
2012 年,正在哈佛大学写硕士论文的 Todd Mostak 需要查询大量的论文参考资料,他发现使用以 CPU 为处理核心的数据库系统做资料查询速度非常缓慢。而且很多时候,Todd Mostak 在睡觉之前输入一个查询命令,第二天醒来发现系统提示参数输入错误。
当时 Todd Mostak 选修了由 MIT 数据库研发组教授的 CSAIL 数据库课程,为了加快论文进度,Todd Mostak 通过自己在 CSAIL 数据库课程中学到的知识开发了一个简易的数据库系统,该数据库是通过使用廉价的、为游戏玩家使用的 GPU 来建立的,然而这一数据库却大大加快了 Todd Mostak 的资料查询速度。
与 Todd Mostak 在哈佛查询资料时一样,金融行业的很多老数据库系统在当今也遇到了查询速度慢等问题,特别是在高并发状态的查询环境下。
这时候,越来越多的金融企业对数据的高速查询和快速加工有了更高的要求。
银行的痛点:数据加工与查询
业内人士透露,一个省级银行的客户经理就高达三万多人,如果这三万多人每天同时去做了解客户信息这件事,任何数据库都难以承载,而过去被广泛使用的 IBM 小型机根本无法解决。与此同时,成本也是非常大的问题。虽然目前市场上 Teradata 的产品在数据查询和数据加工效果方面表现优秀,但价格相对较为昂贵。
除此之外,及时掌握风险的能力也非常重要。银行本身对风控要求极高,过去在风控方面均为事后监督,也就是 T+1:今天交易完成,第二天再检查前一天的问题。而当下的交易必须要求做到 T+0,交易的同时也可检查风险。
这时候如果没有一个高效的数据库,很难解决上述问题。
在面对这一痛点,雷锋网采访了雅捷信息董事长郑学强、首席数据科学家谢军、NVIDIA 全球副总裁沈威以及 IBM 大中华区硬件系统部服务器解决方案副总裁施东峰,询问相关问题。
GPU 数据库的优势,与 CPU 数据库的劣势
雅捷信息是国内少有采用上文中提到的哈佛学生 Todd Mostak 在 GPU 上做数据库的公司,其主要产品是性能并行计算数据库产品和银行信息化系统及智能服务。
一般来说,GPU 是专为并行计算而设计的专用协处理器,通常其内部都集成了数千个高速运算核心。由于 GPU 通常都可以直接搭配高带宽存储器协同工作,因此比使用一般 RAM 的 CPU 运算速度快出一个数量级。
目前虽然一些企业和机构的数据库已经使用了 GPU,但普遍存在一个设计缺陷:其数据库管理方案都是将数据库存储在 CPU 一侧,当接到用户的数据请求时,将数据搬移到 GPU 一侧进行处理,然后再把处理结果移回至 CPU 进行存储。也就是说,GPU 并非真正的系统核心。这种机制决定了即使通过 GPU 加快数据处理速度,但把处理结果搬回 CPU 的过程仍然浪费了大量时间。
如果没有像传统系统那样将数据全部存储在 CPU 一侧,而是将 GPU 作为真正的核心,利用高速缓存机制将尽量多的数据直接存储在多内核协同工作的 GPU 一侧,这样做的结果就可避免数据搬移过程中耗费的时间,提升了运算效率。
虽然已有相应的解决方案去加快 GPU 与 CPU 之间的信息流通,但仍旧存在延时等问题。
目前比较前沿的加速 CPU 与 GPU 信息交方案是 IBM 与 NVIDIA 联合研制的 NVlink 信息交换通道。我们知道,GPU 和 CPU 间的数据传输速度都是一项技术瓶颈,因为 GPU 的显存能够快速而少量的读写数据,而 CPU 使用内存读写则大量而慢速,因此,CPU 的传输带宽大于 GPU。NVlink 通过调整相应架构,使得 GPU 和 CPU 间的传输速度获得巨大的提升。

其实 IBM 早在几年前便注意到了这种趋势,随后它们与 NVIDIA 合作,去加快新数据中心工作负载的处理速度。经过四年的研发,POWER8 服务器联合了 NVIDIA 的 Tesla P100 GPU 和 NVlink 互联技术,实现了更高的数据性能分析和深度学习能力提升。据测试资料显示:IBM 和 NVIDIA 技术如此紧密的结合使得数据流动速度比使用 PCIE 快了 5 倍。
NVlink 除了可实现 GPU-CPU 节点内部的高速互联,同时还能在 GPU-GPU 甚至 CPU-CPU 之间形成高速互联。
雅捷信息首席数据官谢军向雷锋网 (公众号:雷锋网) 透露,由于他们服务的客户通常是大中型银行,对计算量要求巨大,因此雅捷信息的新品 DataTurbines 背后采用的是 GPU 集群,这个时候集群中 GPU 与 GPU 之间的高速互联就非常关键。当然,雅捷信息的数据库也并非完全在 GPU 中处理,也有一小部分会放在 CPU 中,具体会根据客户的成本以及数据量等问题来灵活安排。
为了让 GPU 集群以及 CPU-GPU 之间通信顺畅,雅捷信息选择与 IBM 进行深入合作。IBM 大中华区硬件系统部服务器解决方案副总裁施东峰向雷锋网介绍到,与雅捷信息的合作主要体现在两方面,在技术层面 IBM 为雅捷信息的 GPU 数据库提供 GPU-GPU 以及 GPU-CPU 的 NVlink 通道机器 Minsky。在市场方面,IBM 借助雅捷信息的银行客户,向银行推广包含 GPU 数据库的一体机。
这个一体机本质上是 IBM 提供的认知计算平台,其中 GPU 数据库也归类在认知计算平台中。施东峰继续讲到:IBM 接触的银行客户有两种,一种是对方只要打包好的、直接能够使用的产品,他们只需知道这个引擎如何使用即可,另外一种客户则要是想要自己买机器、做数据库、做算法,自己搭建人工智能引擎。
IBM 主要服务于前者,以一体机的形态把相关的人工智能技术以及 GPU 数据库进行整合,从而做成企业级直接使用的、没有很多指令集、直接连接的产品。
GPU 数据库商业化应用案例
目前从公开资料显示,已有 GPU 数据库产品在海外市场使用,如 Kinetica、BlazingDB 等。其中最具代表性的就是文章开头提到的哈佛学生 Todd Mostak,他已成立了公司运营相关商业化产品 MapD。在 MapD 系统中,每个 GPU 都有自己的缓冲池,利用高速缓存机制将最常访问的数据直接存储在 GPU 一侧,在数据库需要反复查询同一个数据点时,MapD 就可以直接从 GPU 一侧的高带宽存储器中直接访问数据,而不是从 CPU 或硬盘。
通过这种机制,MapD 可以提供相比传统数据库管理系统快两到三个数量级的性能。
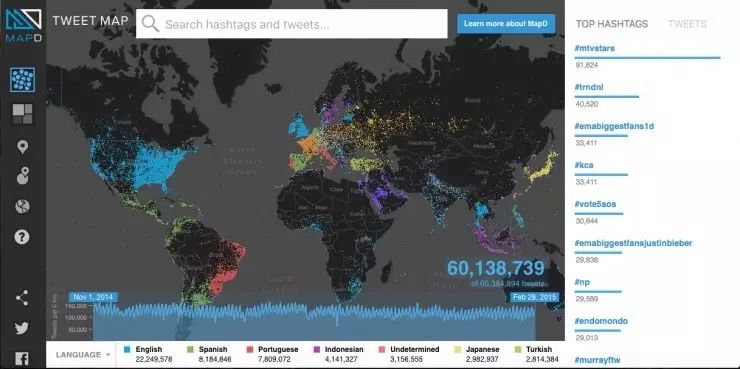
总体上说,不同行业的客户对 MapD 系统的具体需求也不同,但本质都是通过其高速的数据处理能力协助他们做出合理的商业决策。如金融服务机构和对冲基金可以通过该系统来监控欺诈行为和做出投资决策;广告代理商们可以通过该系统来评估客户们对各种广告的不同反馈; 社交媒体公司则可以通过该系统追踪全球用户的使用情况。
美国电信巨头 Verizon 也是 MapD 的客户之一,他们每周都会利用 MapD 系统对 8500 万用户更换 SIM 卡的行为展开分析。
此前在使用传统的数据库管理系统时,这种分析通常要耗费好几个小时,因为效率太低,因此只能好几个月分析一次。近期,Verizon 通过 MapD 系统的每周分析报告发现了一个隐藏多年的 Bug,这一 Bug 每年导致上百万次无意义的 SIM 卡更换,不但浪费了服务资源,而且对用户体验影像极大。
GPU 数据库在银行中的应用
相比于 MapD 而言,国内的雅捷信息在可视化数据库方面没有前者出色,覆盖的业务范围也没有前者广,但后者业务更加集中在银行领域。虽然当下银行逐渐变得愈加开放,不会拒绝新产品和新技术,但有个前提是他们对第三方的产品要求极其严格,银行如果想要采购方案会经过以下几个流程:沟通、PUC 测试,最后招投标,然后让供应商的产品进入它的银行体系。
银行的信息安全是最高等级的,如果没有一把手签字,信息完全拿不出去。一般情况下,产品先到银行进行测试,然后供应商需要经过五道审批手续才能把系统送进去,入库上架后银行方把数据脱敏以后才让供应商使用。
因此与银行合作,相比于绝大多数行业来说,难度大不少。
雅捷信息董事长郑学强向雷锋网透露:银行的夜间加工只有八个小时,超过八个小时就面临第二天无法开门的情况,如果第二天开不了门,银监会对其的处罚非常严重。
郑学强跟 IBM 的相关负责人交流时产生了一个观点,在 GPU 上并不能放到上千 T,甚至 PB 级的数据。在 GPU 上真正需要解决的是客户所要用的数据和热点数据,而非在千 T、PB 级的数据里进行数据查询。方案商应该去形成一个个的小数据仓库(Data mart),这时分布式的 GPU 数据库应该为热点数据服务,而不简单地提供储存功能。
MemSQL 的首席技术官兼联合创始人尼基塔 · 沙姆古诺夫 (Nikita Shamgunov) 也曾指出 GPU 为某些工作负载提供了优势,它可以分解成许多小的操作单位,每一个小小的操作单位可以同时在大批核心上加以执行。
关于产品的适用性问题上,郑学强举了一个省级农商行的商业化案例。省级农商行的规模相当于一个股份制银行,存贷款规模过万亿,每天的日交易比数可以达到两千万笔。在一个 6000 万客户的银行,以往 2 小时的跑批任务,如今采用 GPU 数据库产品可在 1 分钟内完成,原先 5 分钟的查询,现在不到一秒。在几万名客户经理天天使用的场景下,一千个并发可以达到毫秒级的响应,绝大部分的复杂查询实测效果平均响应时间 200 毫秒,其中 DB2 提速 400 倍左右,Hadoop 提升 200 倍,在 Hadoop 上对比的节点是 46 个节点。
除此之外,雅捷在与招商银行、中兴银行合作期间解决了信用卡业务的一些问题,如双十一期间用户用信用卡在网购上同时支付,这对系统的压力非常大,所以说它需要有一个高速的平台,来给它做分解。
GPU 之后,FPGA 数据库是否会成为未来?
通过案例了解到,目前已有不少公司把数据库从 CPU 转换到 GPU 中,那么未来是否会从 GPU 转向 FPGA 中?雷锋网提出这样一个疑问,既然银行要求高速度、低延迟,这时候速度快、低延迟、低功耗的 FPGA 似乎比 GPU 更加匹配,而且 FPGA 正逐渐开始被各大公司广泛使用。
针对这一问题,雅捷信息董事长郑学强说到虽然 FPGA 低能耗、体积小、效率高的特性使得它确实有一定的优势,但 FPGA 的一大局限性就在于内存较小,因为数据需要一定的物理空间进行存储。另外,雅捷信息也一直准备尝试 FPGA,但最终没做的原因是现在高性能计算芯片中,GPU 代表新一代主流的技术,抛弃主流技术和产品去尝试另外一种技术,相对的试错成本会比较高。
随后,雅捷信息首席数据科学家谢军补充道:并行计算有很多种架构,如 GPU、FPGA 等等,一个公司选择某个方向有它的深思熟虑。雅捷信息之所以选 NVIDIA 的 GPU,非常核心的价值在于 GPU 拥有运算平台 CUDA。开发一个方案仅仅靠硬件是不够的,要有好的架构才能做到。正如很多公司当年选 Windows 系统一样,如果没有易用的、通用的操作系统,所进展的每一步都很难。所以 NVIDIA 的价值并不仅仅在于它的晶体管集成技术,还有 CUDA 这样的运算系统。
针对 GPU 和 FPGA 这一问题,雷锋网也采访了 NVIDIA 全球副总裁沈威,沈威说道:以谷歌为例,谷歌的 Alphago 最开始用 TPU 部署,当时的 TPU 也就是 FPGA,而现在谷歌的 TPU 用的是 ASIC。这里可以看出谷歌当时采用 FPGA 更多是为了尝试,当他确定要增加数量时则把 TPU 的核心变成了 ASIC,这背后就能说明一些问题。
06 年很多人开始考虑 GPU 游戏的计算能力,但是人们没办法使用它,于是 NVIDIA 开发了 CUDA,从而解放了 GPU 的运算能力。在 CUDA 的架构上可以用比较常见的 Java 或 C++ 进行编程,而在 FPGA 上则是用 Verilog 或 VHDL 语言,所以 GPU 在普及性上会有非常大的优势。与此同时,NVIDIA 有共通的平台使得其于通用的服务器或者 CPU 服务器连接在一起,而 NVIDIA 当下的一大任务是让 CUDA 的架构不断去与传统行业的 IT 业务接轨。
总结
关于使用 GPU 相比 CPU 的数据库总体成本 / 效益仍的争论一直存在,由于大多数软件无需用到 GPU 所达到那种并行化程度,也无法用 GPU 有限的指令集来处理,使得 GPU 在很多方面不适合工作负载。而在跨集群根据不同的键对数据重新分区,这些操作在 CPU 上却来得非常高效。
与此同时,英特尔等公司在以低成本封装 CPU 能力方面非常高效,相比 GPU 而言,CPU 往往成本更低。
但对于银行、政府等这种速度第一、价格第二的机构来讲,价格高昂但效果显著的 GPU 数据库在未来或许会成为一大趋势。










