双十一的技术准备在做两件事情:第一是系统的准备尽可能的接近真实,包括容量确定性和资源的确定性;第二是整个过程中的效率,包括人和单位资源效率。仅凭这两件事情,就能撑起这场大促吗?
本文整理自蒋江伟在ArchSummit 2016 北京站上的演讲。
后台回复关键词「双十一」,下载本文完整PPT。
从2009年到2016年,参与了8届双十一技术备战工作。2009年的双十一,印象并不深刻,主要原因是当时整个淘宝的体量已经很大,每天的交易额已经有几亿的规模,而当时的淘宝商城双十一交易额只有5000万左右,和几亿比体量还是非常小的,所以感觉还没开始就过去了。
到了后面几年,每年都要花费好几个月的时间去精心准备,要做监控、报警的梳理,要做容量的规划,要做整个依赖的治理等等,也整理了各种各样的方法论。这是一个过程,当然在这个过程里面也沉淀出了很多非常有意义的事情。
今天有人问我怎么做双十一,怎么做大促活动,我会告诉他一个非常简单的方法,就是做好容量规划,做好限流降级。
2008年,我加入淘宝,直接参与淘宝商城的研发工作。淘宝商城就是后来的天猫,当时整个淘宝商城的技术体系,和淘宝网是完全不一样的,是完全独立的体系。它的会员、商品、营销、推荐、积分、论坛,都和淘宝网没有任何的关系。两套体系是完全独立的,唯一有关系的是整个会员的数据是共享的。
2008年末启动了「五彩石项目」,把两套体系的数据打通、业务打通,最核心的点就是业务的发展变得非常灵活。这个项目的完成给淘宝商城的发展带来非常大的飞跃,后来淘宝商城也升级品牌为天猫。
另外,这个项目里还有一个很大的意义,就是比较优雅的实现了架构的扩展性、业务的扩展性和技术的扩展性。我们实现了整个服务的全部服务化,抽取了所有与电商相关的公共元素,包括会员体系、商品中心、交易中心、营销、店铺、推荐等。基于这个体系,构建后来像聚划算、电器城、航旅等的业务就非常快了。打破原来的架构,将整个公共的服务抽取出来之后,上层的业务跑得非常快,这就解决了业务扩展性的问题。
第一次大规模使用中间件是在这个项目里,中间件3剑客,HSF、Notify、TDDL得到了很大的创新沉淀,并被大规模的使用。分布式带来的问题是一个系统被拆成了很多的系统,这其中也涉及到了扩展性的问题。这个项目也带来了技术的进步,从业务的发展到技术的扩展性,都达成了非常好的目标。
2012年,我开始带中间件产品线和高可用架构的团队。那么为什么要做容量规划呢?
双十一推动了阿里巴巴技术上非常大的创新,容量规划也是双十一在这个过程中非常好的创新。
今年做双十一的时候,老板问我今年还有什么风险?我告诉他风险肯定很多,但是最终如果系统出问题了,肯定发生在交易相关的系统里。阿里巴巴的系统分两部分:一部分系统是促进交易的,比如推荐、导购、搜索、频道等都是促进交易的,会做各种各样的营销;另外一部分系统做交易、红包、优惠等相关系统。
原因非常简单,导购类的系统留给你足够的时间去做判断,它流量的上涨不是瞬间上涨,而是一个曲线慢慢上升,它留给你30分钟做出判断。但是
交易系统没有留出任何时间判断,一旦流量开始,没有给人反应时间,没有任何决策的时间,所有的行为只有系统会自动化执行。这个过程里面容量规划变的非常重要。
在早些年的时候,我们业务的自然增长本身就非常快。印象非常深刻的是,当时大家购物的时候打开的商品详情页面,有一段时间这个页面的负载比较高,公司召集了一些对于虚拟机调优、性能优化比较擅长的人来进行优化,调优了几天之后系统终于挂掉了。还好也在做一些扩容的准备,扩容完成,重启之后系统恢复了。这说明了什么?
在早些年的时候,淘宝网也是一样,对容量的准备和预估是没有概念的,不知道多少容量能支撑整个系统需要的能力。
新业务不断地上线,业务运营、促销类的活动也非常频繁,记得有一次做一个促销规模非常大。会员系统非常重要,因为所有的业务基本上都会访问会员中心用户的数据,包括买家的数据还有卖家的数据。那时物理机单机缓存的能力大概在每秒处理八万请求的规模,今天来看是远远不止。但当时还没有到高峰期的时候就达到了六万,这是非常大的一个数字。
我们就把所有访问会员的系统全部拉出来,看哪些与交易无关就通知需要停掉,或者停掉一半。比如把与商家相关的,与开放相关的,与社区相关的系统停掉。在这个过程里面发生了各种各样的问题,总结来说就是我们根本不知道容量怎么去做,或者说根本就没有概念需要去做容量。
所以容量规划归根结底就是:在什么时候什么样的系统需要多少服务器?需要给出有确定性,量化的数字。
容量规划整个过程大概经历了七八年的时间,总共三个阶段。
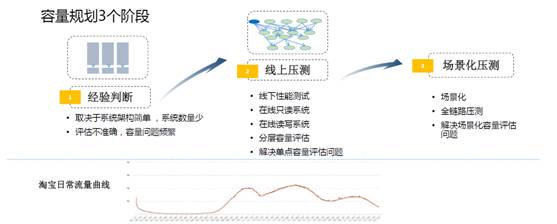
第一个阶段在非常早期,我们评估的方法就是「拍脑袋」(经验判断)。
根据负载的情况、系统的响应时间,各种各样的表现去拍一个数字出来。当时我问一个高管,到底怎么去判断服务器够还是不够,要支撑多少流量?他告诉我一个经验值,每台服务器支持100万的PV。
当时一天的流量曲线会有三个峰值,九点到十点,中午两、三点到五点,晚上八点到十点之间都是峰值。为什么是100万呢?这也是一个经验值,当然也有一点科学根据。我们希望做到一半的服务器停下来后能够去支撑线上的流量,同时在峰值的情况下,全部能够支撑住。实际上单机能支撑320万的PV,这是当时的经验值。
当然这个经验值当时是起作用的,原因非常简单,因为当时的系统架构简单。可以理解为把整个淘宝所有的逻辑和模块都集中在一个系统里面,所以各个模块之间的热点有时间差,通过一台服务器内部CPU的抢占或者调度在OS层面就解决了。
到了第二个阶段是线上压测阶段。
因为一旦到了分布式之后,就会出现问题。举个例子,本来是会员的调用和交易的调用在一台服务器上,但是分开之后,流量比例就不清楚了。所以必须要引入一些压测机制,我们引入一些商业的压测工具来做压测。
当时有两个目的:第一个是系统上线之前要做压测,判断响应时间、负载能否达到上线的要求;第二个目的是希望能够根据线下的压测情况,准确地评估出线上大概需要多少服务器。第二个目的做起来就比较困难一些,记得当时性能压测团队还做了一个项目,叫线下线上容量之间的关系。因为线上的环境和数据与线下完全不一样,这里面没有规律可寻,没办法通过线下压测的指标反馈到线上去。
这时候怎么办?首先是直接在线上压测。当时来看我们做这个决定是非常疯狂的,因为没有一家公司,包括阿里巴巴自己也没有人在线上直接做过压测。我们写了一个工具,拉取出前一天的日志直接在线上做回放。比如,根据响应时间和负载设定一个的预值,达到预值触发的时候看它QPS的多少值。
其次我们做了一个分流。因为阿里整个架构还是比较统一的,全部是基于一整套的中间件,所以通过软负载,通过调整配比,比如把线上的流量按照权重调整到一台服务器上,通过调整到应用端和服务端不断地调整到一台服务器上去,增加其权重,这时候它的负载也会上升,QPS也会上升,把这个过程记录下来。
这里已经是两种场景了,一种是模拟,回放日志。第二种是真实的流量,把做成自动化让它每天自动跑产生数据。这个事情做完之后,它从一个维度来说,替代了线下性能压测的过程。因为它可以让每个系统每天自己获得性能的表现情况。项目发布,或是日常需求的发布的性能有没有影响的指标都可以直接看出来。后来性能测试团队就解散了。
这里有个问题,它还没有基于场景化。场景化非常重要,比如我买一件衣服,平时买东西的流程可能是在购物的搜索框里面搜索,或者是在类目的导航里搜索,从搜索到购物车,再到下单这样的一个过程。双十一推的是商品的确定性,很多频道页面会把卖家比较好的促销商品直接拿出来作为一个频道页。双十二的时候推的是店铺,KPI不一样,推的东西也不一样。
双十一商品相关的服务器系统的流量会高,它所需要的服务器也会更多一些。双十二和店铺相关的系统服务器所需要也会更多一些。这与平时的流量表现是不一样的,用平时的容量去计算场景化流量,这也是不准确的。
我们也做了一件非常重要的事情:全链路压测。
这是我们在2013年完成的事情,之前从没有对外讲过,这是一个核武器,它有个分界线。2009年是最顺利的一次双十一,因为没有什么流量,我们忽略不计。2010年、2011年、2012年,其实每年的双十一总是有那么一些小问题,其实心里也没底。
在2013年的时候,我们做了全链路压测这个产品之后,发生了一个本质的变化。2013年的表现非常好,2014年也非常好,这就是一个核武器的诞生。对于做营销和促销类的,它是有峰值的,在这个时间点之前峰值非常低,这个时间点之后峰值突然上去了。这就是处理这种情况非常有效的一种方法。
重点分析一下线上压测和场景化的全链路压测。
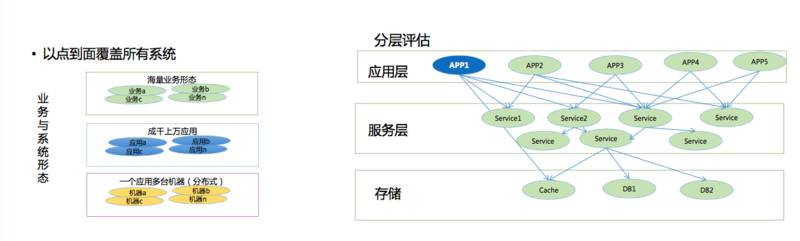
线上压测主要是由于淘宝的业务形态多样化。分布式之后各种各样的业务都出现了,它帮助解放了生产力。以前一百多个人在做一个系统,非常糟糕,但是通过分布式改造之后,整个业务服务抽象出来之后,生产力被解放了。
其次,每个业务的机器规模非常大,每个业务应用数量非常大。我们其实是做了一个分层,根据一个系统具备的容量不断计算,最后计算出来阿里巴巴的集群容量。我们先做一个应用系统,通过分流,流量通过负载导入,把负载跑到最高之后计算。把这个APP整个集群,比如100台服务器能支撑多少量计算出来。当然数据库非常难算,数据库都是提前规划的,一般来说数据库分库分表之后,都是留了好几年的量,比较困难一些。
通过这样把整个集群的量和规模全部做出来是有问题的,为什么呢?因为系统一旦开始拆分之后一发而不可收拾,拆得越来越多。系统的依赖关系虽然是有工具能够梳理出来的,但是我们没有经历看到底哪些系统会因为这个场景下面什么原因导致整个集群出现了一个小问题。一旦出现了一个小问题,整个集群全部崩溃掉,这种问题是没法避免的。
在2013年之前都是基于这套体系去做,想想也是挺合理的,每个系统算出容量,一个个集群算出来,再算出整个大集群也是可以的,但是它还不是一个非常好的解决方案。它非常好的一点是可以自动化运行,可以每天跑出系统的容量,并且可以保证系统不腐化,日常的性能、指标不腐化。
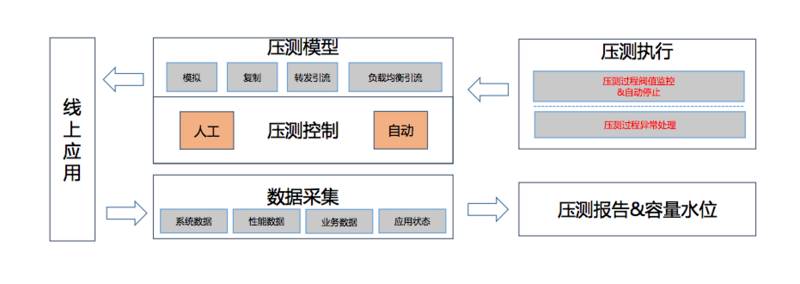
2013年的双十一是通过这套系统做的。通过几种方式,通过模拟以及流量的复制,转发的引流,还有负载均衡的流量去实现。整个系统做成自动化,每周都会跑,根据发布前后的一天跑出来数据之后生成一个报表反馈性能有没有下降可以得出。根据计算值准备整个活动流量大概要多少。这里有一些数据,每个月有5天自动做压测,这种情况下靠人工做性能压测是做不到的,因为它是自动化的。










