大家好!我是赵健博,来自58赶集,今天给大家分享一下58大数据这块的经验。我先做个自我介绍,我本科和研究生分别是在北京邮电大学和中国科学院计算技术研究所先后毕业的,之前在百度和360工作,现在是58赶集高级架构师、58大数据平台负责人。我有多年的分布式系统(存储、计算)的实践和研发经验,在我工作的这些年中运营了大大小小的集群,最大单集群也达到了四五千台,在这个过程中做了大量的功能研发、系统优化,当然也淌了大量的坑,今天会给大家介绍一些我认为比较重要的。
接下来我会跟大家分享一下58大数据平台在最近一年半的时间内技术演进的过程。主要内容分为三方面:58大数据平台目前的整体架构是怎么样的;最近一年半的时间内我们面临的问题、挑战以及技术演进过程;以及未来的规划。
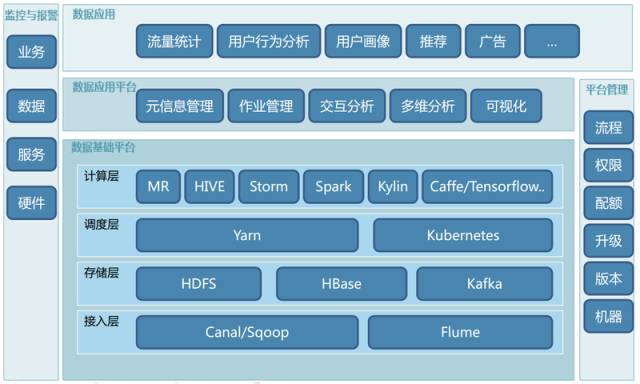
首先看一下58大数据平台架构。大的方面来说分为三层:数据基础平台层、数据应用平台层、数据应用层,还有两列监控与报警和平台管理。
数据基础平台层又分为四个子层:
接入层,包括了Canal/Sqoop(主要解决数据库数据接入问题)、还有大量的数据采用Flume解决方案;
存储层,典型的系统HDFS(文件存储)、HBase(KV存储)、Kafka(消息缓存);
再往上就是调度层,这个层次上我们采用了Yarn的统一调度以及Kubernetes的基于容器的管理和调度的技术;
再往上是计算层,包含了典型的所有计算模型的计算引擎,包含了MR、HIVE、Storm、Spark、Kylin以及深度学习平台比如Caffe、Tensorflow等等。
数据应用平台主要包括以下功能:
元信息管理,还有针对所有计算引擎、计算引擎job的作业管理,之后就是交互分析、多维分析以及数据可视化的功能。
再往上是支撑58集团的数据业务,比如说流量统计、用户行为分析、用户画像、搜索、广告等等。
针对业务、数据、服务、硬件要有完备的检测与报警体系。
平台管理方面,需要对流程、权限、配额、升级、版本、机器要有很全面的管理平台。
这个就是目前58大数据平台的整体架构图。
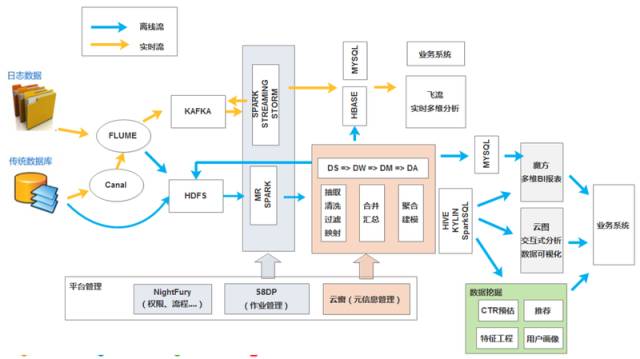
这个图展示的是架构图中所包含的系统数据流动的情况。分为两个部分:
首先是实时流,就是黄色箭头标识的这个路径。数据实时采集过来之后首先会进入到Kafka平台,先做缓存。实时计算引擎比如Spark streaming或storm会实时的从Kafka中取出它们想要计算的数据。经过实时的处理之后结果可能会写回到Kafka或者是形成最终的数据存到MySQL或者HBase,提供给业务系统,这是一个实时路径。
对于离线路径,通过接入层的采集和收集,数据最后会落到HDFS上,然后经过Spark、MR批量计算引擎处理甚至是机器学习引擎的处理。其中大部分的数据要进去数据仓库中,在数据仓库这部分是要经过数据抽取、清洗、过滤、映射、合并汇总,最后聚合建模等等几部分的处理,形成数据仓库的数据。然后通过HIVE、Kylin、SparkSQL这种接口将数据提供给各个业务系统或者我们内部的数据产品,有一部分还会流向MySQL。以上是数据在大数据平台上的流动情况。
在数据流之外还有一套管理平台。包括元信息管理(云窗)、作业管理平台(58dp)、权限审批和流程自动化管理平台(NightFury)。

我们的规模可能不算大,跟BAT比起来有些小,但是也过了一千台,目前有1200台的机器。我们的数据规模目前有27PB,每天增量有50TB。作业规模每天大概有80000个job,核心job(产生公司核心指标的job)有20000个,每天80000个job要处理数据量是2.5PB。
原文链接:
https://mp.weixin.qq.com/s/BWDbcNUaFf6LpGwQdK4emQ









