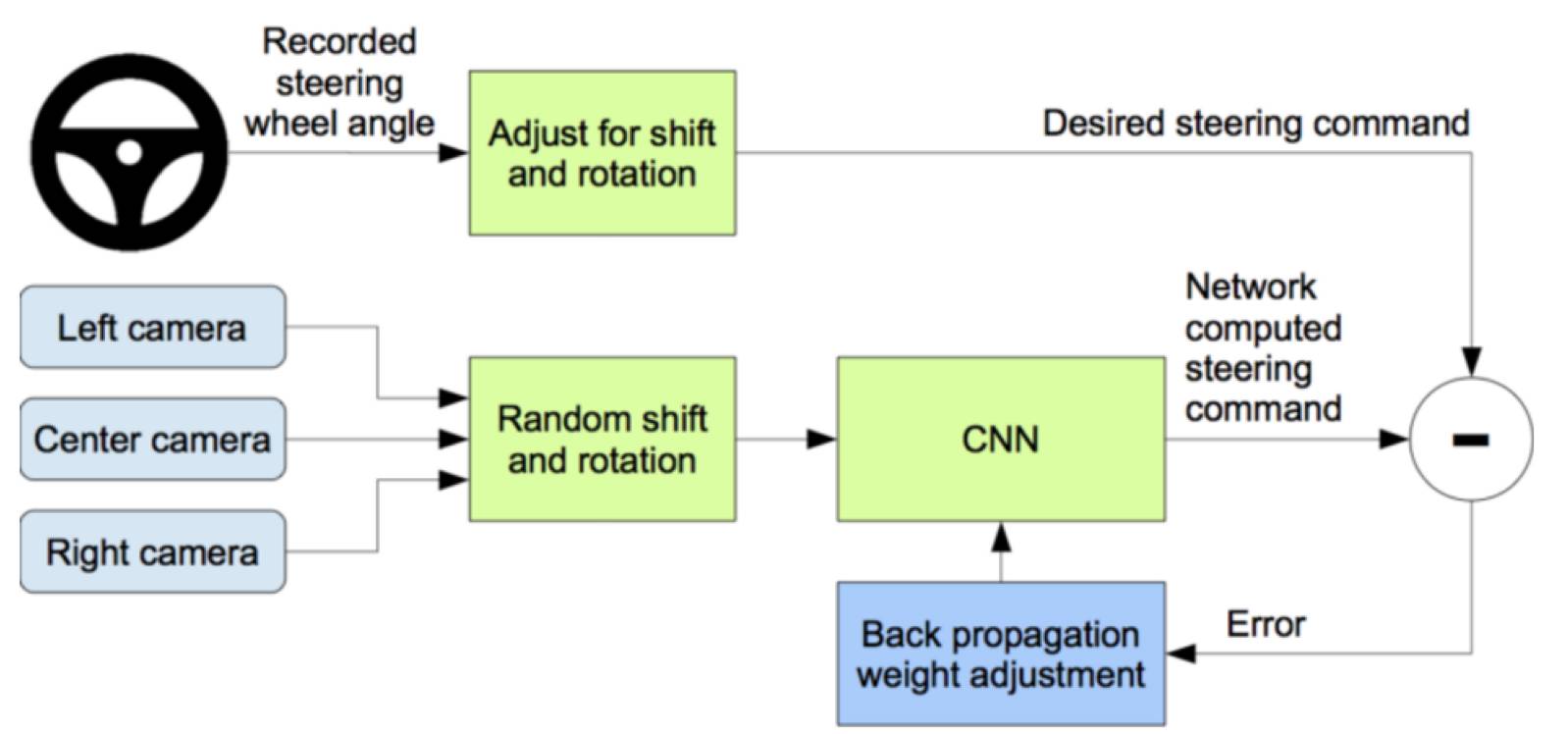
端到端的出现大大降低了自动驾驶的门槛,使互联网科技公司有机会和汽车巨头在自动驾驶领域一决高下,下面我们简单看下NVIDIA端到端的深度学习,可以参考 NVIDIA 论文。
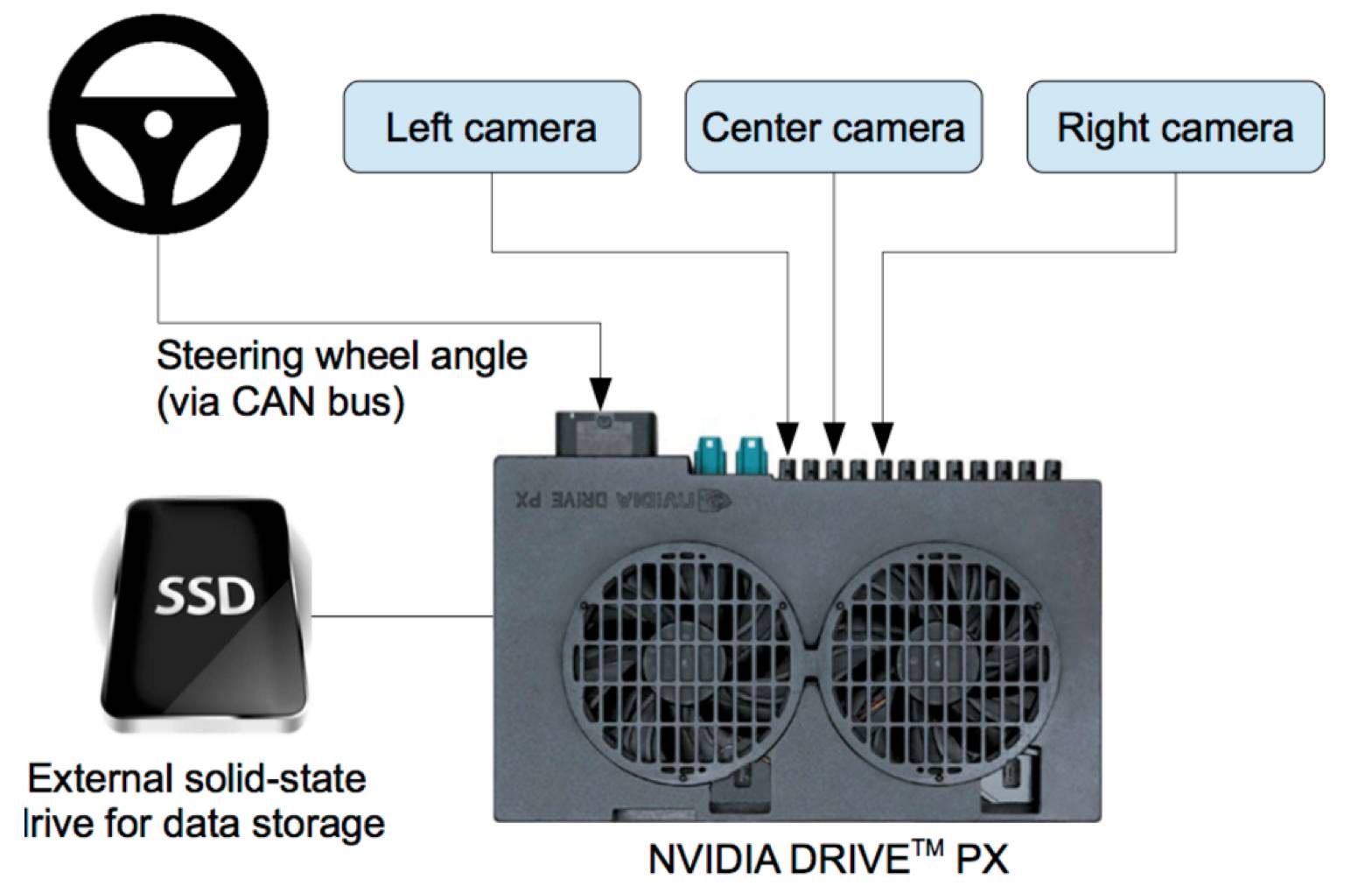
图中显示了一个简化的 DAVE-2 训练数据采集系统方框图。三架摄像机安装在数据采集汽车的挡风玻璃后面,而来自摄像机的时间戳视频是与人类驾驶员的转向角度同时被捕获的。
转向命令是通过进入车辆的控制器区域网络(Controller Area Network / CAN)总线得到。
为了使我们的系统独立于汽车的外形,我们将转向命令表示为 1/r,其中 r 代表每米的转弯半径。我们使用 1/r 而不是 r 以防止直线驾驶时的奇点(直线行驶的转弯半径为无穷大)。
1/r 从左转弯(负值)转变到右转弯(正值)时平滑地通过零点。
训练数据包含视频采样得到的单一图像,搭配相应的转向命令(1/r)。只有来自人类驾驶员的数据是不足以用来训练的;网络还必须学习如何从任何错误中恢复,否则该汽车就将慢慢偏移道路。
因此训练数据还扩充了额外的图像,这些图像显示了远离车道中心的偏离程度以及不同道路方向上的转动。
两个特定偏离中心的变化图像可由左右两个摄像机捕获。摄像机和所有转动之间的额外偏移是通过最近的摄像机的图像的视角变换(viewpoint transformation)进行模拟的。
精确的视角变换需要 3D 场景知识,而我们没有这些知识,因此只能做近似变换——假设水平线以下的所有点都在平地上,而水平线以上的所有点在无限远。
这种方法在平面地形上产生的效果很好,但对于一个更完整的渲染,它还引入了地表以上物体的畸变,比如汽车、电线杆、树木和建筑物。幸运的是,这些畸变不会给网络训练带来大问题。
变换后的图像的转向标签会在两秒内被迅速调整到正确驾驶汽车时回到的期望位置和方向。
下图显示了我们的训练系统框图。图像被送入一个卷积神经网络,然后计算一个被推荐的转向命令。
这个被推荐的转向命令会与该图像的期望命令相比较,卷积神经网络的权重就会被调整以使其实际输出更接近期望输出。权重调整是使用Torch 7 机器学习包中所实现的反向传播完成的。
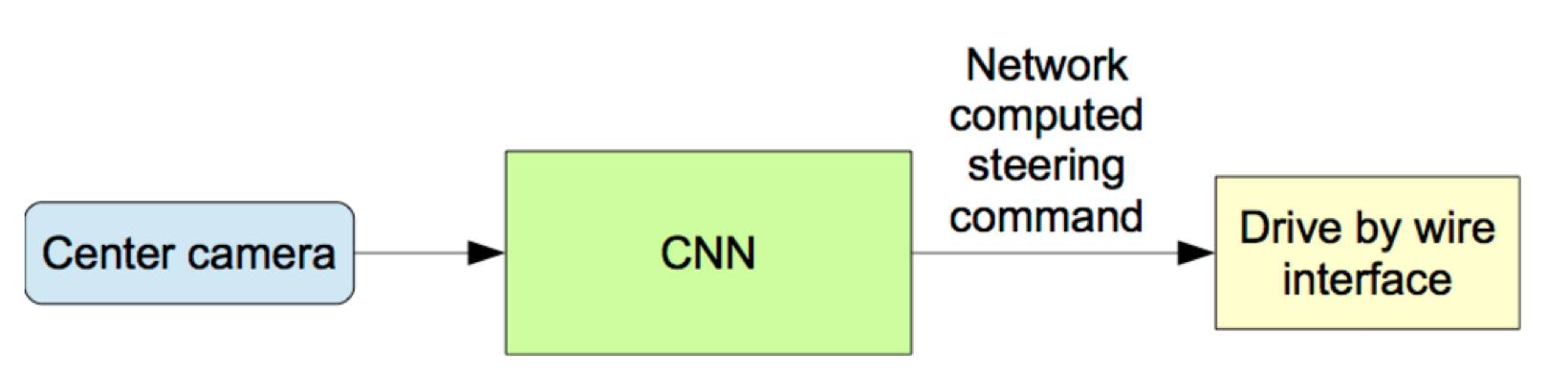
一旦训练完成,网络就能够从单中心摄像机(single center camera)的视频图像中生成转向命令。下图展示了这个配置。
这里不做深层次的讲解,感兴趣的小伙伴我们下一次可以开个专题来chat。下面展示下百度是如何利用这项技术进行自动驾驶的。
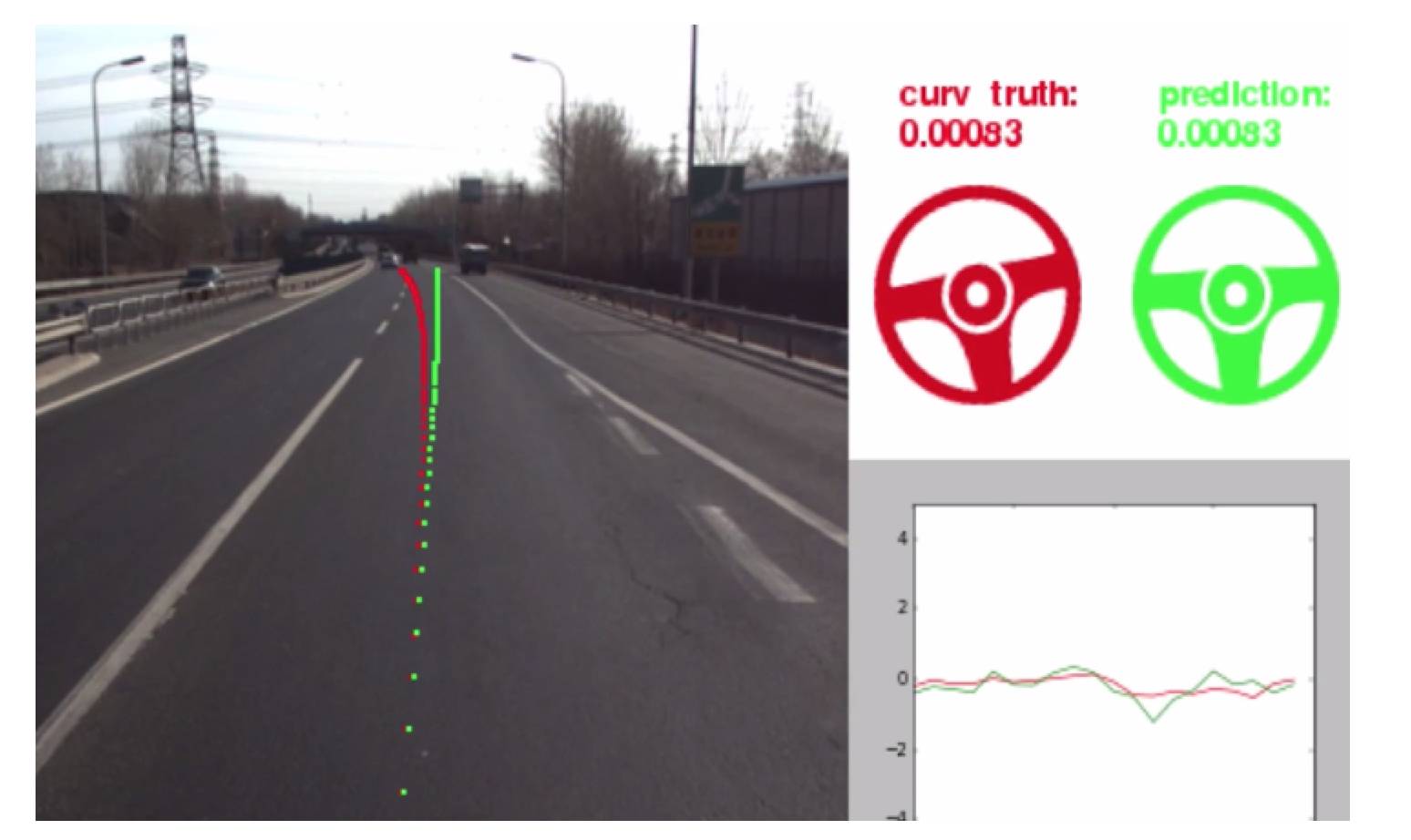
其中左侧道路和右上方方向盘表示横向曲率计算,红色代表真实值,绿色代表算法推算值;右下方折线图表示纵向加速度计算,红色代表真实值,绿色代表算法推算值。
在讲解感知模块之前先了解下车上需要装的sensor模块有哪些:

接下来进入第一个模块,感知(Perception):
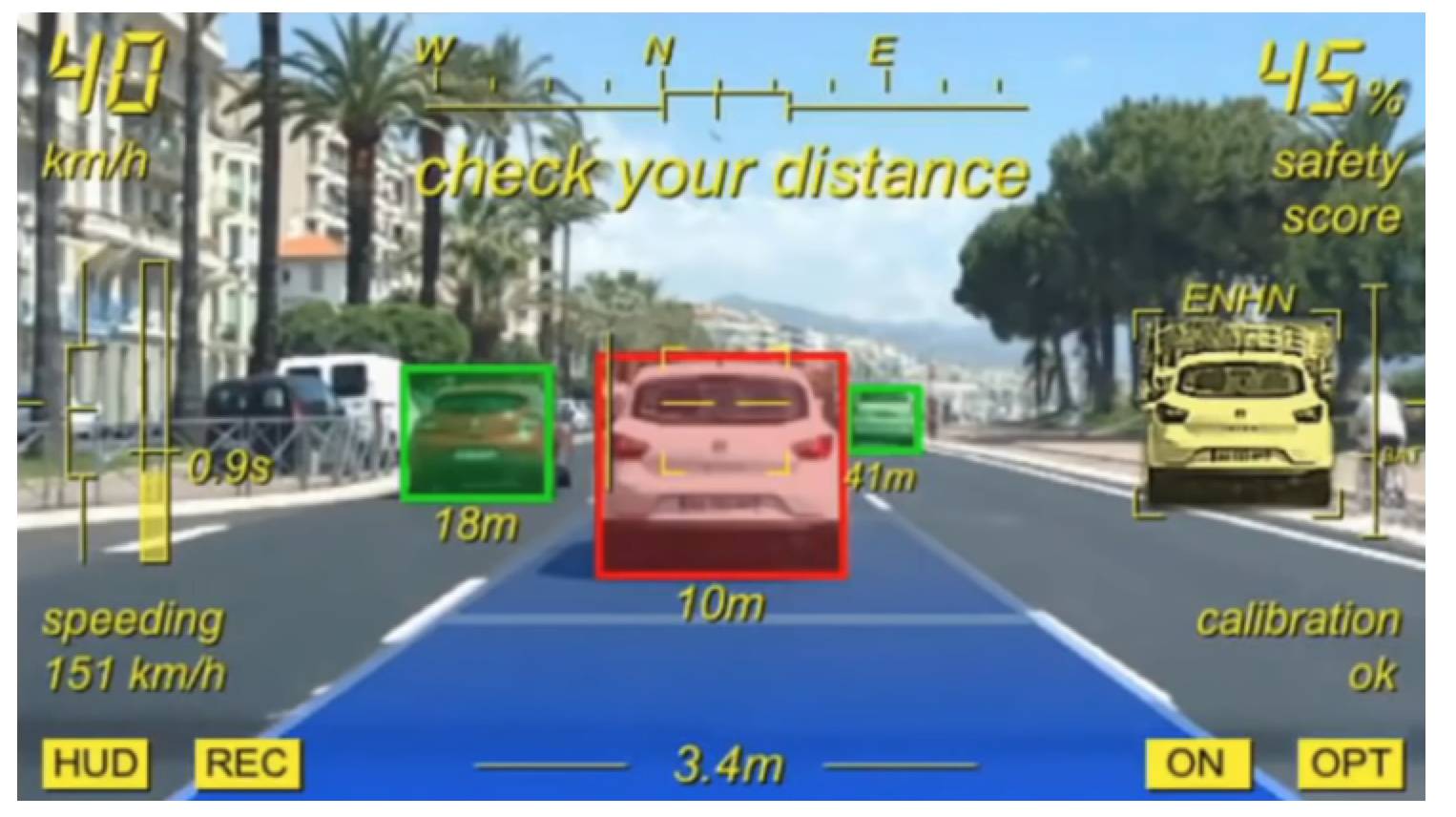
感知是最基础的部分,没有对车辆周围三维环境的定量感知,就有如人没有了眼睛,无人驾驶的决策系统就无法正常工作。
为了安全与准确的感知,无人驾驶系统使用了多种传感器,其中可视为广义「视觉」的有超声波雷达、毫米波雷达、激光雷达(LiDAR)和摄像头等。
超声波雷达由于反应速度和分辨率的问题主要用于倒车雷达,毫米波雷达和激光雷达承担了主要的中长距测距和环境感知,而摄像头主要用于交通信号灯和其他物体的识别。
通过采集大量的传感器数据(激光雷达,毫米波雷达,超声波雷达,摄像头雷达等)来感知汽车周围的环境状况,认知周围的世界,也这是自动驾驶的基础。首先,要验证一个方案是否可行,我们需要一个标准的测试方法。
现在很多公司都在做自己的数据采集,前段时间百度公开的阿波罗计划也是出于开源数据采集的生态发展。这里将介绍由德国卡尔斯鲁厄技术研究院(KIT)和丰田芝加哥技术研究院(TTIC)共同开发的 KITTI 数据集。
在有了标准的数据集之后,研究人员可以开发基于视觉的无人驾驶感知算法,并使用数据集对算法进行验证。
KITTI 数据集是由 KIT 和 TTIC 在2012年开始的一个合作项目,网站在 http://www.cvlibs.net/datasets/kitti/,这个项目的主要目的是建立一个具有挑战性的、来自真实世界的测试集。他们使用的数据采集车配备了:
-
一对140万像素的彩色摄像头Point Grey Flea2(FL2-14S3C-C),采集频率10赫兹。
-
一对140万像素的黑白摄像头Point Grey Flea2(FL2-14S3M-C),采集频率10赫兹。
-
一个激光雷达Velodne HDL-64E。
-
一个GPS/IMU定位系统OXTSRT 3003。
下面讲一下多个测试任务的数据集:



这里以 CNN 为例作为计算机视觉不可避免的成为无人驾驶感知中双目感知和物体检测的重要应用。
卷积神经网络(Convolutional Neural Network,CNN)是一种适合使用在连续值输入信号上的深度神经网络,比如声音、图像和视频。
它的历史可以回溯到1968年,Hubel 和 Wiesel 在动物视觉皮层细胞中发现的对输入图案的方向选择性和平移不变性,这个工作为他们赢得了诺贝尔奖。
时间推进到上世纪80年代,随着神经网络研究的深入,研究人员发现对图片输入做卷积操作和生物视觉中的神经元接受局部 receptive field 内的输入有相似性,那么在神经网络中加上卷积操作也就成了自然的事情。
当前的 CNN 相比通常的深度神经网络(DNN),特点主要包括:
由于CNN在神经网络的结构上针对视觉输入本身特点做的特定设计,所以它是计算机视觉领域使用深度神经网络的不二选择。
在2012年,CNN 一举打破了 ImageNet 这个图像识别竞赛的世界纪录之后,计算机视觉领域发生了天翻地覆的变化,各种视觉任务都放弃了传统方法,启用了 CNN 来构建新的模型。
无人驾驶的感知部分作为计算机视觉的领域范围,也不可避免地成为 CNN 发挥作用的舞台。
定位(Localization):

定位主要通过粒子滤波进行。所谓粒子滤波就是指:通过寻找一组在状态空间中传播的随机样本来近似表示概率密度函数,用样本均值代替积分运算,进而获得系统状态的最小方差估计的过程,这些样本被形象地称为「粒子」,故而叫粒子滤波。
比较常见的(如在Sebastian Thrun的经典无人车论文中)是粒子滤波维护一个姿态向量(x, y, yaw),默认roll/pitch相对足够准,运动预测可以从IMU中取得加速度和角速度。
粒子滤波需要注意样本贫化和其他可能的灾难定位错误(catastrophic error),一小部分粒子可以持续从现在 GPS 的位置估计中获得。对样本数量的自适应控制也需要根据实际情况有效调整。
因为已经有了高精度 LiDAR 点云地图,所以很自然地就可以用实时点云数据和已经建好的地图进行匹配。
而3D点云匹配必然要说到 Iterative Closest Point (ICP),ICP 的目标是在给出两组点云的情况下,假设场景不变,算出这两组点云之间的 pose。
最早的 ICP 原理,就是第一组点云的每个点在第二组点云里找到一个最近的匹配,之后通过所有的匹配来计算均方误差(MSE),进而调整估计的pose,这样进行多次迭代,最终算出两组点云的相对 pose。
因此,预先有地图的情况下,用实时的点云加上一个大概 pose猜测就可以精准算出无人车的当前 pose,且时间相邻的两帧点云也可以算出一个相对 pose。
GPS 是基于地球中央子午线与赤道交点的投影为原点坐标系的地理地图,其表示格式为二维坐标点格式,误差在10米左右,这种误差对于自动驾驶是远远不够的。
高精度地图是一种以地理位置为参考的道路路网拓扑地图,该拓扑地图不仅能够描述车道路段建的关系,同时还能够描述车道数量,车道宽度,固定障碍位置等多维属性;
另外还有一种动态高精度地图,实际上是一种具有超强动态感知能力的传感器,可通过云端向智能车实时下发目标路段的道路信息(道路几何信息,拥堵信息,施工信息等)及障碍物信息(位置,速度,类型等,需具备数据采集及传输能力)。










