阿里妹导读:阿里巴巴9年双11经历下来,交易额增长了280倍、交易峰值增长800多倍、系统数呈现爆发式增长。系统在支撑双11过程中的复杂度和支撑难度以指数级形式上升。双11峰值的本质是用有限的成本最大化提升用户体验和集群吞吐能力,用合理的代价解决峰值。
面对增长如何发挥规模效应,持续降低单笔交易成本,提升峰值吞吐能力,为用户提供丝般顺滑的浏览和购物体验,这是极大的挑战。
今天,我们邀请了阿里巴巴资深技术专家叔同,分享九年双11的云化架构演进和升级。

叔同(丁宇),阿里巴巴资深技术专家,8次参与双11作战,阿里高可用架构、双11稳定性负责人,阿里容器、调度、集群管理、运维技术负责人。
叔同:大家好,我是叔同,很高兴与大家分享阿里双11的技术发展。今天我们先来关注一个问题:双11推动了阿里技术的进步,它有哪些挑战?
1、互联网级规模,每天有数亿人在阿里网站上进行交易;
2、企业级复杂度,每完成一笔交易都需要数百个系统的服务支撑;
3、金融级的稳定性,每一笔交易都必须保证其完整性和正确性;
4、双11存在数十倍的业务峰值,要求系统绝对稳定。
随着分布式架构、异地多活、限流降级、全链路压测等技术的突破,扩展性和稳定性问题得到了很好的解决。系统架构伴随9年双11的发展一代一代向后演进,每一年都有很大的提高。08年开始阿里巴巴着手系统由集中式架构变成分布可扩展架构,其中沉淀了大量互联网中间件技术。2013年通过异地多活的架构演进,把阿里完整的交易单元部署到全国各个城市站点,实现了地域级水平扩展。这两种技术的叠加解决了整个双11扩展性问题。
由于分布式架构的演进,系统稳定性问题开始凸显、系统复杂度急剧上升、多个系统间协同出现问题。我们建设了限流降级、预案体系、线上管理管控体系。在2013年时做了双11备战的核心武器——全链路压测。它能对整个系统的依赖关系里跟双11有关的部分进行完整的用户级的线上大流量真实场景读写压测,使系统提前经历几次“双11”,验证整个线上生产环境处理能力,及时发现问题并修复。
目前这些技术已经成为互联网行业的标配技术。
云化架构的演进
由于双11本身峰值增长很快,当我们做好了系统的稳定性后,发现硬件、时间、人力成本的消耗很大。成本挑战的出现推动我们解决IT成本的问题,即服务器资源问题。首先来看云化架构演进背景。

上图为阿里业务六个月的峰值数据表。表中两个最大的峰值依次代表双11和双12的交易峰值,其他较小的峰值是日常交易峰值,红线代表日常准备系统服务器资源的处理能力。
在13年之前,我们采购大量的服务器资源以支撑双11流量高峰。高峰过去后,长时间低效运行产生很大的资源浪费,这是非常粗放的预算和资源管理模式。阿里的多种业务形态产生了多种集群,每个集群之间运维体系差异较大、各个板块无法互用、资源整体弹性能力不足导致双11无法借用这些资源。每个板块的资源池有不同的buffer,每个资源池的在线率、分配率和利用率无法统一。我们通过云化架构提高整体技术效率和全局资源的弹性复用能力。例如某个不做双11的集群把资源贡献出来给双11的交易使用。由于云能提供双11正需要的弹性能力,所以我们也开始大量使用阿里来解决双11成本问题,通过拉通技术体系来降低大促和日常整体成本,提出通过云化架构来实现双11单笔交易成本减半的目标。
先来梳理一下整个运维体系现状。我们将集群大致分在线服务集群、计算任务集群、ECS集群三类。这三种集群上的资源管理和基础运维、调度都是独立的。它们有各自的调度编排能力,在线服务Sigma调度、计算任务的Fuxi调度、ECS的Cloud Open API;它们在生产资源、资源供给、分配方式上也是不同的。在线服务用的是容器、计算任务调度最后生产的是LXC的轻量级隔离封装容器、云生产的是ECS;它们在应用层上运维集群管理也是不一样的,最上层业务层跑的任务也不一样。在线服务器跑的是在线业务如交易搜索广告、有状态的存储。计算集群跑的是大数据分析的任务,云集群跑的是各式各样的外部客户的任务。
通过技术全面云化逐层进行重构升级,建设弹性复用的能力实现全局统一调度。在线任务和计算任务混合部署,通过统一运维部署和资源分配的标准化提高调度效率,以此来实现容量的自动交付。所以我们需要做全面容器化,利用公有云,发挥云的弹性能力,减少自采基础设施的投入。通过混合云弹性架构和一键建站复用阿里云的能力,降低双11的成本,利用阿里云做到以前一年的资源持有时间缩减到只需1-2个月。
统一调度体系
始于2011年建设的Sigma是服务阿里巴巴在线业务的调度系统,围绕Sigma有一整套以调度为中心的集群管理体系。

Sigma是有Alikenel、SigmaSlave、SigmaMaster三层大脑联动合作,Alikenel部署在每一台NC上,对内核进行增强,在资源分配、时间片分配上进行灵活的按优先级和策略调整,对任务的时延,任务时间片的抢占、不合理抢占的驱逐都能通过上层的规则配置自行决策。SigmaSlave可以在本机上进行CPU的分配、应急场景的处理。通过本机Slave对时延敏感任务快速做出决策和响应,避免因全局决策处理时间长带来的业务损失。SigmaMaster是一个最强的大脑,它可以统揽全局,为大量物理机的容器部署进行资源调度分配和算法优化决策。
整个架构是面向终态的设计理念,请求进来后把数据存储到持久化存储,调度器识别调度需求分配资源。系统整体的协调性和最终一致性是非常好的。我们在2011年开始做调度系统,2016年用Go语言重写,2017年兼容了kubernetes API,希望和开源社区共同建设和发展。
发挥统一调度,集中管理的优势,释放了规模效益下的一些红利。在线服务的调度和计算任务调度下有各种业务形态,它们在一层调度上进一步细分成二层调度,通过合并资源池提升利用率和分配率,合并buffer进行空间维度的优化实现全局打通。全局打通后进行弹性分时复用、时间维度的优化,共节省超过5%的资源。由于基数大,这个优化效果是非常可观的。

阿里巴巴在2014年开始推动混部架构,目前已在阿里巴巴内部大规模部署。在线服务属于长生命周期、规则策略复杂性高、时延敏感类任务。而计算任务生命周期短、调度要求大并发高吞吐、任务有不同的优先级、对时延不敏感。基于这两种调度的本质诉求的不同,所以我们在混合部署的架构上把两种调度并行处理,即一台NC物理机上可以既有Sigma调度又有Fuxi调度。Sigma调度是通过SigmaAgent调用OCI标准的RunC 、RunV、 RunLXC 三种标准来启动Pouch容器。Fuxi也在这台NC物理机上抢占资源,启动自己的计算任务。所有在线任务都在Pouch容器上,它负责把服务器资源进行分配切割通过调度把在线任务放进去,离线任务填入其空白区,保证物理机资源利用达到饱和,这样就完成了两种任务的混合部署。
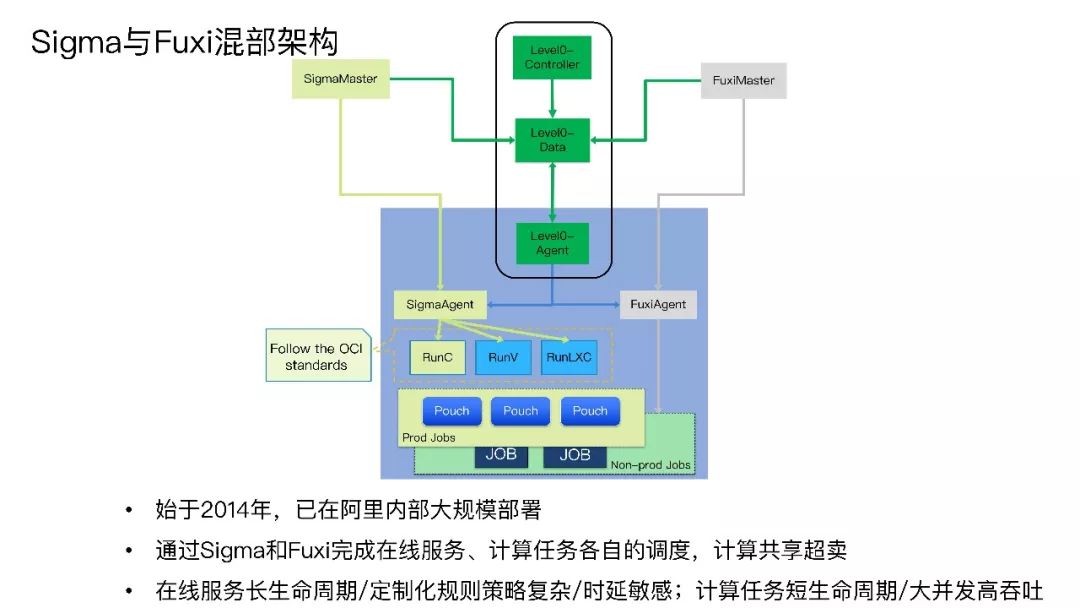
混部的关键技术
内核资源隔离上的关键技术









